解释结果
经过训练和处理后,系统会针对所有视图计算工具的结果。但是,只应在测试集上检查结果,才能对工具进行正确的评估。
测试集:用于评估结果的图像
VisionPro Deep Learning 内的统计测量用于验证训练后的神经网络的性能。在深度学习范例中,验证是指根据测试数据(由用户标注,但未用于训练的数据)评估经过训练的神经网络模型的过程。因此,如果您想通过统计指标来确定神经网络模型的可用性和性能,则必须仅根据测试数据计算这些指标。
重要的是要明白,在训练你的神经网络模型后(指您的工具,即蓝色定位/读取、绿色分类或红色分析),如果您想检查模型是如何训练好的,不允许您根据用于训练此模型的数据测试模型。训练数据不能用于评估训练模型,因为模型在训练期间已经拟合到该数据,以在给定训练数据集的情况下发挥最佳性能。因此,这些数据无法说明模型泛化的程度,也不能说明在遇到看不见的新数据时也能很好地执行。
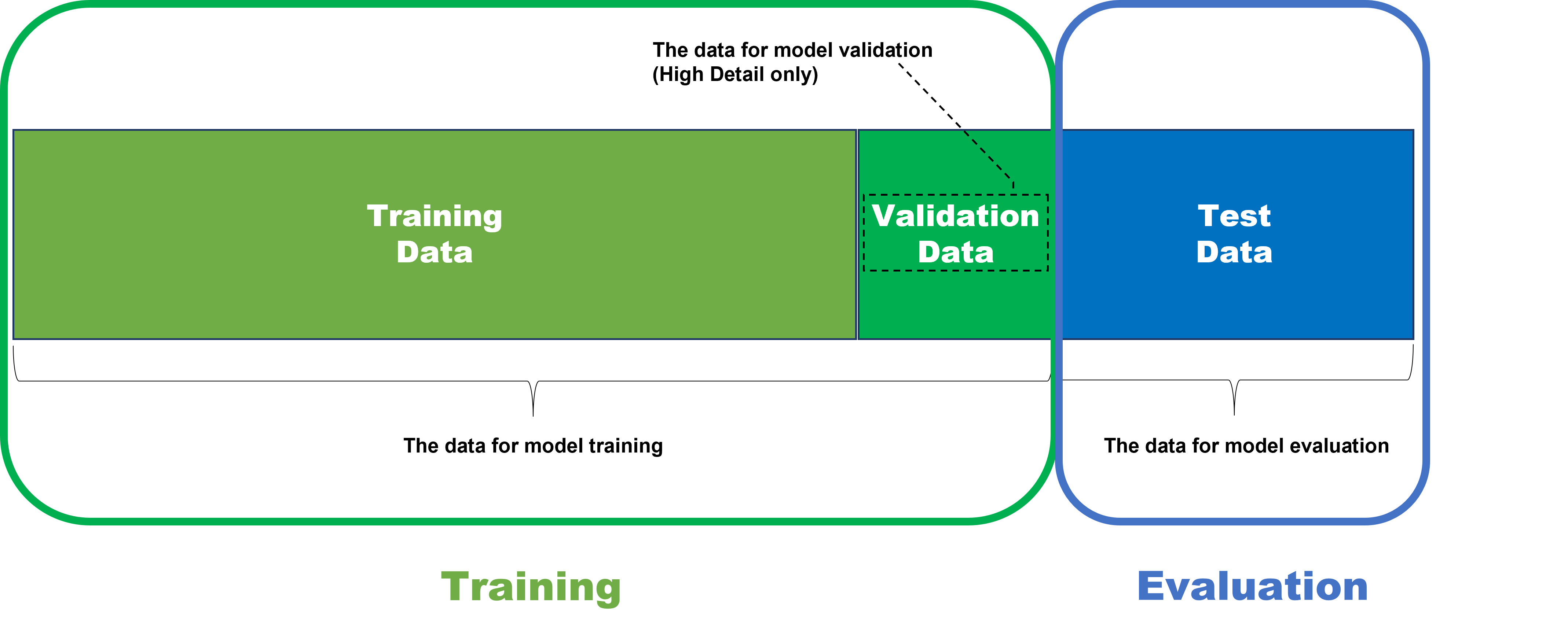
因此,为了公平正确地测试模型的可用性和性能,模型应该应用于它之前从未见过的数据,包括其训练阶段。这就是为什么模型评估的数据被称为测试数据集。
数据库概述
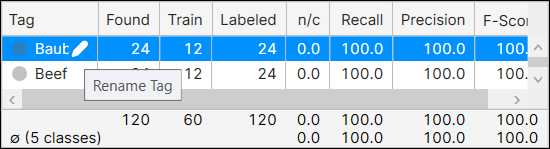
“数据库概述”窗格提供有关用于训练的图像和视图的信息,以及对 Cognex 深度学习工具的统计输出的访问。此窗格将根据所选工具更改其显示。
可以单击名称并按下铅笔图标以启动“重命名标记”对话框,然后对标记进行重命名。
在专家模式下,您可以使用筛选条件字段分隔图像/视图,并仅对这些图像/视图执行统计分析。有关筛选图像/视图的语法信息,请参阅显示筛选条件和筛选条件;有关筛选条件的可能用途的更多信息,请参阅测试图像样本集主题。
处理时间
单独工具处理时间在数据库概述中显示,如下所示:
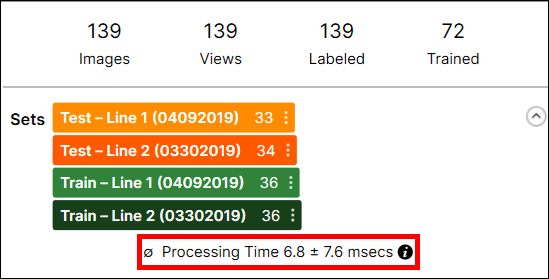
