蓝色读取
关于 蓝色读取
蓝色读取工具 用于执行光学字符识别 (OCR)。这是一种预训练工具,已经在大型图像数据库上进行过训练,其中包含多种字体和背景的文本。预训练工具的字符包括数字 (0-9)、大写字母(A-Z,除“O”外)、连字符 (-)、加号 (+)、和符号 (&)、冒号 (:) 和前斜线 (/)。
用于执行光学字符识别 (OCR)。这是一种预训练工具,已经在大型图像数据库上进行过训练,其中包含多种字体和背景的文本。预训练工具的字符包括数字 (0-9)、大写字母(A-Z,除“O”外)、连字符 (-)、加号 (+)、和符号 (&)、冒号 (:) 和前斜线 (/)。
与蓝色定位工具类似,蓝色读取工具可将字符作为图像中的特征进行识别和定位。但是,如上所述,蓝色读取工具是一种预训练工具,无需训练即可为其提供读取性能的通用基线。因此,当工具首次配置后,它几乎可以立即识别和读取字符。工具已经知道如何读取字符;您只需要定义要在图像中的哪个位置查找字符即可。
蓝色读取工具的优势在于能够处理困难的项目,也就是低对比度、低分辨率和/或变形字符。此外,设置所需的分割配置或图像筛选条件非常简单。该工具能够读取传统机器视觉工具难以读取的字符;特别是嘈杂背景上的变形和/或弯曲的字符。
要使用该工具,请提供训练图像集,然后设置要读取的字符周围的区域。调整特征尺寸参数并标注字符。在大多数情况下,该工具将自动识别并正确读取字符,并生成字符标记,您可以接受这些标记作为进一步训练的标签。标注至少一个字符实例,然后训练工具。然后在训练阶段未使用的图像上查看该工具。
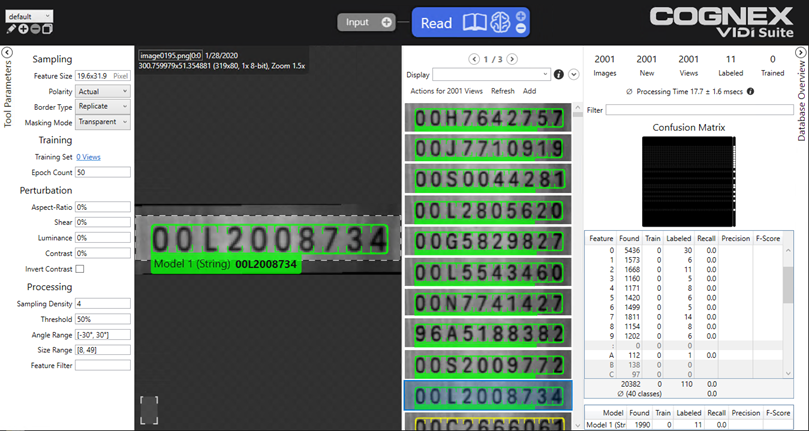
蓝色读取的神经网络架构是聚焦,因此它包含聚焦架构的所有属性,就像红色分析聚焦监督和绿色分类聚焦工具一样。
| 蓝色读取 | |
|---|---|
| 图像数据集组成 | 训练集、测试集 |
| 监控验证损失 | X |
| 损失检查器 | 不支持 |
蓝色读取的训练工作流
在工具处于蓝色读取模式时,工具的训练工作流为:
- 启动 VisionPro Deep Learning。
- 创建新工作区或将现有工作区导入 VisionPro Deep Learning。
- 收集包含字符的图像并将其加载到 VisionPro Deep Learning。
-
添加蓝色读取工具。
-
配置 ROI 和特征尺寸
-
在读取工具中设置 ROI 和特征尺寸。
Note: 有关设置特征尺寸的更多信息,请参阅配置采样参数。 - 在“图像显示”窗口中,单击第一个图像。
- 矩形 ROI 将包含覆盖图像。
- 调整 ROI 的大小,以使其覆盖字符。ROI 在左上角和右下角有两个拖动点,您可以使用它们来拖动和调整 ROI 的大小,使其覆盖所有图像中的字符及其可能的位置。
- 设置 ROI 后,按应用按钮。
- 然后,这会将 ROI 设置应用于所有图像。
- 应用 ROI 后,再次单击第一个图像。
-
在显示屏的左下角将有一个交互式“特征尺寸”框,表示默认的字符大小。您可以选中框并将之拖动到字符上,并重新调整大小以使其适合字符。
Tip: 尽量避免让框过大,以致于包含了另一个字符的部分。在一个字符上设置后,您可以将其移动到其他字符周围以确保其大小正确。 -
设置字符大小后,按书本图标,即可根据新字符大小处理所有图像。这会将新字符大小应用于所有图像。
