NVIDIA GPU の選択と設定
PC システム設定の選択内容は、ツールの精度や動作には影響せず、処理速度に直接影響し、その影響を予測することは最もコストが高く困難です。
| 設定オプション | 高速化する理由 | ベストバリューオプション | 注意事項... |
|---|---|---|---|
|
NVIDIA デバイスタイプ |
CUDA コアの数は、高適合率処理速度と学習に直接関連します。 標準 Tensor コアの数は、処理速度と学習速度に直接関連します。 Tensor コアの数は、低適合率モードの場合のみ、処理速度に関連します。これらのコアは、標準適合率の処理速度または学習速度には影響しません。 |
||
|
NVIDIA ドライバモード |
民生品グレードのゲーミング指向型 NVIDIA デバイスのみが WDDM デバイスのドライバモデルをサポートします。このドライバは、コンピューティングではなくグラフィックス表示のサポートを目的としています。 プロフェッショナルグレードの NVIDIA カードは、より優れたパフォーマンスと安定性を提供する TCC ドライバモードをサポートします。 |
NVIDIA RTX / Quadro® または Tesla (または一部の Titan) ブランドの NVIDIA カードを選択します。 |
GeForce ブランドのカードを使用する場合、NVIDIA ドライバは頻繁にアップデートされ、Deep Learning と互換性がなくなる場合があることに注意してください。 TCC モードドライバを使用すると、GPU カードでビデオ出力が使用されず、代わりにオンボードビデオが使用されます。 |
|
最適化されたメモリ |
デフォルトで有効になっている Deep Learning 最適化メモリにより、標準 NVIDA GPU メモリ管理システムをオーバーライドすることで、パフォーマンスが向上します。 |
カードに少なくとも 4GB の GPU メモリがあることを確認してください。 TCC ドライバを使用するカードの場合、大幅なパフォーマンスの向上にはなりません。 |
|
NVIDIA デバイスのブランドの要約
次の表は、さまざまな NVIDIA デバイスタイプをまとめたものです。
| クラス | コンシューマ | プロフェッショナル | ||
|---|---|---|---|---|
|
ファミリ |
ローエンドゲーミング |
ハイエンドゲーミング |
ワークステーション |
データセンター |
|
ブランド |
GeForce |
Titan |
NVIDIA RTX / Quadro® |
Tesla |
|
Volta アーキテクチャカード |
なし |
Titan V |
GV100 |
V100 |
|
Pascal アーキテクチャカード |
GTX 1xxx |
Titan Xp |
G/GPxxx |
P100 |
|
Turing アーキテクチャカード |
RTX 2xxx |
Titan RTX |
Quadro RTX4xxx |
T4 |
| Ampere アーキテクチャカード | RTX 3xxx |
Titan RTX 2nd Gen. (まだリリースされていません) |
Axxx | Axxx |
|
ビデオ出力 |
有 |
有 |
有 |
無 |
|
価格 |
~ 1,000 ドル |
~ 3,000 ドル |
~ 5,000 ドル |
5,000 ドル~ |
|
TCC ドライバのサポート |
無 |
有 |
有 |
有 |
|
ECC メモリ |
無 |
無 |
有 |
有 |
|
Tensor コア |
|
|
|
|
NVIDIA GPU の用語集
| 用語 |
定義 |
重要かどうか |
|---|---|---|
|
CUDA コア |
標準の NVIDIA 並列処理ユニット。 |
はい。CUDA コアの数は、NVIDIA GPU 処理能力の基準になります。CUDA コアが多いほど、VisionPro Deep Learning の処理および学習速度が向上します。 |
|
ECC メモリ |
誤り訂正符号 (ECC) メモリとは、メモリの読み書きに誤りが含まれていないことを検証するためのハードウェアサポートを意味します。 |
いいえ。ニューラルネットワークの学習および処理に伴う大量の計算により、ツールの結果に影響を及ぼすメモリエラーの可能性は非常に低くなります。 |
