OCRMax
The OCRMax function reads and/or verifies a text string within a Region of Interest (ROI), after being trained with user-defined character fonts. OCRMax performs Optical Character Recognition through a process of segmentation and classification. Segmentation occurs first and uses threshold techniques to identify the areas of the image that appear to contain lines of text. After the text has been segmented into characters, the characters are trained and stored as a font database. Classification occurs during run-time, and is responsible for “reading” any text found after the function performs segmentation. This is done by comparing the images of the segmented characters to the trained characters in the font.
During the segmentation process, the OCRMax function determines the location of the line of text within the ROI, and calculates the text's angle, skew and polarity. The region is then normalized to remove unwanted noise before being binarized into foreground and background pixels. Within the binarized image, blob analysis is performed to produce character fragments, with each character fragment representing a single blob. The character fragments are then grouped together to form characters, and the characters are assigned a character region. The character region is a tight, non-editable bounding box enclosing all of the foreground (i.e. ink) pixels in the ROI.
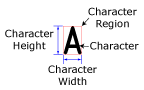
The line of text within the ROI is split into images of the individual characters, and each character is enclosed within a non-editable character rectangle. The ROI defines the approximate location, angle and skew of the line of text. The Angle Range and Skew Range parameters on the Segmentation tab can be used to compensate for variations, if necessary.
OCRMax Inputs
The OCRMax property sheet offers a number of settings to fine tune the function's results. These can be accessed in the property sheet tabs: General, Segmentation, Train Font, Fielding, Results, and Diagnostics.
In addition, the Auto-Tune button in the OCRMax property sheet launches the Auto-Tune Dialog, which is used to automatically calculate the optimal Segmentation parameters, and train a font database. With one or more images loaded, and with the Auto-Tune dialog running, each image is examined to verify that the characters are being correctly segmented and classified. If the characters are not being correctly segmented, the OCRMax function's Auto-Tune algorithm will calculate the optimal Segmentation parameters that segment the current image, as well as the previously trained images. As more images are trained, the OCRMax function's Auto-Tune algorithm will become more reliable and accurate. Once satisfactory results are achieved, the Auto-Tune dialog is closed, the new Segmentation parameters are applied and the font database is updated with the newly trained characters.
- Images only need to be cycled through once, instead of twice (once to tune the Segmentation parameters, and the second to train).
- Read accuracy should improve because the characters are trained automatically with the Segmentation parameters obtained during the tuning process.
OCRMax Outputs
|
Returns |
An OCRMax data structure containing the character string that was read, or #ERR if any of the input parameters are invalid. |
||||||||||||||||||||||||||||||
|
Results |
When OCRMax is initially inserted into a cell, a result table is automatically created in the spreadsheet with the following OCRMax Vision Data Access Functions.
|