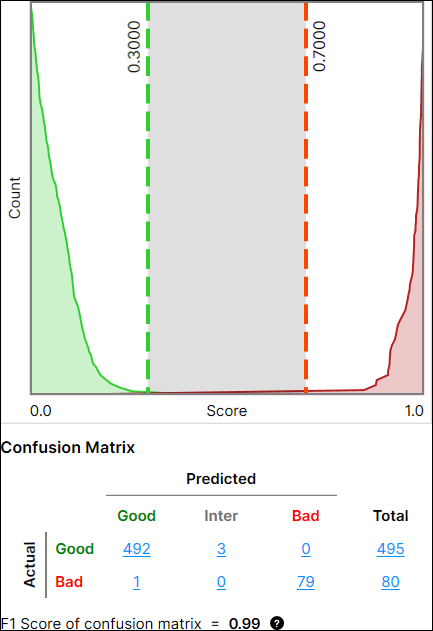
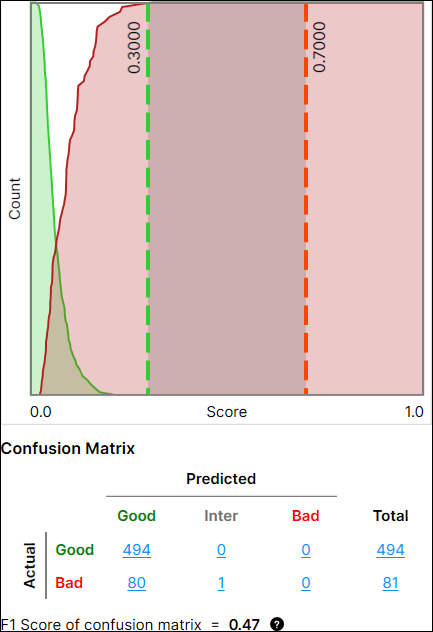
混淆矩阵
混淆矩阵是基本事实与工具预测的直观表示。红色分析工具中的混淆矩阵是工具处理结果的对照表,显示实际值和预测值之间的关系。红色分析监督(红色分析聚焦监督、红色分析高细节)和 红色分析聚焦无监督 中提供了混淆矩阵及其性能指标(混淆矩阵的精度、召回和 F1 分数),这些内容将在下面详细解释。
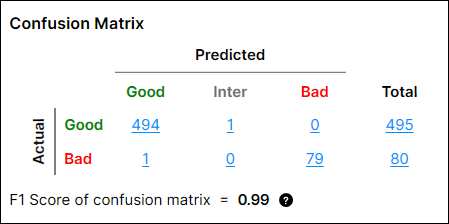
混淆矩阵计数
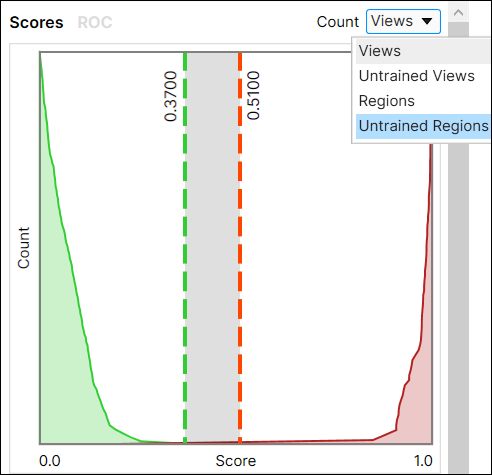
可以使用 4 种方法通过计数下拉选项填充此表:视图、未训练视图、区域和未训练区域。这些方法也用于绘制“得分”图(得分分布图)。
-
视图:每个视图上都印有标签和标记
-
未训练视图:不属于训练集的每个视图上都印有标签和标记。
-
区域:视图中的每个区域上都印有标签和标记。区域被分成缺陷区域(不良)和背景(良好),并据此进行标注和标记。
-
未训练区域:不属于训练集的视图中的每个像素上都印有标签和标记。区域被分成缺陷(不良像素)和背景(良好像素),并据此进行标注和标记。
红色分析有两种标注类型:像素级标注和视图级标注。
像素级标注:右键单击图像显示区域 → 单击“编辑区域” → 绘制缺陷区域并单击“应用”
视图级标注:右键单击视图浏览器中的视图 → 单击“标注视图” → 选择“不良”
对于区域/未训练区域,根本没有标注的像素被视为标注为“良好”(背景)。标记是通过检查像素的缺陷概率是否超过 T1 来预测此像素是否为缺陷像素。请注意,具有像素级缺陷标签的视图也会自动在视图级被标注为“不良”。
混淆矩阵计算 - 视图/未训练视图
在红色分析工具中,可以基于区域或视图计算混淆矩阵。根据所选的计算依据,混淆矩阵的值将明显不同。
基于视图计算时,将对每个视图而不是每个区域进行标记。对于一个视图,如果此视图中存在得分足以超过 T2 阈值的缺陷像素,则将其预测为“不良”,否则预测为“良好”或“中间”。
要将视图标记为“不良”,具有最高缺陷概率(得分)的缺陷像素可以位于视图中的任意位置,而不一定位于标注的缺陷区域内。
