解释结果
经过训练和处理后,系统会针对所有视图计算工具的结果。但是,只应在测试集上检查结果,才能对工具进行正确的评估。
测试集:用于评估结果的图像
VisionPro Deep Learning 内的统计测量用于验证训练后的神经网络的性能。在深度学习范例中,验证是指根据测试数据(由用户标注,但未用于训练的数据)评估经过训练的神经网络模型的过程。因此,如果您想通过统计指标来确定神经网络模型的可用性和性能,则必须仅根据测试数据计算这些指标。
重要的是要明白,在训练你的神经网络模型后(指您的工具,即蓝色定位/读取、绿色分类或红色分析),如果您想检查模型是如何训练好的,不允许您根据用于训练此模型的数据测试模型。训练数据不能用于评估训练模型,因为模型在训练期间已经拟合到该数据,以在给定训练数据集的情况下发挥最佳性能。因此,这些数据无法说明模型泛化的程度,也不能说明在遇到看不见的新数据时也能很好地执行。
因此,为了公平正确地测试模型的可用性和性能,模型应该应用于它之前从未见过的数据,包括其训练阶段。这就是为什么模型评估的数据被称为测试数据集。
数据库概述
“数据库概述”窗格提供有关用于训练的图像和视图的信息,以及对 Cognex 深度学习工具的统计输出的访问。此窗格将根据所选工具更改其显示。
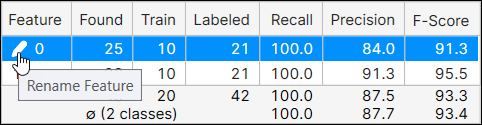
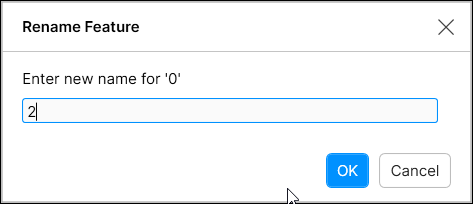
可以单击名称并按下铅笔图标以启动“重命名特征”对话框,然后对特征进行重命名。
在专家模式下,您可以使用筛选条件字段分隔图像/视图,并仅对这些图像/视图执行统计分析。有关筛选图像/视图的语法信息,请参阅显示筛选条件和筛选条件;有关筛选条件的可能用途的更多信息,请参阅测试图像样本集主题。
