统计
VisionPro Deep Learning 内的统计测量用于验证训练后的神经网络的性能。在深度学习范例中,验证是指根据测试数据(由用户标注,但未用于训练的数据)评估经过训练的神经网络模型的过程。因此,如果您想通过统计指标来确定神经网络模型的可用性和性能,则必须仅根据测试数据计算这些指标。
重要的是要明白,在训练你的神经网络模型后(指您的工具,即蓝色定位/读取、绿色分类或红色分析),如果您想检查模型是如何训练好的,不允许您根据用于训练此模型的数据测试模型。训练数据不能用于评估训练模型,因为模型在训练期间已经拟合到该数据,以在给定训练数据集的情况下发挥最佳性能。因此,这些数据无法说明模型泛化的程度,也不能说明在遇到看不见的新数据时也能很好地执行。
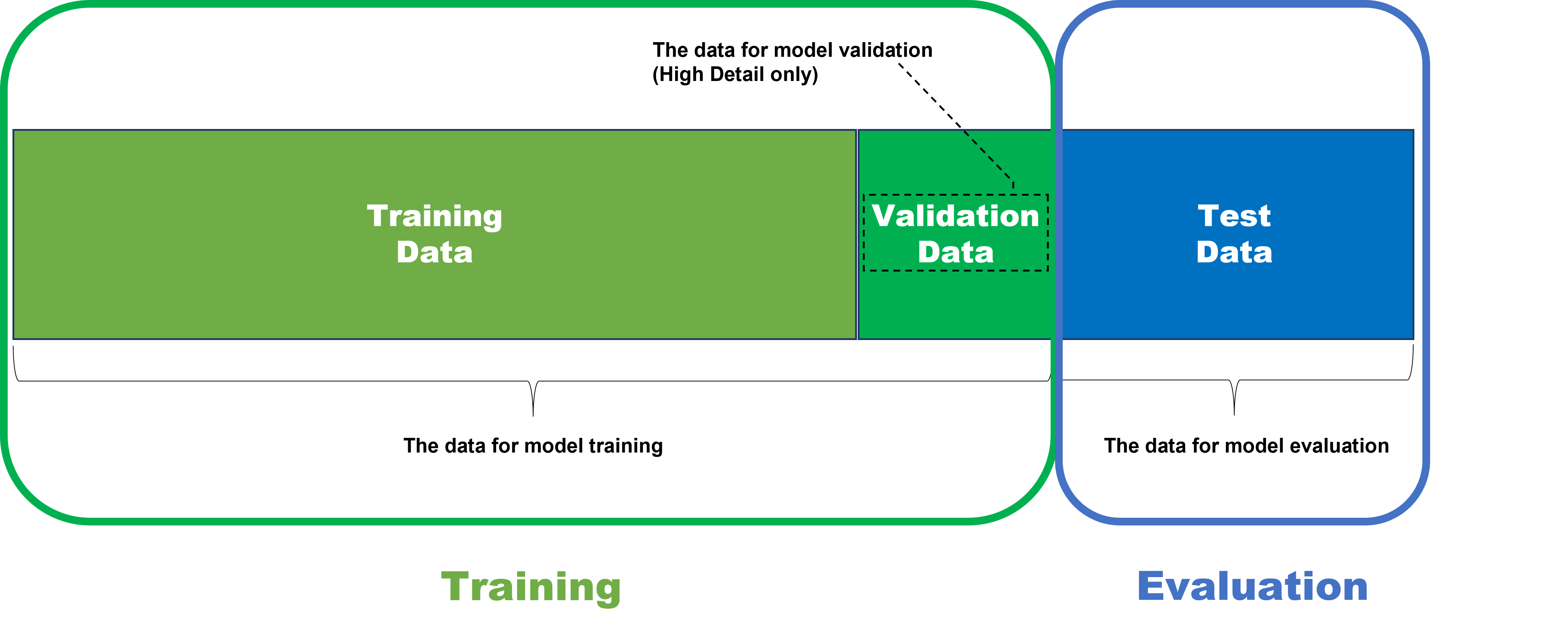
因此,为了公平正确地测试模型的可用性和性能,模型应该应用于它之前从未见过的数据,包括其训练阶段。这就是为什么模型评估的数据被称为测试数据集。
请注意,测试数据集不在训练范围内,而验证数据集包含在训练阶段。验证数据是训练集的一部分,其目的是在从训练数据生成的许多模型中选择最佳模型作为训练的最终输出。对于高细节模式,在训练阶段为每个模型计算验证损失(=从验证数据计算的损失),最终选择在性能和可用性方面给出最佳损失的模型作为训练结果。同样,验证数据仅用于绿色分类和红色分析高细节模式。具有其他操作模式的工具不使用验证数据,因此它们选择具有从训练数据计算出的损失的最佳模型。
VisionPro Deep Learning中每个工具的统计指标的使用有助于限定以下内容:
- 估计未来的表现,例如估计假正值率。
- 通过找到良好的参数组合或设置各种阈值来优化工具参数。
- 测试模型结果的再现性。
本节中的主题将帮助您了解 Cognex Deep Learning 工具输出的指标:
- 得分直方图
- 受试者操作特征 (ROC) 曲线和曲线下面积 (AUC)
- 混淆矩阵
- 精确度、精度、召回和 F-得分
不能依据以下任何一项来评估基于深度学习的神经网络模型的性能:
- 神经网络模型的质量“等级”
- 神经网络的质量没有等级。
- 作为神经网络模型输出的“得分”
- 神经网络有几个指标,可以从几个不同的角度展示其性能,但没有一个值可以绝对代表神经网络的适用性和性能。