NVIDIA GPU 选择和配置
电脑系统配置选择直接影响工具处理速度,但不影响工具精度或行为,这是最昂贵,并且最难预测效果的部分。
| 配置选项 | 为什么更快 | 最有价值选项 | 注意... |
|---|---|---|---|
|
NVIDIA 设备类型 |
CUDA 核的数量与高精度处理速度和训练直接相关。 标准 Tensor 核的数量与处理速度和训练速度直接相关。 Tensor 核的数量仅与低精度模式下的处理速度有关。这些核不会影响标准精度处理或训练速度。 |
||
|
NVIDIA 驱动程序模式 |
面向消费级游戏的 NVIDIA 设备仅支持 WDDM 设备驱动程序模型。此驱动程序用于支持图形显示,而不是计算。 专业级 NVIDIA 显卡支持 TCC 驱动模式,可提供更好的性能和稳定性。 |
选择 NVIDIA RTX / Quadro® 或 Tesla(或选定的 Titan)品牌的 NVIDIA 卡。 |
如果使用 GeForce 品牌显卡,请注意 NVIDIA 驱动程序经常更新,可能与 Deep Learning 不兼容。 使用 TCC 模式驱动程序可以避免 GPU 卡用于视频输出,而是使用板载视频。 |
|
优化内存 |
通过覆盖标准 NVIDA GPU 内存管理系统,默认情况下启用的 Deep Learning 优化内存可以提高性能。 |
确保卡至少有 4GB 的 GPU 内存。 使用 TCC 驱动程序的显卡的性能提升不显著。 |
|
NVIDIA 设备品牌总结
下表总结了不同的 NVIDIA 设备类型:
| 类 | 消费者 | 专业 | ||
|---|---|---|---|---|
|
家用 |
低端游戏 |
高端游戏 |
工作站 |
数据中心 |
|
品牌 |
GeForce |
Titan |
NVIDIA RTX / Quadro® |
Tesla |
|
Volta 架构卡 |
无 |
Titan V |
GV100 |
V100 |
|
Pascal 架构卡 |
GTX 1xxx |
Titan Xp |
G/GPxxx |
P100 |
|
Turing 架构卡 |
RTX 2xxx |
Titan RTX |
Quadro RTX4xxx |
T4 |
| Ampere 架构卡 | RTX 3xxx |
Titan RTX 2nd Gen。 (尚未发布) |
Axxx | Axxx |
|
视频输出 |
是 |
是 |
是 |
否 |
|
价格点 |
~1000 美元 |
~3000 美元 |
~5000 美元 |
5000 美元以上 |
|
支持 TCC 驱动程序 |
否 |
是 |
是 |
是 |
|
ECC 内存 |
否 |
否 |
是 |
是 |
|
Tensor Cores |
|
|
|
|
NVIDIA GPU 术语表
| 条款 |
定义 |
重要性 |
|---|---|---|
|
CUDA 核心 |
标准的 NVIDIA 并行处理单元。 |
是。CUDA 核心数量是 NVIDIA GPU 处理的标准量度。CUDA 核心越多,VisionPro Deep Learning 处理和训练越快。 |