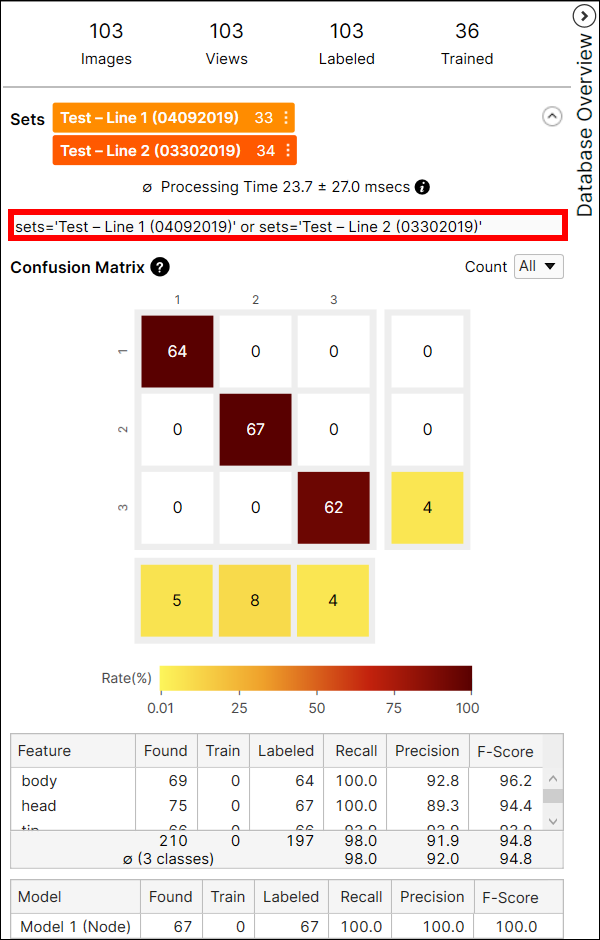
处理时间
单独工具处理时间在数据库概述中显示,如下所示:
处理时间是上一个处理任务中每个图像的平均处理时间,它是处理时间和后处理时间的总和。包含多个工具的流的处理时间无法通过 VisionPro Deep Learning GUI 获得,而且由于处理时间包括准备和在工具之间传输视图信息所需的时间,因此无法通过汇总流的工具执行时间来估计处理时间。
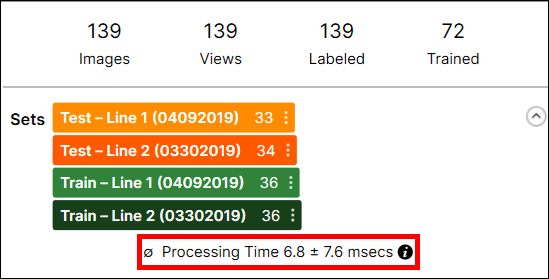
混淆矩阵
混淆矩阵是基本事实与工具预测的直观表示。工具的混淆矩阵是召回和精度得分的图形表示。混淆矩阵的每一行代表由用户标注的特征的数量(这是基本事实),而混淆矩阵的每一列代表由工具预测的特征的数量(这是标记)。如果您单击数据库概述上混淆矩阵中的每个单元格,表格的每个单元格中的相应项目(视图)将显示在视图浏览器上。
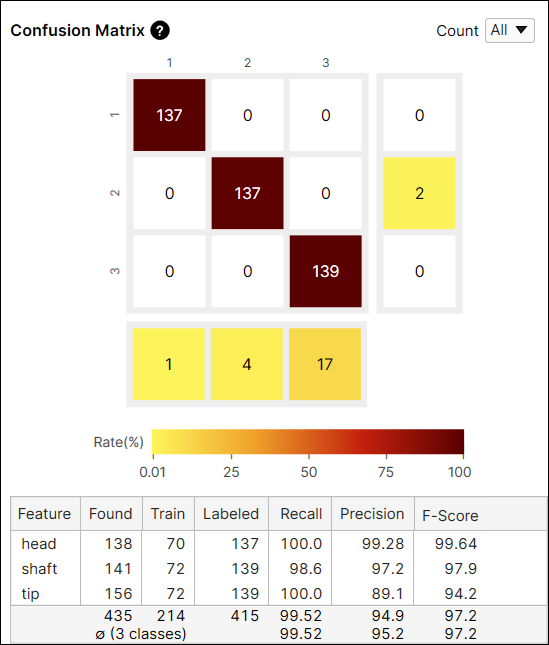
混淆矩阵单元格的颜色表示预测特征的数量(单元格的值)与标注特征的总数(行总和)的比率。颜色越深表示比率越高,颜色越浅表示比率越低。
例如,索引 (2,2) 处的单元格的颜色是棕色,因为在标签为“轴”的特征中,预测为“轴”的特征的数量是 127,它占标签为“轴”的特征的 90.7% (127/140)。
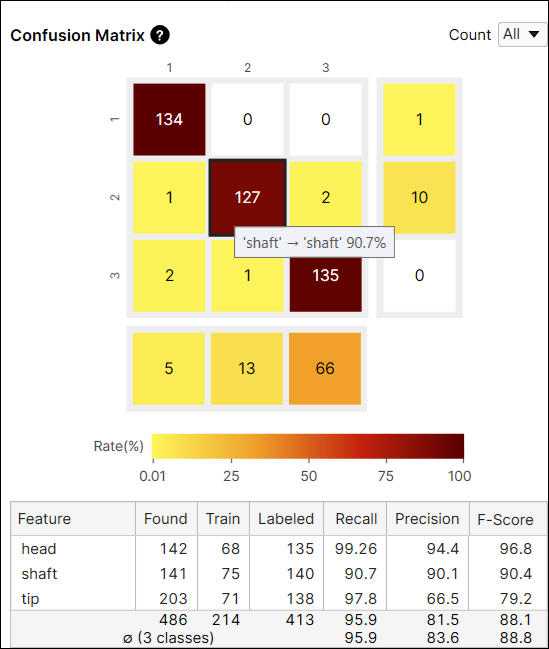
又例如,索引 (2,3) 处的单元的颜色是黄色,因为在标签为“轴”的特征中,预测为“尖端”的特征的数量是 2。预测为“尖端”的特征数量占标签为“轴”的特征的 1.4% (2/140)。
