NVIDIA GPU Selection and Configuration
PC system configuration choices directly affect tool processing speed without affecting tool accuracy or behavior, and they are the most expensive and hardest to predict the effect of.
| Configuration Option | Why it's faster | Best value option | Watch out for... |
|---|---|---|---|
|
NVIDIA device type |
The number of CUDA cores is directly related to high-precision processing speed and training. The number of standard Tensor cores is directly related to processing speed and training speed. The number of Tensor cores is related to processing speed in low-precision mode only. These cores do not affect standard precision processing or training speed. |
||
|
NVIDIA driver mode |
Consumer-grade gaming-oriented NVIDIA devices only support the WDDM device driver model. This driver is intended to support graphics display, not computation. Professional-grade NVIDIA cards support the TCC driver mode, which provides better performance and stability. |
Select a NVIDIA RTX / Quadro® or Tesla (or selected Titan)-branded NVIDIA card. |
If using a GeForce-branded card, be aware that NVIDIA drivers are updated frequently and may not be compatible with Deep Learning. Using TCC mode driver prevents the use of Video output on the GPU card; use onboard video instead. |
|
Optimized memory |
Deep Learning optimized memory, which is enabled by default, improves performance by overriding the standard NVIDA GPU memory management system. |
Make sure your card has at least 4GB of GPU memory. Performance improvement is not as significant for cards using the TCC driver. |
|
NVIDIA Device Branding Summary
The following table summarizes the different NVIDIA device types:
| Class | Consumer | Professional | ||
|---|---|---|---|---|
|
Family |
Low-End Gaming |
High-End Gaming |
Workstation |
Data Center |
|
Branding |
GeForce |
Titan |
NVIDIA RTX / Quadro® |
Tesla |
|
Volta Architecture Cards |
None |
Titan V |
GV100 |
V100 |
|
Pascal Architecture Cards |
GTX 1xxx |
Titan Xp |
G/GPxxx |
P100 |
|
Turing Architecture Cards |
RTX 2xxx |
Titan RTX |
Quadro RTX4xxx |
T4 |
|
Ampere Architecture Cards |
RTX 3xxx |
Titan RTX 2nd Gen. (not released yet) |
Axxx | Axxx |
|
Video Output |
Yes |
Yes |
Yes |
No |
|
Price Point |
~$1K |
~$3K |
~$5K |
~$5K+ |
|
Supports TCC Driver |
No |
Yes |
Yes |
Yes |
|
ECC Memory |
No |
No |
Yes |
Yes |
|
Tensor Cores |
|
|
|
|
Glossary of NVIDIA GPU Terminology
| Term |
Definition |
Importance |
|---|---|---|
|
CUDA Core |
The standard NVIDIA parallel processing unit. |
YES. The number of CUDA cores is the standard measure of NVIDIA GPU processing. The more CUDA cores, the faster the VisionPro Deep Learning processing and training. |
|
ECC Memory |
Error correcting code (ECC) memory involves hardware support for verifying that memory read/writes do not contain errors. |
NO. Due to the huge number of computations involved in training and processing neural networks, the likelihood of a memory error affecting a tool result is very low. |
|
TCC |
Tesla Compute Cluster (TCC) driver mode A high-performance driver that is optimized for computational use of an NVIDIA GPU. TCC considerations:
|
YES. Whenever possible, you should select cards that support the TCC driver mode, and they should be enabled. |
|
Tensor Core |
Full-precision, mixed-precision (and eventually integer math) parallel processing unit that is dedicated to matrix multiply operations. |
YES. Introduced in version VisionPro Deep Learning 3.2.0, VisionPro Deep Learning automatically takes advantage of Tensor Cores for faster processing and training, as long as the user has a Standard or Advanced license. |
|
Tensor RT |
The NVIDIA framework for optimizing (by using low-precision and integer math) runtime performance of TensorFlow, Caffe and other standard framework networks running on a GPU with Tensor Cores. |
NO. VisionPro Deep Learning uses a proprietary network architecture that is not compatible with Tensor RT. |
GPU Allocation
There is a slight but important difference between the allocation logic of GPU resources of High Detail modes. For convenience of further explanation on this page, here High Detail modes and Focused modes each include the following tools. This definition of including High Detail Quick modes within High Detail Modes family stands only for this page in this document.
High Detail Modes
-
Red Analyze High Detail
-
Green Classify High Detail
-
Green Classify High Detail Quick
Focused Modes
-
Red Analyze Focused Supervised
-
Red Analyze Focused Unsupervised
-
Blue Read
-
Blue Locate
-
Green Classify Focused
High Detail Mode
For High Detail mode tools, a GPU resource is locked on a tool basis:
-
Training 1 Tool (all images to be trained in a tool) a solely occupies 1 GPU
-
Processing 1 Tool (all images to be processed in a tool) a solely occupies 1 GPU
This means that when a High Detail mode tool occupies a GPU device for training or processing, this GPU is locked so that it cannot be utilized by any other tool until our High Detail mode tool finishes its training or processing job.
If there are N High Detail mode tools and 1 GPU, these N High Detail mode tools sequentially occupy 1 GPU (First In First Out). Once a tool occupies this GPU for its training or processing job, all the other tools wait in a queue until the running job is finished. If you execute a new training or processing job, this job is added to the end of the queue.
Tool Chain of High Detail modes
For a tool chain of High Detail modes, the above principle of GPU allocation applies in the same way except that the parent tool (the upstream tool) is always trained first and then the child tool (the downstream tool) is trained. Among the children, the above principle applies as it is.
For example, where there are 1 parent tool and its 2 children tools, the training of this tool chain is done sequentially. The parent always should be trained first.