|
TCC |
Tesla Compute Cluster (TCC) ドライバモード NVIDIA GPU を計算に使用するために最適化された高性能ドライバ。 TCC に関する考慮事項:
|
はい。可能な場合には必ず、TCC ドライバモードをサポートするカードを選択して有効にする必要があります。 |
|
Tensor コア |
行列乗算演算専用の完全適合率、混合適合率 (最終的には整数演算) 並列処理ユニット。 |
はい。VisionPro Deep Learning バージョン 3.2.0 で導入され、標準またはアドバンスライセンスがある場合は、VisionPro Deep Learning で処理および学習速度を向上させるために Tensor コアが自動的に利用されます。 |
|
TensorRT |
Tensor コアを搭載した GPU で実行されている TensorFlow、Caffe、および他の標準フレームワークネットワークのランタイムパフォーマンスを (低適合率および整数演算を使用して) 最適化するための NVIDIA フレームワーク。 |
いいえ。VisionPro Deep Learning は、TensorRT と互換性がない独自のネットワークアーキテクチャを使用します。 |
GPU の割り当て
High Detail モードの GPU リソースの割り当てロジックには、わずかですが重要な違いがあります。このページの説明の便宜上、ここでは、High Detail モードとフォーカスモードそれぞれに次のツールを含めるものとします。この「High Detail Quick モードを High Detail モードファミリに含める」という定義は、このドキュメントだけのものです。
High Detail モード
-
解析 (赤) High Detail
-
分類 (緑) High Detail
-
分類 (緑) High Detail Quick
フォーカスモード
-
解析 (赤) フォーカススーパーバイズド
-
解析 (赤) フォーカスアンスーパーバイズド
-
読み取り (青)
-
位置決め (青)
-
分類 (緑) フォーカス
High Detail モード
High Detail モードのツールの場合、GPU リソースはツール単位でロックされます。
-
1 個のツールの学習 (すべての画像を 1 個のツールで学習) が 1 個の GPU を占有します
-
1 個のツールの処理 (すべての画像を 1 個のツールで処理) が 1 個の GPU を占有します
つまり、High Detail モードのツールが学習または処理のために GPU デバイスを占有すると、この GPU はロックされ、High Detail モードのツールが学習または処理ジョブを完了するまで他のツールは使用できなくなります。
N 個の High Detail モードのツールと 1 個の GPU がある場合、N 個の High Detail モードのツールが順番に 1 個の GPU を占有します (先入れ先出し)。1 個のツールが学習または処理ジョブのためにこの GPU を占有すると、他のすべてのツールは、ジョブの実行が完了するまでキューで待機します。新しい学習または処理ジョブを実行すると、このジョブはキューの最後に追加されます。
High Detail モードのツールチェーン
High Detail モードのツールチェーンの場合、前述の GPU 割り当ての原則が同様に適用されます。ただし、常に親ツール (上流のツール) を先に学習させ、次に子ツール (下流のツール) を学習させます。子ツールの間でも、前述の原則がそのまま適用されます。
たとえば、親ツールが 1 個、子ツールが 2 個ある場合、このツールチェーンの学習は順番に実行されます。常に、親ツールを先に学習させます。
1 個の GPU を使用した High Detail モードのツールチェーンの学習
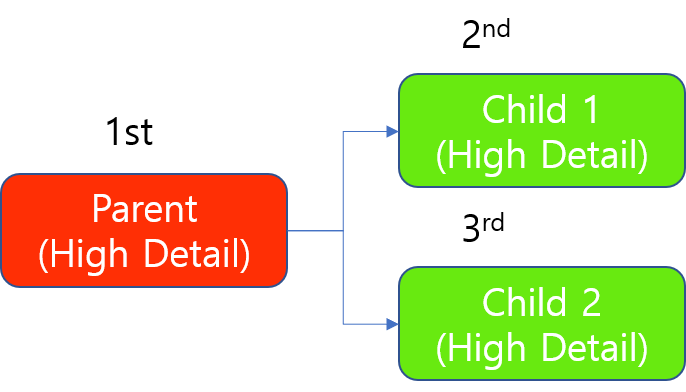
GPU リソースが 1 個の場合、処理時は常に親が先に処理されます。そして、High Detail ツールの処理は「ツール単位」で GPU を占有するため、1 個の子が先に処理されます。他の子は、最初の子ツール (この子ツールで処理されるすべての画像) の処理が完了した後に処理されます。