基于视图计算时,将对每个视图而不是每个区域进行标注。如果将一个视图标注为“不良”,那么它就被标注为不良视图,否则为“良好”。
如何计算“实际值” - 视图/未训练视图
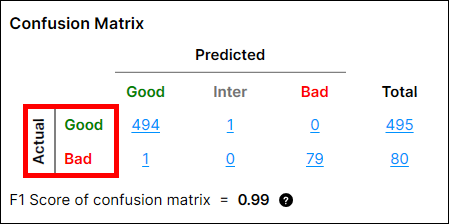
-
当给出带有“良好”标签的视图时,
→ 1 个“良好”的实际视图。 -
当给出带有“不良”标签的视图时,
→ 1 个“不良”的实际视图。
如何计算“预测值” - 视图/未训练视图
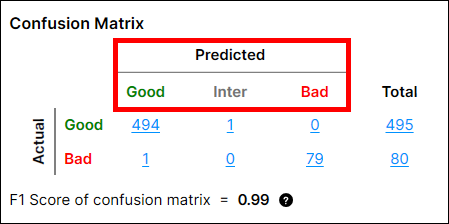
基于视图时,将对上面找到的每个“实际”视图而不是每个区域进行预测。预测值是根据 T1、T2 和实际视图的代表得分计算得出的。
视图的代表得分是此视图中像素的最高得分。每个得分是每个像素的缺陷概率。例如,对于一个视图,如果此视图中存在得分足以超过 T2 阈值的缺陷像素,则将其预测为“不良”,否则预测为“良好或中间”。
-
当视图中所有像素的最高得分 < T1 时,
→ 1 个“良好”的预测视图。 -
当视图中所有像素的最高得分 > T2 时,
→ 1 个“不良”的预测视图。 -
否则,
→ 1 个"中间"的预测视图。
1 个标注“良好”的视图 → 1 个实际的“良好”视图,
1 个标注“不良”的视图 → 1 个实际的“不良”视图
视图中所有像素的最高得分 < T1 → 1 个预测的“良好”视图,
视图中所有像素的最高得分 > T2 → 1 个预测的“不良”视图,
否则,1 个预测的“中间”视图
混淆矩阵计算 - 区域/未训练区域
在红色分析工具中,可以基于区域或视图计算混淆矩阵。根据所选的计算依据,混淆矩阵的值将明显不同。
基于区域时,将对每个区域而不是每个视图进行标注和标记。这意味着将视图中的多个标记区域(“标记区域”表示基于 T1 和 T2 标记为“缺陷”的一组像素)包含在混淆矩阵计算中。换句话说,单个视图可用于在混淆矩阵表中生成多个计数(实际 - 预测对),而单个视图在视图/未训练视图的表中只生成单个计数。
如何计算“实际值” - 区域/未训练区域
与视图/未训练视图相比,对区域/未训练区域的混淆矩阵的“实际值”进行计数时,“实际值”的计数逻辑有所不同。
-
当给出带有“良好”标签的视图时,
→ 1 个“良好”的实际区域
(整个视图本身被视为背景区域)。
-
当给出带有“不良”标签且带有 N 个像素级标注缺陷区域的视图时,
