处理神经网络(推断)
在运行时,使用工具训练的网络单独处理运行时图像的每个样本,并获得每个样本的单独网络响应。网络响应表示为概率图,其中输入图像的采样区域中的每个像素被分配概率。概率图的含义取决于使用的工具。对于红色分析聚焦监督,响应是采样区域每个像素(即像素在图像缺陷内)的概率。这些全图像概率图由单个样本的插值网络响应组合而成。返回给用户的最终结果(特征姿势和标识以及缺陷区域)基于用户通过为缺陷概率指定阈值进行控制的结果形成流程。
在上述背景中,务必要理解工具返回的概率可能无法很好地反映我们对某种判断可能性的认知。这主要是因为这些工具具有“有限的世界视角”,因此无法返回与人类广泛而丰富视觉体验有关的概率,而只能涵盖其非常有限的若干类的视觉世界。
当训练完成而没有问题时,训练的工具的处理(推断)被自动执行。如果您希望手动重新处理训练工具,请单击 ![]() 按钮。
按钮。
用于处理的特征采样
在运行时对每个输入图像进行穷举采样,然后由训练的网络处理各个样本。运行时还使用与训练时所用相同大小的特征(确保训练网络正在处理的输入与训练使用的输入保持一致)。
与训练时自动确定采样密度不同,您可以控制所有 Deep Learning 工具的采样密度。采样密度决定相邻样本之间的重叠程度。采样密度为 1 意味着采样位置增加了采样之间的特征尺寸。大多数工具的默认采样密度为 3,即采样位置增加特征尺寸的三分之一。
| 采样密度= 1(4 个样本) | 采样密度= 3(4 个样本) |
|---|---|
|
|
|

配置处理参数
The Processing parameters control the way that images are processed by the tool. This is often called ‘inference’ in deep learning. Processing with the same models will always give you the same results. Changing these parameters does not require the tool to be retrained; the effect can be seen right away by reprocessing the database.要重新处理工具,请单击 ![]() 按钮。
按钮。
| 参数 | 说明 | ||||
|---|---|---|---|---|---|
|
采样密度 |
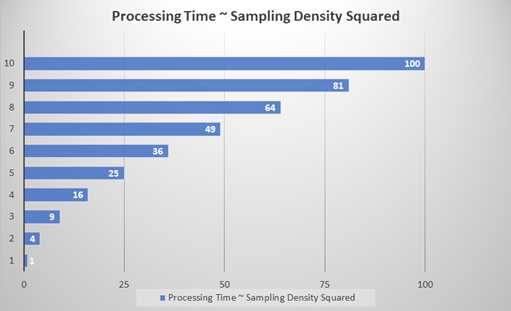
指定相对于工具特征尺寸 (FS) 设置的采样点密度。采样密度决定相邻样本之间的重叠程度。采样率为 1 意味着采样位置增加了采样之间的特征尺寸。大多数工具的默认采样率为 3,即采样位置增加特征尺寸的三分之一。 Tip: 采样密度参数的一个关键方面是工具的处理时间和精度之间的关系。工具的处理时间大约取决于采样密度 (Sd) 值的二次方。例如,采样密度设置为 1 比设置为 3 大约快九倍 (n2)。虽然较高的采样密度设置更准确,但这会显著影响工具的处理时间。
|
||||
|
阈值 |
共有两种设置 T1 和 T2(表示为 [T1,T2])。它们确定判断是否检测到区域并将其标记为良好或不良的阈值。值低于 T1 将被分类为良好,高于 T2 将被分类为不良。T1 和 T2 值也可以使用数据库概述中的分数图形进行交互式设置。 |
||||
| 自动 | 启用自动(自动阈值)时,将计算阈值 T1 和 T2,这两个值通过遵循下拉菜单中的每个标准使数据库概述上混淆矩阵的 F1 得分最大化。这 4 个标准与数据库概述上计数菜单中的标准相同。有关更多信息,请参阅分数计数筛选工具。 | ||||
|
简单区域 |
指定工具仅应提取“简单区域”,换句话说,就是无孔的多边形。 |
||||
|
为工具指定筛选条件,用作找到区域的标准。通过指定筛选条件,将从结果中删除与筛选条件不匹配的区域。如果参数保留为空,则将返回所有区域。 Note: 筛选条件的语法与用于显示筛选条件的语法相同。有关构建筛选条件语法的更多信息,请参阅自定义显示筛选工具。
可用区域属性包括:
|
|||||