处理时间是上一个处理任务中每个图像的平均处理时间,它是处理时间和后处理时间的总和。包含多个工具的流的处理时间无法通过 VisionPro Deep Learning GUI 获得,而且由于处理时间包括准备和在工具之间传输视图信息所需的时间,因此无法通过汇总流的工具执行时间来估计处理时间。
结果指标
绿色分类工具的统计信息包含“召回”、“精度”和“F-得分”值。此外,它还包括一个交互式混淆矩阵(在数据库概述中可见)。
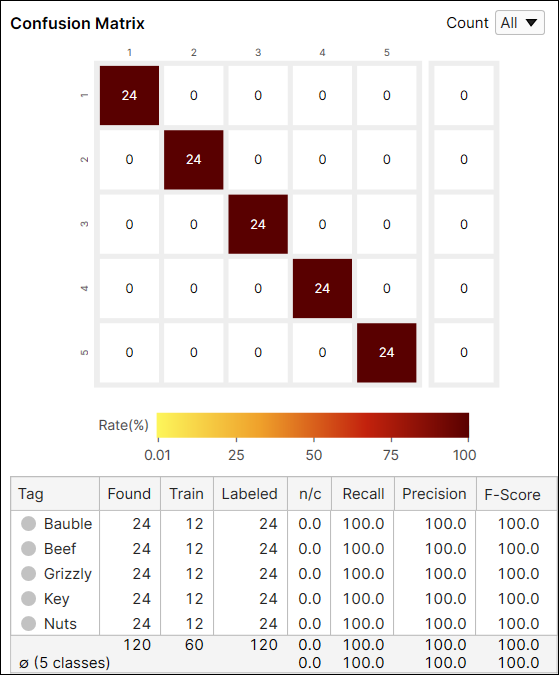
绿色分类高细节快速的输出指标如下所示:
- 混淆矩阵
- 精度、召回和 F-得分
基本概念:假正值,假负值
除了统计结果组件,了解它们如何影响假阳性和假阴性结果也很重要。
假设有一个用于捕获图像中缺陷的图像检测系统。如果它捕获了图像中的一个或多个缺陷,则该图像的检查结果为正 ,如果它根本没有捕获任何缺陷,则该图像的检查结果为负 。那么,检验任务的统计结果可以归纳为以下几点:
-
假正值(也称为 I 类错误)
-
检查系统识别图像的类,但该图像实际上并不属于该类。
-
-
假负值(也称为 II 类错误)
-
检查系统无法识别图像的类,但该图像应该已被识别为属于该类。
-
基本概念:精度、召回和 F-得分
然后,使用以下指标对假正值和假负值再次进行汇总并表示:精度和召回、所有VisionPro Deep Learning工具中使用的统计结果。
- 精度
- 低精度的神经网络通常无法对应正确分类的图像(测试数据)进行正确分类,因此它会返回许多假正值判断(1 类错误)。
- 高精度的神经网络通常能够成功地正确分类图像数据(测试数据),但如果与低召回结合使用,则可能会出现许多假负值判断(2 类错误)
- 召回
- 低召回的神经网络通常无法对应分类的图像(测试数据)进行充分的分类,因此它会返回许多假负值判断(2 类错误)。