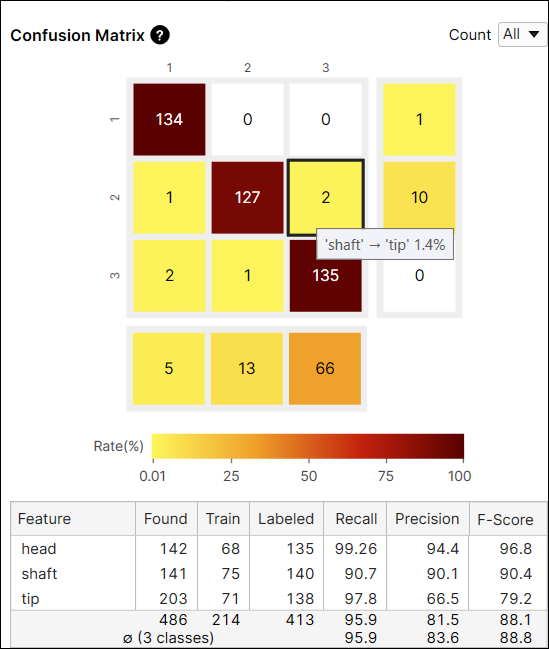
通常建议将较暗的单元放置在混淆矩阵的对角线索引处,因为它代表理想的结果。
|
|
|
|
性能良好 |
性能不佳 |
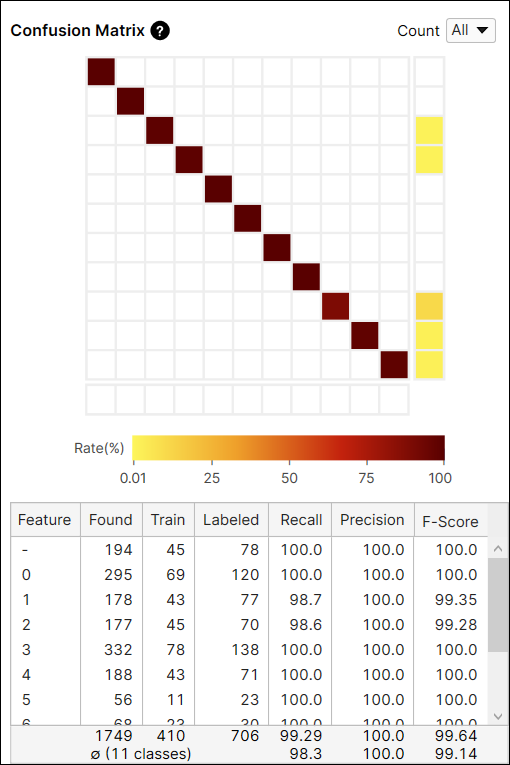
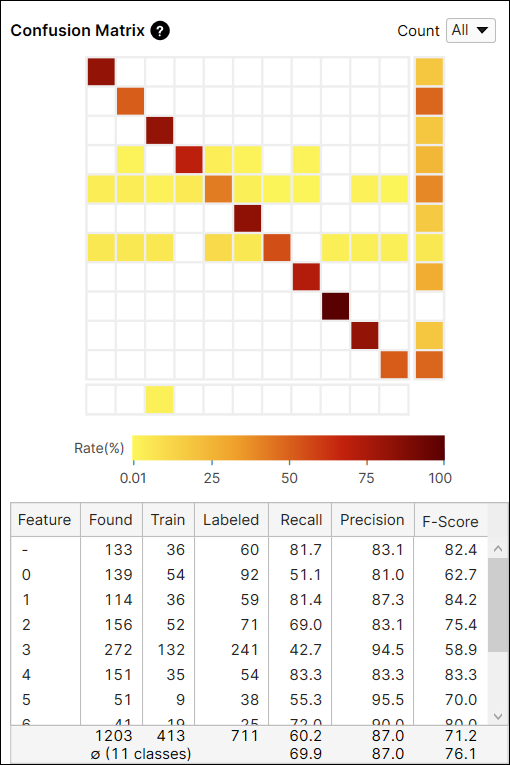
混淆矩阵计算:所有视图与未训练视图
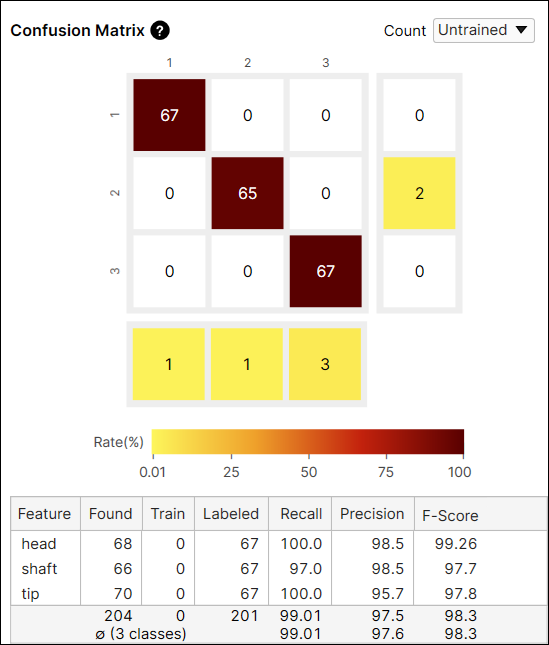
混淆矩阵中的“计数”选项提供从所有视图(全部)或仅从未包括在训练集中的视图(未训练视图)计算的当前工具的结果。您可以在从每个视图(包括训练和测试图像)生成的结果和仅从作为测试图像的未训练视图生成的结果之间切换。
结果指标
蓝色定位的数据库概述中有 2 个表,每个表显示的结果不同。上面的一个表显示图像中每个特征的结果指标,下面的另一个表显示图像中每个模型的结果指标。在这里,模型代表节点和布局模型之一,而不是蓝色定位的神经网络模型。
“标记模型”是由用户在视图上创建(标注)的模型。在处理步骤中,蓝色定位使用它来判断是否在视图中找到了此模型。因此,“找到的模型”是经过训练的蓝色定位在视图上找到的模型。
如果在大致相同的位置存在标注模型并且该找到的模型具有接近相应标注特征的特征,则认为找到的模型是正确匹配(正确标注的模型)。模型的精度、召回、F 得分都是在这个基础上计算出来的,如果一个视图中有多个模型,所有模型指标都是由每个模型分别计算的。
特征指标
| 表 | 指标 | 说明 |
|---|---|---|