Training a Tool Chain of High Detail modes with 1 GPU
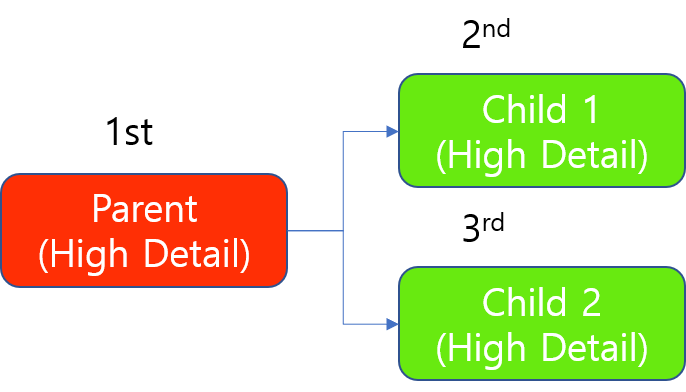
When processing, the parent always should be processed first, and since the processing of a High Detail tool occupies a GPU on "tool basis", 1 child is processed first when there is a single GPU resource. The other child is processed after the processing of this child tool (all images to be processed in this child tool) is done.
Processing a Tool Chain of High Detail modes with 1 GPU (Same as Training)
Focused Mode
For Focused mode tools, a GPU resource is locked on a tool basis for training job but an image basis for processing job:
-
Training 1 Tool (all images to be trained in a tool) a solely occupies 1 GPU
-
Processing 1 Image (a single image to be processed from any tool) solely occupies 1 GPU
This means that when a Focused mode tool occupies a GPU device for training, this GPU is locked so that it cannot be utilized by any other tool until our Focused mode tool finishes its training job.
If there are N Focused mode tools and 1 GPU, these N Focused mode tools occupy 1 GPU sequentially (it is still First In First Out). Once a tool occupies this GPU for its training job, all the other tools waits in a queue until the running job is finished. If you execute a new training job, this job is added to the end of the queue.
However, when a Focused mode tool occupies a GPU device for processing, this GPU is locked only until it finishes processing on an image. This GPU can be occupied by any other tool (mostly the tool that has been waiting up front in a queue) right away as soon as it finishes processing for an image, which normally takes very little time.
Processing Focused mode tools also uses a FIFO queue so that once a tool occupies this GPU for its processing job, all the other tools wait in a queue until the processing of an image is finished, given that there are N Focused mode tools to be processed. But as the processing time for an image is generally very short, the N Focused mode tools occupy this GPU in rotation.
-
If you execute a new training job, this job will be added to a FIFO queue and soon or later might occupy a GPU resource for long until the training job for all its images is completed.
-
If you execute a new processing job, this job will be added to a FIFO queue and might occupy a GPU resource only for a while until the processing of an image of this tool is done, release this GPU, and occupy this or another GPU for the processing of another image of this tool (another processing job), again. It will repeat this until all the images that belong to this tool are done processing.
Tool Chain of Focused modes
For a tool chain of Focused modes, the above principle of GPU allocation applies in the same way except that the parent tool (the upstream tool) is always trained first and then the child tool (the downstream tool) is trained. Among the children, the above principle applies as it is.
For example, where there are 1 parent tool and its 2 children tools, the training of this tool chain is done sequentially. The parent always should be trained first.
Training a Tool Chain of Focused modes with 1 GPU
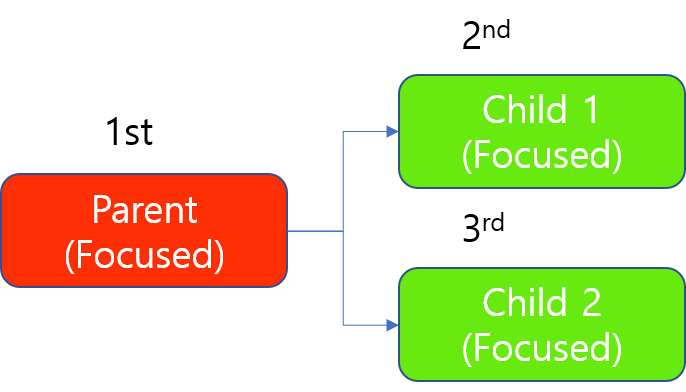
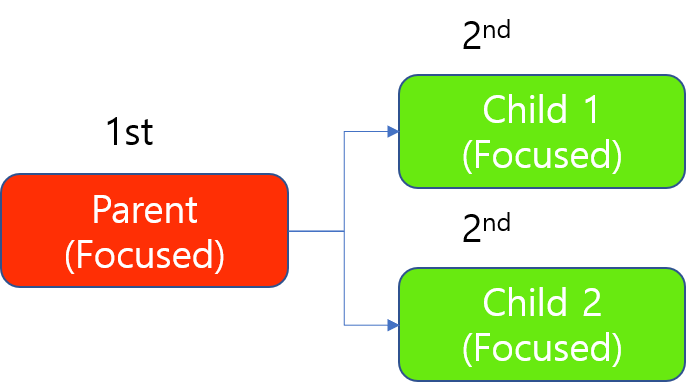
When processing, the parent always should be processed first, but since the processing of a Focused tool occupies a GPU on "image basis", 2 children can be processes simultaneously even with a single GPU, as this GPU releases its lock on the moment it finishes processing of an image that came from either of 2 children tools.
Processing a Tool Chain of Focused modes with 1 GPU
(2 Children take turns to occupy 1 GPU as processing a Focused mode tool occupies a GPU for processing 1 image, not for processing all images to be processed in this tool):
Allocation Priority
-
High Detail Mode > Focused Mode
When your stream has both High Detail Mode and Focused mode tools, High Detail mode has the priority of processing compared to Focused mode and so High Detail tools lock the GPU before Focused mode. Then, Focused mode tools try to occupy GPUs that are not locked by High Detail tools.