Note: 如果在一个图像中更改了字符大小,则更改将自动应用于所有其他图像。但是,如果缩放参数选项处于活动状态,则这些特征将仅调整其宽高比以满足标称特征尺寸的特征,并将特征限制在名义特征尺寸 [1/4, 4] 的区间内。这将需要按书本图标以重新处理图像,并查看特征尺寸变化对训练集中其余图像产生的结果。
-
-
标注字符
下一个主要步骤是标注字符。至少要标注每个字符的一个实例。标注过程提供了一种有用的机制,用于在训练前确定工具是否正确解析字符。
- 展开数据库概述窗口。该表列出了工具找到的所有字符。
- 逐一查看表中的字符,并为每个找到的字符选择一个实例:
- 在表格中,选择一个字符,然后双击,这将更改“显示”窗口以仅显示该字符的实例。
- 从显示的字符中,选择一个良好的字符实例。
- 主显示屏将切换到该图像。右键单击图像并选择接受视图。
- 这将创建该字符实例的标签。
- 同时删除工具错误标注字符的任何实例:选择字符,右键单击并选择删除特征即可。
Note: 通过标注和接受一个以上的字符实例,工具在训练工具时将获得更好的训练结果。有关标注的详细信息,请参阅创建特征标签(特征标注)。 - 展开数据库概述窗口。该表列出了工具找到的所有字符。
-
训练工具
使用蓝色读取识别字符时,请执行以下步骤:
-
一旦完成了每个字符的实例标注,就可以训练工具了。要训练该工具,首先将所需图像添加到训练集中。
-
在视图浏览器中选择图像,然后在右键单击的弹出菜单中单击将视图添加到训练集。
-
要在视图浏览器中选择多个图像,请使用 Shift + 鼠标左键。或者,使用显示筛选条件仅显示训练所需的图像,并通过单击...视图的操作→将视图添加到训练集将它们添加到训练集。
-
-
在训练之前,您需要在工具参数中设置参数。可以配置训练、采样和扰动参数或仅使用这些参数的默认值。有关支持参数的详细信息,请参阅配置工具参数。
-
请确保已设置采样参数中的特征尺寸参数。特征尺寸参数为网络提供了您有兴趣识别的字符大小的线索。因此,如果特征尺寸参数设置明显偏离应用程序中字符的尺寸,则该工具可能无法识别图像中的字符。
-
如果您想对训练或处理进行更精细的控制,请打开帮助菜单上的专家模式以初始化工具参数中的其他参数。
-
-
使用正确图像填充训练集后,按大脑
 图标,软件将开始计算以进行训练。
图标,软件将开始计算以进行训练。-
如果您在训练时通过按停止
 图标停止训练,您可以停止训练,但您将丢失目前训练的当前工具。
图标停止训练,您可以停止训练,但您将丢失目前训练的当前工具。
-
-
训练后,审核结果。打开数据库概述面板并查看每个字符和每个模型的混淆矩阵和精度、召回、F-得分以了解结果。有关解释结果的详细信息,请参阅解释结果。
-
查看结果后,浏览所有图像并查看该工具如何正确或错误地标记每个图像的特征和模型。
-
-
查看字符模型
训练完成后,您可以根据预期字符的数量、它们的间距和位置以及它们的字符安排生成字符模型。
-
查看训练
训练完成后,您将需要重新查看图像,确保工具正确识别图像中的字符。同样,您可以使用数据库概述窗口查看字符表,并查看结果。工具找到的每个字符都应该是预期字符;例如,对于 #2,显示屏窗口中的所有实例都应该是 #2。如果存在带有“5”或“S”的实例,则需要单击图像并使用正确的标签重新标注这些实例。
如果工具正确找到所有实例,则工具已准备好进行运行时部署。但是,如果必须重新标注某些实例,则需要重新训练工具,然后重复查看过程。
每个步骤的详细信息在训练蓝色读取的每个子小节中说明。