- 高召回的神经网络通常能够对图像(测试数据)进行充分的分类,但如果与低精度结合使用,则可能会出现许多假正值判断(1 类错误)
总之,
- 精度 - 已检测到的分类与标注分类相匹配的百分比。
- 召回 - 工具正确识别的标注类的百分比。
- F-得分 - 召回和精度的调和平均值。
几乎所有检查案例(可能有例外)的理想统计结果同时包括高精度和高召回 。
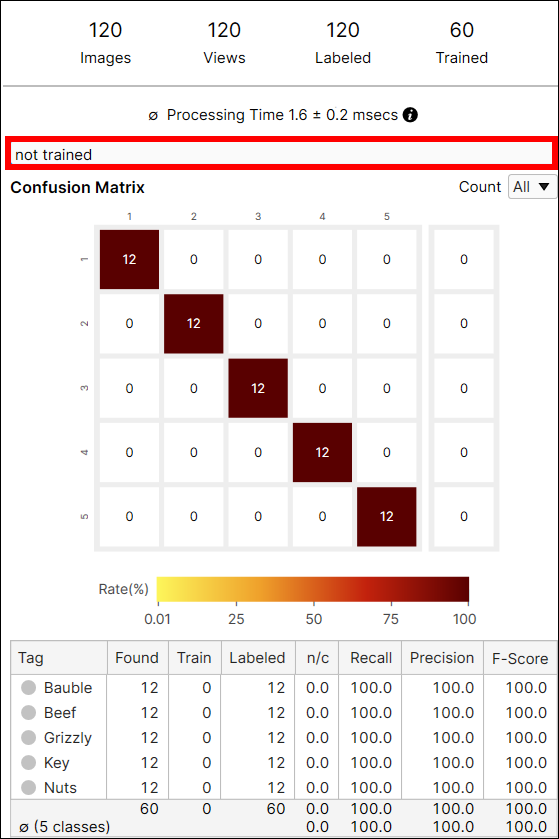
绿色分类的混淆矩阵
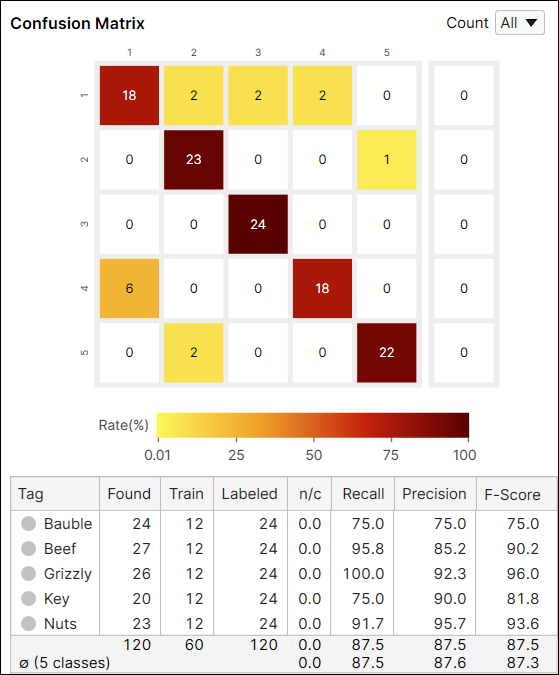
混淆矩阵是基本事实与工具预测的直观表示。绿色分类工具的混淆矩阵是召回和精度得分的图形表示。左侧的混淆矩阵是右表的表示。如果您单击数据库概述上混淆矩阵中的每个圆圈,表格的每个单元格中的相应项目(视图)将显示在视图浏览器上。
|
预测类 |
||||||
|
Bauble |
Beef |
Grizzly |
Key |
Nuts |
||
|
实际类 |
Bauble |
18 |
2 | 2 | 2 | |
|
Beef |
23 |
1 |
||||
|
Grizzly |
24 |
|||||
|
Key |
6 |
18 |
|
|||
|
Nuts |
2 |
22 |
||||
混淆矩阵单元格的颜色表示预测视图的数量(单元格的值)与标注视图的总数(行总和)的比率。颜色越深表示比率越高,颜色越浅表示比率越低。
例如,索引 (1,1) 处的单元格的颜色是深红色,因为在标签为“Bauble”的视图中,分类为“Bauble”的视图的数量是 18,它占标签为“Bauble”的视图的 75% (18/24)。
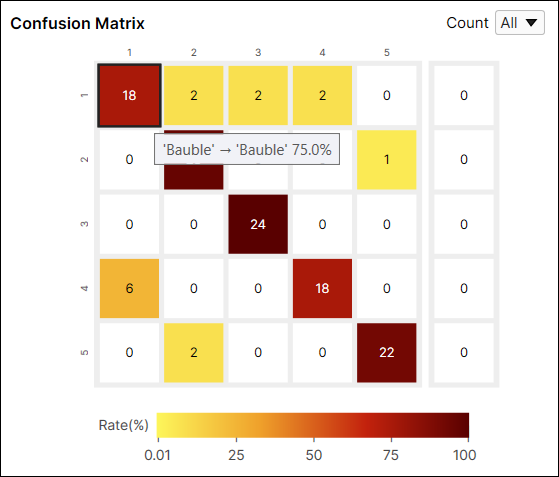
又例如,索引 (1,2) 处的单元格的颜色是黄色,因为在标签为“Bauble”的视图中,分类为“Beef”的视图的数量是 2。分类为“Beef”的视图数量占标签为“Bauble”的视图的 8.3% (2/24)。
