Masks
All of the Cognex VisionPro Deep Learning Tools support the ability to exclude parts of the image from training by creating and applying masks.
During training and processing, the Deep Learning tools work by sampling the image, with the Feature Size being the nominal span of the Sampling Region, in pixels. During sampling, a significant amount of context information (aka the Context Region) from around the Sample Region is also considered.
|
|
|
|
1 |
Feature Size |
|
2 |
Sampling Region |
|
3 |
Context Region |
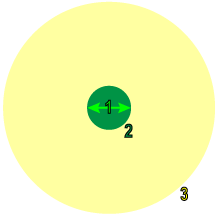
When a mask is applied to an image, the pixels within the Sampling Region that are masked are always discarded. However, how the mask is applied to the Context Region is determined by the Masking Mode parameter.
Consider the following masked image, with the hypothetical Sampling and Context Regions:

When the Masking Mode parameter is set to the default setting of Transparent, samples are only collected within the unmasked parts of the image. However, context information is still collected from masked areas, signified by the bright green areas within the Context Region.
![]()
When the Masking Mode parameter is set to Mask, any masked pixels within the Context Region are discarded, signified by the bright red areas within the Context Region. This setting also effectively focuses the tool to emphasize the center of the ROI during sampling.