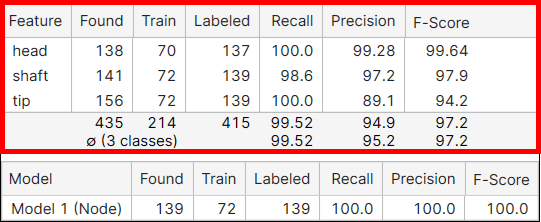
|
特征 |
特征的名称。 |
|
已找到 |
说明在所有视图中作为处理结果找到了该特征类的多少特征对象。 | |
|
训练 |
说明训练集中包含(标注)此特征类的多少特征对象。 | |
| 已标注 | 说明在所有视图中包含(标注)了此特征类的多少特征对象。 | |
|
召回 |
工具找到标注特征对象的可能性。召回是神经网络在所需特征实际存在的地方找到特征的能力。它表示为正确标记的特征的数量除以标注特征的数量的结果。高召回分数可能意味着找到了所有标注特征。但是,由于召回没有考虑到错误发现的特征,即使召回率高也仍可能是 I 类错误。有关详细信息,请参阅基本概念:假正值,假负值。 | |
|
精度 |
工具找到已标注特征的精确程度。精度是神经网络正确定位特征的能力。它表示为正确标记的特征除以已找到特征总数的结果。在理想情况下,高精度意味着所有已找到特征都存在于图像中。但是高精度并没有考虑到所有未找到的特征,所以仍可能是 II 类错误,即有更多未被检测到的特征。有关详细信息,请参阅 基本概念:假正值,假负值。 | |
|
F-得分 |
精度和召回的调和平均值。 |
模型指标
| 表 | 指标 | 说明 |
|---|---|---|
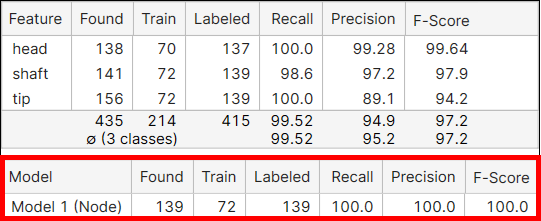
|
模型 |
模型名称。 |
|
已找到 |
说明在所有视图中作为处理结果找到了多少模型。 | |
|
训练 |
说明训练集中包含多少标注模型。 | |
|
已标注 |
说明在所有视图中有多少标注模型。 | |
|
召回 |