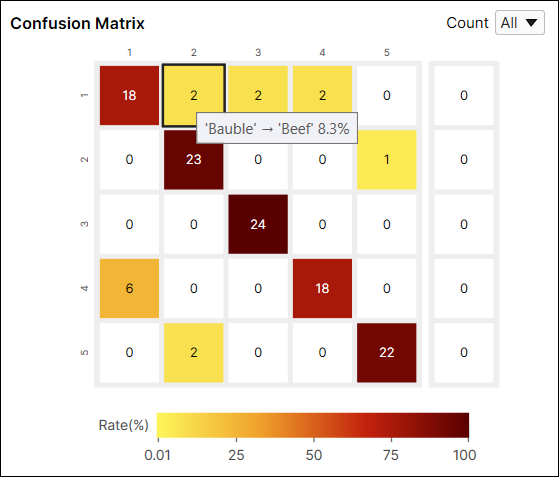
通常建议将较暗的单元放置在混淆矩阵的对角线索引处,因为它代表理想的结果。
|
|
|
| 性能良好 |
性能不佳 |
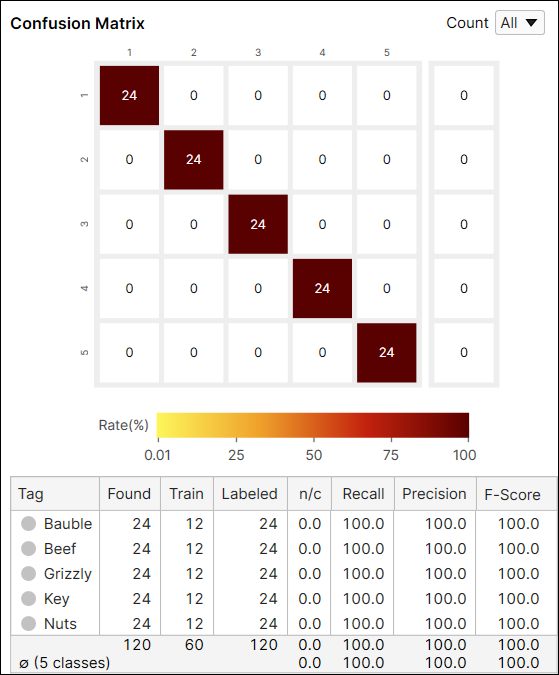
混淆矩阵表中的变量
| 变量 | 说明 |
| 标记 | 类标签。 |
| 已找到 | 分裂(预测、标记)为此类的视图总数。 |
| 训练 | 标注为此类并包含在训练集中的视图总数。 |
| 已标注 | 标注为此类的视图总数。 |
| n/c (未分类) |
不在训练集中且其分数(类概率)低于阈值的视图的比例。 |
| 召回 |
在标记为此类且不在训练集中的视图中正确分类的视图的百分比。有关详细信息,请参阅以下部分。 |
| 精度 | 分类为此类且不在训练集中的视图中正确分类的视图的百分比。有关详细信息,请参阅以下部分。 |
| F-得分 | 上面计算的精度和召回的调和平均数。 |
混淆矩阵计算:所有视图与未训练视图
混淆矩阵中的“计数”选项提供从所有视图(全部)或仅从未包括在训练集中的视图(未训练视图)计算的当前工具的结果。您可以在从每个视图(包括训练和测试图像)生成的结果和仅从作为测试图像的未训练视图生成的结果之间切换。
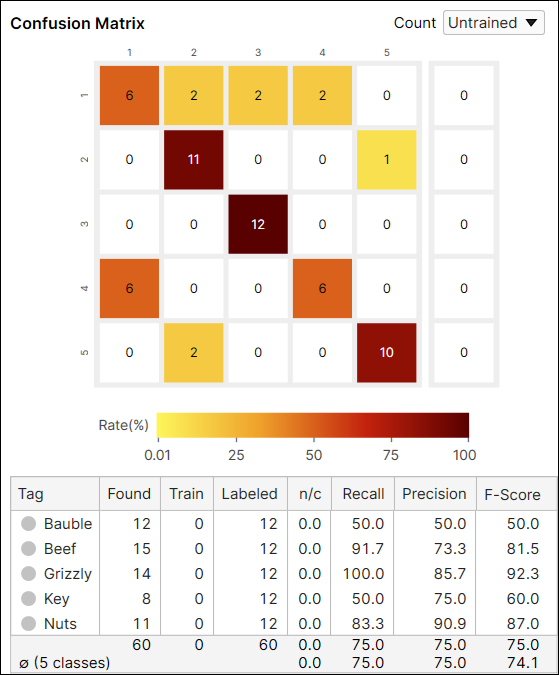
绿色分类的精度、召回、F-得分
使用未用于训练工具的数据计算精度和召回。F-得分是精度和召回的调和平均数,因此它也基于不在训练集中的数据得出的。您可以使用显示过滤器手动计算出与混淆矩阵表中的值相同的值。
|
预测类 |
||||||
|
Bauble |
Beef |
Grizzly |
Key |
Nuts |
||
|
实际类 |
Bauble |