|
ECC 内存 |
纠错码 (ECC) 内存涉及硬件支持,用于验证内存读/写不包含错误。 |
否。由于在训练和处理神经网络涉及大量计算,因此影响工具结果的内存错误的可能性非常低。 |
|
TCC |
特斯拉计算集群 (TCC) 驱动程序模式 高性能驱动程序,针对 NVIDIA GPU 的计算应用进行了优化。 TCC 注意事项:
|
是。只要有可能,就应该选择支持 TCC 驱动程序模式的显卡,并应将其启用。 |
|
Tensor Core |
全精度、混合精度(最终整数数学)并行处理单元,专用于矩阵乘法运算。 |
是。在版本 VisionPro Deep Learning 3.2.0 VisionPro Deep Learning中引入,只要用户拥有标准或高级许可证,就可以自动利用 Tensor Cores 进行更快的处理和训练。 |
|
Tensor RT |
NVIDIA 框架,用于通过使用低精度和整数数学优化 TensorFlow、Caffe和其他标准框架网络的运行时性能,这些网络运行在具有 Tensor Core 的 GPU 上。 |
否。VisionPro Deep Learning 使用与 Tensor RT 不兼容的专有网络架构。 |
GPU 分配
高细节模式之间的 GPU 资源分配逻辑有细微但重要的区别。为方便本页进一步说明,此处的高细节模式和聚焦模式均包含以下工具。在高细节模式系列中包含高细节快速模式的该定义仅适用于此文档中的此页面。
高细节模式
-
红色分析高细节
-
绿色分类高细节
-
绿色分类高细节快速
聚焦模式
-
红色分析聚焦监督
-
红色分析聚焦无监督
-
蓝色读取
-
蓝色定位
-
绿色分类聚焦
高细节模式
对于高细节模式工具,将基于工具锁定 GPU 资源:
-
训练 1 个工具(工具中要训练的所有图像)单独占用 1 个 GPU
-
处理 1 个工具(工具中要处理的所有图像)单独占用 1 个 GPU
这意味着当高细节模式工具占用 GPU 设备进行训练或处理时,此 GPU 被锁定,以便在高细节模式工具完成训练或处理作业之前,任何其他工具都无法使用它。
如果有 N 个高细节模式工具和 1 个 GPU,这 N 个高细节模式工具将按顺序占用这 1 个 GPU(先进先出)。当一个工具占用此 GPU 用于训练或处理作业后,所有其他工具将在队列中等待,直到正在运行的作业完成为止。如果执行新的训练或处理作业,此作业将被添加到队列的末尾。
高细节模式的工具链
对于高细节模式的工具链,上述 GPU 分配原则同样适用,只是始终先训练父工具(上游工具),然后再训练子工具(下游工具)。在子工具中,按原样应用上述原则。
例如,当有 1 个父工具和 2 个子工具时,此工具链的训练是按顺序完成的。始终应该先训练父工具。
使用 1 个 GPU 训练高细节模式的工具链
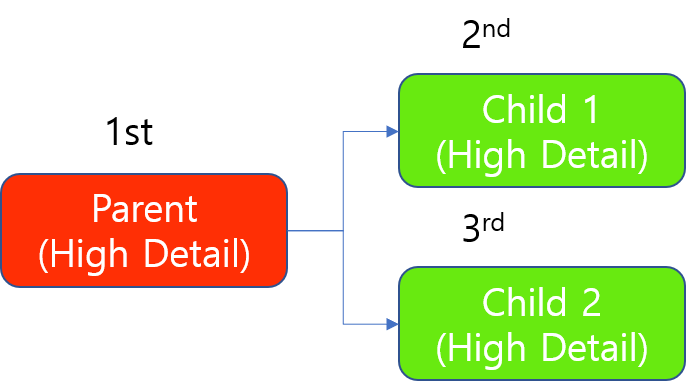
在处理时,始终应该先处理父工具,并且由于高细节工具的处理“基于工具”占用 GPU,因此在有一个 GPU 资源时先处理 1 个子工具。处理完这个子工具(这个子工具中要处理的所有图像)之后再处理其他子工具。