1 個の GPU を使用した High Detail モードのツールチェーンの処理 (学習と同じ)
フォーカスモード
フォーカスモードのツールの場合、GPU リソースは、学習ジョブではツール単位で、処理ジョブでは画像単位でロックされます。
-
1 個のツールの学習 (すべての画像を 1 個のツールで学習) が 1 個の GPU を占有します
-
1 つの画像の処理 (単一の画像をいずれかのツールで処理) が 1 個の GPU を占有します
つまり、フォーカスモードのツールが学習のために GPU デバイスを占有すると、この GPU はロックされ、フォーカスモードのツールが学習ジョブを完了するまで他のツールは使用できなくなります。
N 個のフォーカスモードのツールと 1 個の GPU がある場合、N 個のフォーカスモードのツールが順番に 1 個の GPU を占有します (先入れ先出し)。1 個のツールが学習ジョブのためにこの GPU を占有すると、他のすべてのツールは、ジョブの実行が完了するまでキューで待機します。新しい学習ジョブを実行すると、このジョブはキューの最後に追加されます。
ただし、フォーカスモードのツールが処理のために GPU デバイスを占有した場合は、この GPU がロックされるのは、1 つの画像の処理が終了するまでです。その画像の処理が終了するとすぐに (通常はほとんど時間がかかりません)、他のツール (ほとんどはキューの先頭で待機していたツール) がこの GPU を占有できます。
フォーカスモードのツールの処理も FIFO キューを使用し、あるツールが処理ジョブのためにこの GPU を占有すると、他のすべてのツールは、1 つの画像の処理が終了するまでキューで待機します (N 個のフォーカスモードのツールを処理する場合)。ただし、画像の処理時間は一般的に非常に短いため、N 個のフォーカスモードのツールがこの GPU を順番に占有します。
-
新しい学習ジョブを実行すると、そのジョブは FIFO キューに追加され、いずれかのタイミングですべての画像の学習ジョブが完了するまで GPU リソースを長時間占有することになります。
-
新しい処理ジョブを実行すると、そのジョブは FIFO キューに追加され、このツールの 1 つの画像を処理する間だけ GPU リソースを占有し、GPU を解放して、次に再びこの GPU または別の GPU を占有してこのツールの別の画像の処理 (別の処理ジョブ) を行うことになります。このツールに属するすべての画像の処理が完了するまで、これが繰り返されます。
フォーカスモードのツールチェーン
フォーカスモードのツールチェーンの場合、前述の GPU 割り当ての原則が同様に適用されます。ただし、常に親ツール (上流のツール) を先に学習させ、次に子ツール (下流のツール) を学習させます。子ツールの間でも、前述の原則がそのまま適用されます。
たとえば、親ツールが 1 個、子ツールが 2 個ある場合、このツールチェーンの学習は順番に実行されます。常に、親ツールを先に学習させます。
1 個の GPU を使用したフォーカスモードのツールチェーンの学習
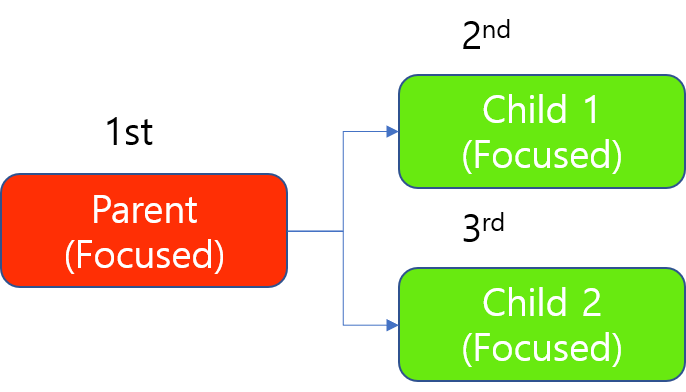
処理時は、常に親が先に処理されますが、フォーカスツールの処理は「画像単位」で GPU を占有するため、1 個の GPU を使用している場合でも、この GPU は 2 個の子ツールのいずれかの画像の処理が終了した瞬間にロックが解除されるので、2 個の子を同時に処理できます。
1 個の GPU を使用したフォーカスモードのツールチェーンの処理
(フォーカスモードのツールの処理では、そのツールで処理するすべての画像ではなく、1 つの画像を処理する間だけ GPU を占有するため、2 個の子が交代で 1 個の GPU を占有します):
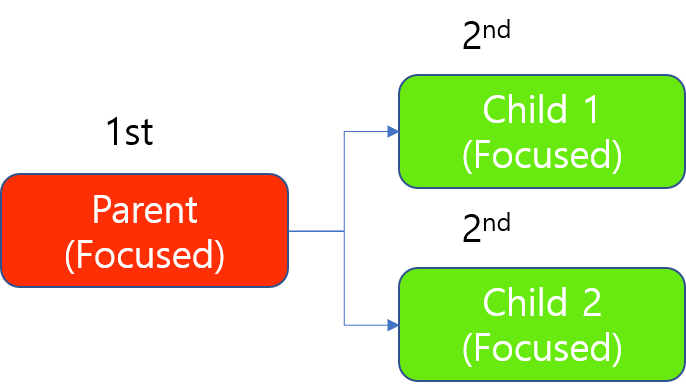
割り当ての優先度
-
High Detail モード > フォーカスモード
ストリームに High Detail モードとフォーカスモードの両方のツールがある場合、High Detail モードはフォーカスモードより処理の優先度が高いため、High Detail ツールがフォーカスモードより先に GPU をロックします。そして、フォーカスモードツールは、High Detail ツールによってロックされていない GPU を占有しようとします。