18 |
2 | 2 | 2 | |
|
Beef |
23 |
1 |
||||
|
Grizzly |
24 |
|||||
|
Key |
6 |
18 |
|
|||
|
Nuts |
2 |
22 |
||||
-
“Beef”类的精度计算示例(显示筛选语法)
-
真正值:best_tag='Beef' 和 tag![name='Beef'] 未训练
-
假正值:best_tag='Beef' 和 tag![name!='Beef'] 未训练
-
精度 = 真正值/(真正值 + 假正值)
-
-
“Beef”类的召回计算示例(显示筛选语法)
-
真正值:best_tag='Beef' 和 tag![name='Beef'] 未训练
-
假负值:best_tag!='Beef' 和 tag![name='Beef'] 未训练
-
召回=真正值/(真正值+假负值)
-
-
“Beef”类的 F-得分计算示例

精度计算
对于绿色分类工具,精度的计算结果为检测到的与已标注类相匹配的类的百分比。
工具计算的精度是预测为类 i 的正确分类视图的百分比:
例如,“鸡胸肉”类的精度为 90% 表示神经网络在 10 次中有 1 次会将鸡胸肉图像与其他类混淆。
|
预测类 |
|||||||||||
|
鸡胸肉 |
鸡腿 |
肉片 |
翅根 |
腿 |
颈部 |
竹签 |
切片的鸡胸肉 |
大腿 |
翅膀 |
||
|
实际类 |
鸡胸肉 |
19 |
1 |
||||||||
|
鸡腿 |
14 |
2 |
2 |
2 |
|||||||
|
肉片 |
20 |
||||||||||
|
翅根 |
19 |
1 |
|||||||||
|
腿 |
18 |
||||||||||
|
颈部 |
2 |
17 |
|||||||||
|
竹签 |
1 |
13 |
|||||||||
|
切片的鸡胸肉 |
4 |
4 |
14 |
||||||||