→ N 个“不良”的实际区域,对应于此视图中像素级标注区域的数量(N 个实际的“不良”区域)。
→ 1 个“良好”的实际区域,对应于此视图中的所有背景像素。
-
当给出带有“不良”标签且不带像素级标注缺陷区域的视图时,
→ 1 个“不良”的实际视图。
如何计算“预测值” - 区域/未训练区域
在区域或未训练区域的混淆矩阵中,将对上面找到的每个“实际”区域进行预测,其计算在上一节进行了说明。预测值是根据 T1、T2 和实际区域的代表得分计算得出的。
实际区域的代表得分是“实际”区域中像素的最高得分。这与视图的代表得分是该视图中像素的最高得分相同。每个得分是每个像素的缺陷概率。
在区域或未训练区域的混淆矩阵中,预测结果由 T1、T2 和实际区域的得分确定:
-
实际区域得分 < T1,
→ 1 个“良好”的预测区域
-
T1 < 实际区域得分 < T2,
→ 1 个“中间”的预测区域
-
实际区域得分 > T2,
→ 1 个“不良”的预测区域
区域/未训练区域的实际-预测对计算示例
为了使下面的示例更清楚,这里我们假设从实际区域找到的最高得分高于 T2。
-
当 N 个标记区域出现在背景(标注良好的像素)上,没有像素级标注缺陷,并且此视图本身被标注为“良好”时:
→ 1 个(实际)良好 -(预测)不良对
(N 个标记区域被视为单个标记区域)在此示例中,3 个标记区域出现在背景上,无像素级标注缺陷,视图被标注为“良好”:

-
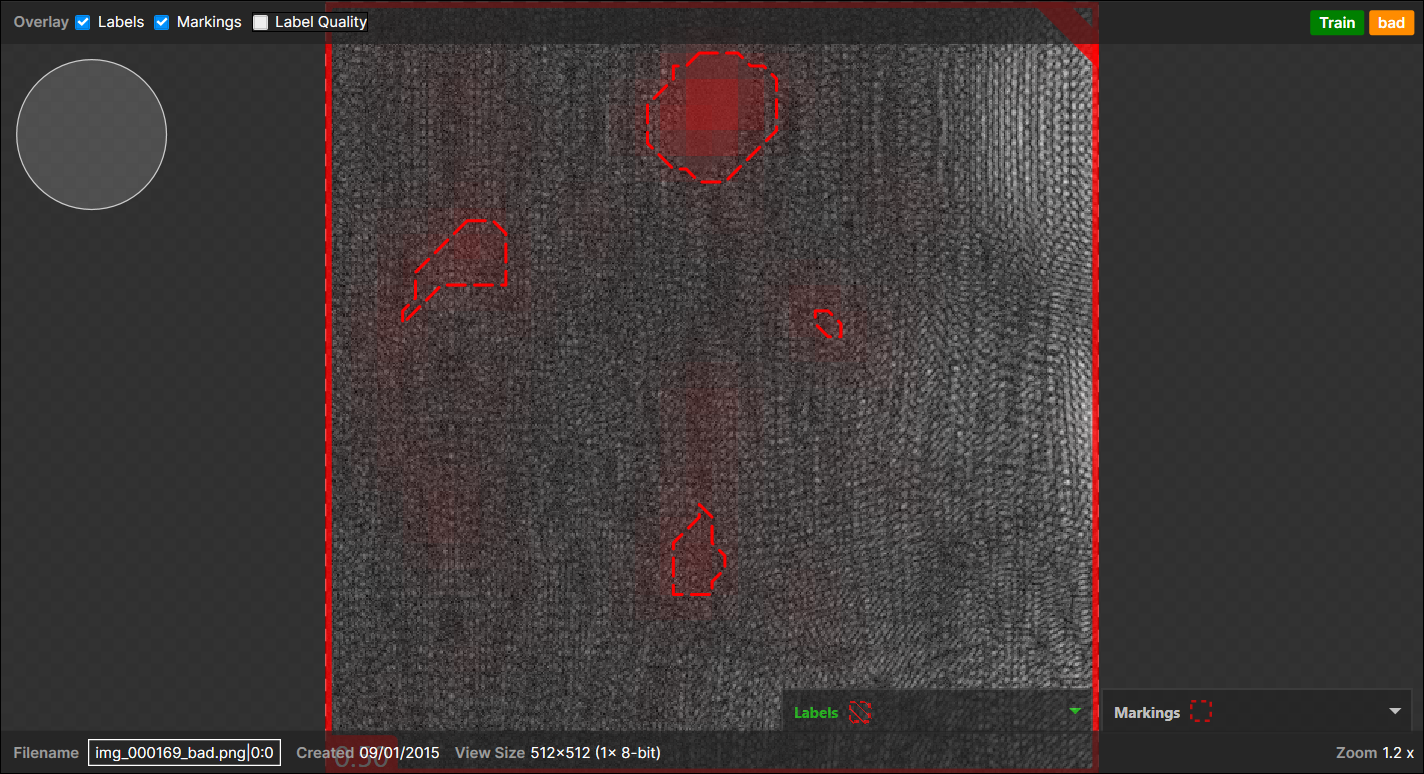
当 N 个标记区域出现在背景(标注良好的像素)上,没有像素级标注缺陷,但整个视图本身被标注为“不良”时:
→ 1个(实际)不良 -(预测)不良对
(N 个标记区域被视为单个标记区域)在此示例中,4 个标记区域出现在背景上,没有像素级标注缺陷,视图被标注为“不良”:
-
当标记区域出现在像素级标注的缺陷区域上时:
此时确定结果的一个重要因素是,总共有多少标记区域与像素级标注的缺陷区域重叠:-
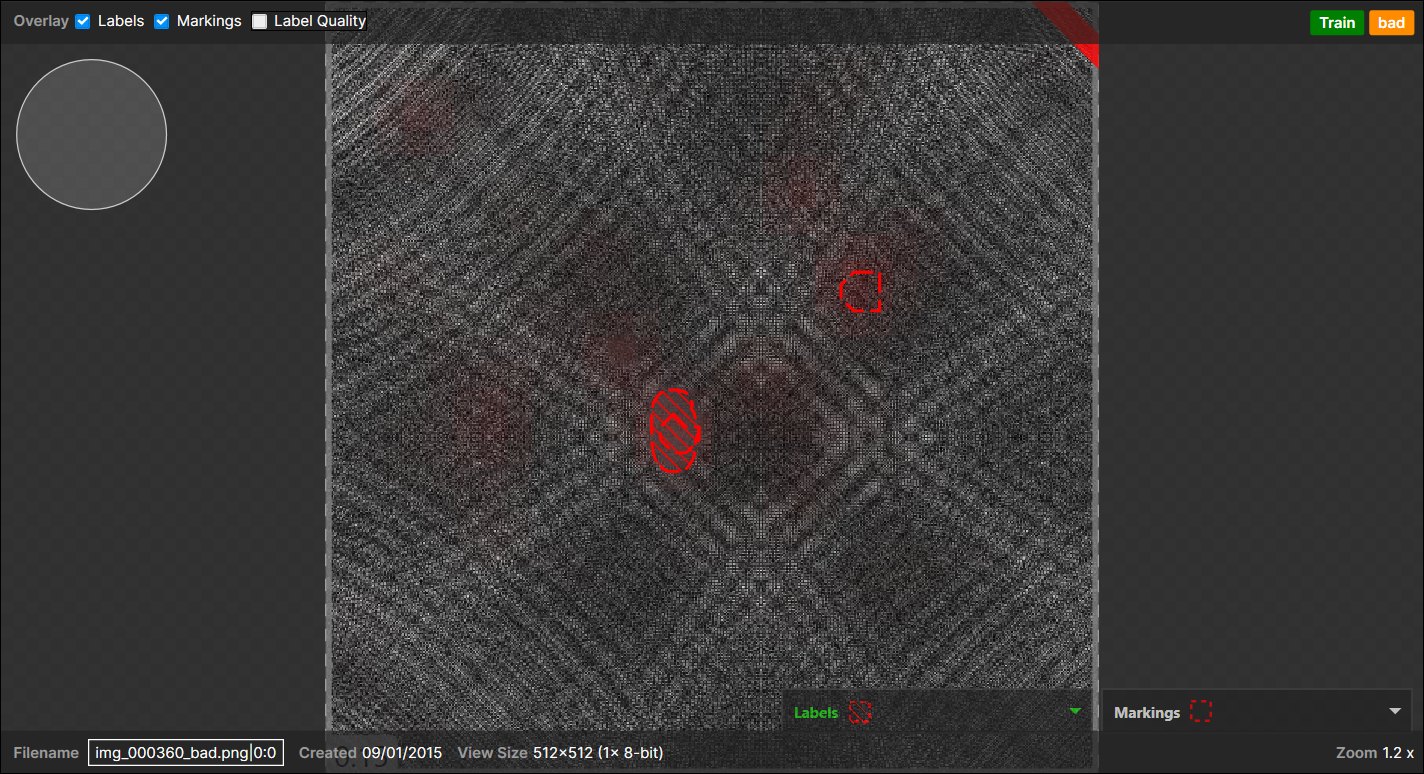
<案例 1>
1 个像素级标注区域,
1 个标记区域(与像素级标注区域重叠),
1 个标记区域(不与像素级标注区域重叠并出现在背景上):
→
1 个(实际)不良 -(预测)不良对(重叠),