工具找到标注模型的可能性。召回是神经网络在所需模型实际存在的地方找到模型的能力。它表示为正确标记的模型的数量除以标注模型的数量的结果。高召回分数可能意味着找到了所有标注模型。但是,由于召回没有考虑到错误发现的特征,即使召回率高也仍可能是 I 类错误。有关详细信息,请参阅 基本概念:假正值,假负值。 |
|
|
精度 |
工具找到已标注模型的精确程度。精度是神经网络正确定位模型的能力。它表示为正确标记的模型除以已找到模型总数的结果。在理想情况下,高精度意味着所有已找到模型都存在于图像中。但是高精度并没有考虑到许多未找到的模型,所以仍可能是 II 类错误,即有更多未被检测到的模型。有关详细信息,请参阅 基本概念:假正值,假负值。 | |
|
F-得分 |
精度和召回的调和平均值。 |
基本概念:假正值,假负值
除了统计结果组件,了解它们如何影响假阳性和假阴性结果也很重要。
假设有一个用于捕获图像中缺陷的图像检测系统。如果它捕获了图像中的一个或多个缺陷,则该图像的检查结果为正 ,如果它根本没有捕获任何缺陷,则该图像的检查结果为负 。那么,检验任务的统计结果可以归纳为以下几点:
-
假正值(也称为 I 类错误)
-
检测系统识别特征的类,但该特征实际上并不属于该类。
-
-
假负值(也称为 II 类错误)
-
检测系统无法识别特征的类,但该特征应该已被识别为属于该类。
-
基本概念:精度、召回和 F-得分
然后,使用以下指标对假正值和假负值再次进行汇总并表示:精度和召回、所有VisionPro Deep Learning工具中使用的统计结果。
- 精度
- 低精度的神经网络通常无法从给定的图像数据(测试数据)中正确抓取本应检测到的特征,因此它会返回许多假正值判断(1 类错误)。