|
大腿 |
1 |
2 |
16 |
||||||||
|
翅膀 |
20 |
||||||||||
召回计算
对于绿色分类工具,召回是工具正确识别的标注类的百分比。
工具通过标注为类 i 且正确分类为类 i 的已分类视图的分数计算召回得分:
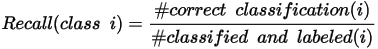
例如,“鸡胸肉”类的召回为 90% 表示神经网络在 10 次中有 9 次会对鸡胸肉图像进行正确分类。
|
预测类 |
|||||||||||
|
鸡胸肉 |
鸡腿 |
肉片 |
翅根 |
腿 |
颈部 |
竹签 |
切片的鸡胸肉 |
大腿 |
翅膀 |
||
|
实际类 |
鸡胸肉 |
19 |
1 |
||||||||
|
鸡腿 |
14 |
2 |
2 |
2 |
|||||||
|
肉片 |
20 |
||||||||||
|
翅根 |
19 |
1 |
|||||||||
|
腿 |
18 |
||||||||||
|
颈部 |
2 |
17 |
|||||||||
|
竹签 |
1 |
13 |
|||||||||
|
切片的鸡胸肉 |
4 |
4 |
14 |
||||||||
|
大腿 |
1 |
2 |
16 |
||||||||
|
翅膀 |
20 |
||||||||||
F-得分计算
对于绿色分类工具,F-得分提供收回和精度值的调和平均数。F-得分往往是工具整体准确性的最佳衡量标准。
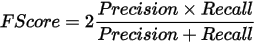
要优化工具,请考虑以下操作:
- 为了绝对避免假阳性,请将目标设定为精度得分为 100
- 为了绝对避免假阴性,请将目标设定为收回得分为 100
否则,请设定以下目标:
- 对于稀疏类很重要的不平衡问题,请使用 F-得分。
- 使用所有类的平均 F-得分。
- 将阈值处理参数设置为 0%,以避免未分类视图的比率发生变化。