1 个(实际)良好 -(预测)不良对(不重叠),Note: 当视图中存在一个或多个像素级标注的缺陷区域时,除了标注区域外,一个块的所有像素都被视为“背景”,计为 1 个实际的“良好”区域。这适用于大多数情况,但不适用于视图中没有像素级标注区域但视图本身被标注为“不良”的情况。在此示例中,一个标记区域出现在背景上,另一个标记区域出现在像素级标注区域上(重叠),并且由于存在一个或多个像素级标注缺陷,此视图本身被标注为“不良”:
-
<案例 2>
5 个像素级标注区域,
3 个标记区域(每个区域与每个像素级标注区域重叠),
2 个标记区域(不与任何像素级标注区域重叠并出现在背景上):
→
3 个(实际)不良 -(预测)不良对(重叠),
2 个(实际)不良 -(预测)良好对(不重叠),
1 个(实际)良好 -(预测)不良对Note: 背景中出现的 2 个标记区域被视为单个标记区域,导致 1 个“不良”的预测区域。这也适用于 N 个标记区域的情况。 -
<案例 3>
3 个像素级标注区域(A、B、C),
3 个标记区域(2 个与 A 重叠,1 个与 B 重叠)
1 个标记区域(不重叠 = 出现在背景上):
→
1 个(实际)不良 -(预测)不良对(2 个与 A 重叠),
1 个(实际)不良 -(预测)不良对(1 个与 B 重叠),
1 个(实际)良好 -(预测)不良对(出现在背景上),
1 个(实际)不良 -(预测)良好对 (C)
-
1 个标注“良好”的视图 → 1 个实际的“良好”区域,
1 个没有像素级标注区域的标注“不良”的视图 → 1 个实际的“不良”区域,
1 个具有 N 个像素级标注区域的标注“不良”的视图,
→ 1 个实际的“良好”区域 + N 个实际的“不良”区域
(N 为用户绘制的缺陷区域的数量)
标注区域的最高得分 < T1 → 1 个预测的“良好”区域,
标注区域的最高得分 > T2 → 1 个预测的“不良”区域,
否则,1 个预测的“中间”区域。
F1 得分计算
混淆矩阵的 F1 得分是精度和召回率的结合,作为分割性能的综合指标。召回率表示神经网络如何很好地匹配标注的缺陷区域,精度表示神经网络如何很好地避免被图像中的其他区域混淆。为了得到混淆矩阵的 F1 得分,必须事先计算精度和召回率。请注意,精度、召回率和 F1 得分的计算方法与以像素级别计算的区域面积指标中不同。