- 高精度的神经网络通常能够成功地从给定的图像数据(测试数据)中正确抓取特征,但如果与低召回结合使用,则可能会出现许多假负值判断(2 类错误)
- 召回
- 低召回的神经网络通常无法从给定的图像数据(测试数据)中充分抓取本应检测到的特征,因此它会返回许多假负值判断(2 类错误)。
- 高召回的神经网络通常能够成功地从给定的图像数据(测试数据)中充分抓取特征,但如果与低精度结合使用,则可能会出现许多假负值判断(1 类错误)
总之,
- 精度 - 已检测到的与标注特征相匹配的特征的百分比。
- 召回 - 工具正确识别的检测特征的百分比。
- F-得分 - 召回和精度的调和平均值。
几乎所有检查案例(可能有例外)的理想统计结果同时包括高精度和高召回 。
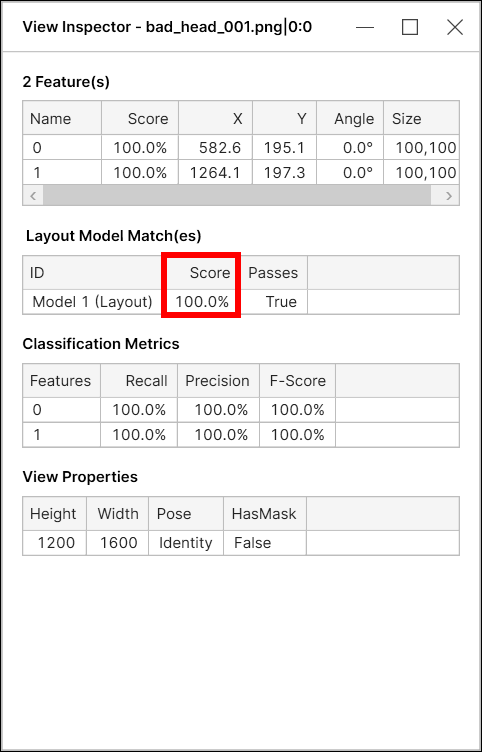
节点模型分数
对于蓝色定位工具,节点模型分数(模型匹配分数)是两个因素的组合:
-
此模型中特征的平均分数
-
“几何分数”基于此模型中特征的几何排列
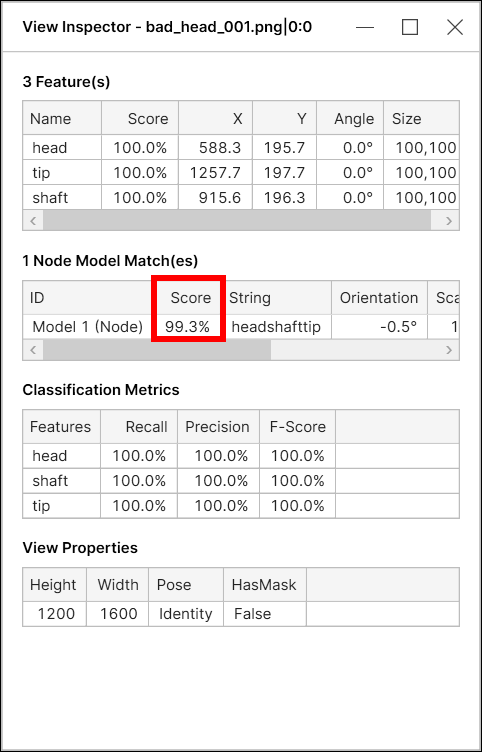
由于几何排列包括在整体模型匹配分数的计算中,因此,如果几何分数小于100%,则即使所有特征的完美分数为 100%,节点模型分数也可能小于 100%。
“几何体分数”只是测量特征的相对位置与模型中节点的相对位置之间的差异程度。例如,对于具有 3 个节点的节点模型,如果每个特征的分数为 100%,则总体模型匹配分数将略低于 100%,因为其几何图形分数将低于 100%,除非特征的空间布局与模型的空间布局完全匹配。
布局模型分数
对于蓝色定位工具,布局模型分数(模型匹配分数)是此模型中特征的平均分数。