 Selecting Text to Read
Selecting Text to Read
The following guidelines and considerations can help you achieve consistent results:
- Use special fonts designed for OCR/OCV applications.
- Ensure that the characters are at least 5 pixels per stroke width. The goal should be to have the characters fill as much of the image as possible. The more pixels per character, the higher the accuracy of the tool, though the execution will also take slightly longer.
- If you have multiple types of fonts in your image, use a separate Read Text Identification Tool for each type of font.
- If you have multiple font sizes in your image, use a separate Read Text Identification Tool for each size.

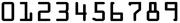
- Use high resolution characters to create clear and distinct Character Models.
- A single Read Text Identification Tool supports up to 255 Character Models, and each Character Model is based on up to 8 trained instances of that Character Model. Training additional instances of a Character Model increases the tool's tolerance to variations in the Character Model. If your application doesn't tolerate much variation, only train your Character Models on a single, good example. If your application needs to tolerate variations, train the Character Model against as many of the possible instances.
- When training instances of a Character Model, ensure that the print of the characters is as consistent as possible, as dramatic changes to a character's shape and size create poor Character Models and fail during run-time.

Good training instances of a Character Model.

Bad training instances of a Character Model.