混淆矩阵的 F1 分数根据计数下拉选项发生变化。该分数解释为当前混淆矩阵的精度和召回之间的调和平均值。如果某个视图或区域被预测为“中间”,则在计算精度、召回率和 F1 得分时将其计为“不良”。
-
(实际良好,预测中间)→(实际良好,预测不良)
-
(实际不良,预测中间)→(实际不良,预测不良)
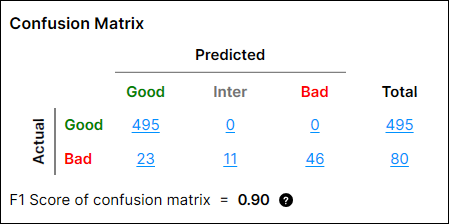
在介绍计算方法之前,关于计算应了解以下事项:
预测“良好”类:
-
1 个“实际良好 - 预测良好”对表示 1 个“真阳性 (TP)”
-
1 个“实际不良 - 预测良好”对表示 1 个“假阳性 (FP)”
-
1 个“实际不良 - 预测不良”对表示 1 个“真阴性 (TN)”
-
1 个“实际良好 - 预测不良”对表示 1 个“假阴性 (FN)”
预测“不良”类:
-
1 个“实际不良 - 预测不良”对表示 1 个“真阳性 (TP)”
-
1 个“实际良好 - 预测不良”对表示 1 个“假阳性 (FP)”
-
1 个“实际良好 - 预测良好”对表示 1 个“真阴性 (TN)”
-
1 个“实际不良 - 预测良好”对表示 1 个“假阴性 (FN)”
根据此设置,“良好”类的混淆矩阵的精度、召回率和 F1 得分的计算如下:
-
精度 = TP / (TP + FP) = 495/(495+23) = 0.956
-
召回 = TP / (TP + FN) = 495/(495+0) = 1
-
F-分数 = 2 * 召回 * 精度 / (召回+精度) = 2 * 0.956 * 1 / 1.956 = 0.978
“不良”类的混淆矩阵的精度、召回率和 F1 得分的计算如下:
-
精度 = TP/(TP+FP) = 57/(57+0) = 1
-
召回 = TP/(TP+FN) = 57/(57+23) = 0.713
-
F-得分 = 2 * 召回 * 精度 /(召回率 + 精度)= 2 * 1 * 0.713 / 1.713= 0.832
则混淆矩阵的 F1 得分为:
-
0.5 * (良好类的 F-得分) + 0.5 * (不良类的 F 分数) = 0.5 * 0.978 + 0.5 * 0.832 = 0.90
|
|
|
|
性能良好 |
性能不佳 |