使用 1 个 GPU 处理高细节模式的工具链(与训练相同)
聚焦模式
对于聚焦模式工具,用于训练作业时基于工具锁定 GPU 资源,但在用于处理作业时基于图像锁定 GPU 资源:
-
训练 1 个工具(工具中要训练的所有图像)单独占用 1 个 GPU
-
处理 1 个图像(任何工具中要处理的单个图像)单独占用 1 个 GPU
这意味着当聚焦模式工具占用 GPU 设备进行训练时,此 GPU 被锁定,以便在聚焦模式工具完成训练作业之前,任何其他工具都无法使用它。
如果有 N 个聚焦模式工具和 1 个 GPU,这 N 个聚焦模式工具按顺序(仍是先进先出)占用这 1 个 GPU。当一个工具占用此 GPU 用于训练作业后,所有其他工具将在队列中等待,直到正在运行的作业完成为止。如果执行新的训练作业,此作业将被添加到队列的末尾。
但是,当聚焦模式工具占用 GPU 设备进行处理时,此 GPU 将被锁定,直到它完成图像处理为止。此 GPU 在完成图像处理(这通常只需要很少的时间)后,可以立即被任何其他工具(主要是一直在队列中等待的工具)占用。
如果有 N 个要处理的聚焦模式工具,处理聚焦模式工具时还要使用 FIFO 队列,以便在某个工具占用此 GPU 处理作业时,所有其他工具都在队列中等待,直到完成图像处理为止。但是,由于图像的处理时间通常很短,这 N 个聚焦模式工具将轮流占用此 GPU。
-
如果执行一个新的训练作业,此作业将被添加到 FIFO 队列中,并且很快或稍后可能会占用 GPU 资源很长时间,直到其所有图像的训练作业完成为止。
-
如果执行一个新的处理作业,此作业将被添加到 FIFO 队列,并且可能只占用 GPU 资源一段时间,直到处理完此工具的图像为止。然后释放此 GPU,并再次占用此 GPU 或其他 GPU 来处理此工具的其他图像(其他处理作业)。重复此操作,直到处理完属于此工具的所有图像为止。
聚焦模式的工具链
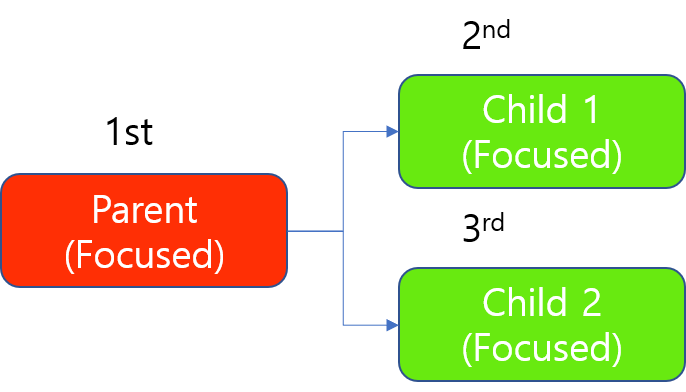
对于聚焦模式的工具链,上述 GPU 分配原则同样适用,只是始终先训练父工具(上游工具),然后再训练子工具(下游工具)。在子工具中,按原样应用上述原则。
例如,当有 1 个父工具和 2 个子工具时,此工具链的训练是按顺序完成的。始终应该先训练父工具。
使用 1 个 GPU 训练聚焦模式的工具链
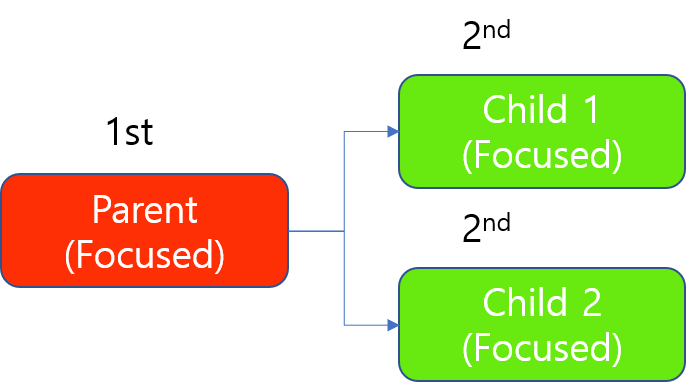
处理时,始终应该先处理父工具,但是由于处理聚焦工具时“基于图像”占用 GPU,因此即使使用单个 GPU,也可以同时处理 2 个子工具,因为此 GPU 在处理完来自 2 个子工具之一的图像时释放锁定。
使用 1 个 GPU 处理聚焦模式的工具链
(2 个子工具轮流占用 1 个 GPU,因为处理聚焦模式工具时占用一个 GPU 来处理 1 个图像,而不是处理此工具中要处理的所有图像):
分配优先级
-
高细节模式 > 聚焦模式
当流同时具有高细节模式和聚焦模式工具时,与聚焦模式相比,高细节模式具有处理优先权,因此高细节工具在聚焦模式之前锁定 GPU。然后,聚焦模式工具会尝试占用未被高细节工具锁定的 GPU。