OCRMaxSettings
OCRMax 関数のセグメント化、分類の詳細設定、フィールド化といった外部設定値。実行時に調整できます。この関数は設定値をプログラムで制御し、リモートデバイスからのパラメータの調整をサポートします。
OCRMaxSettingsの入力パラメータ
Syntax:OCRMaxSettings(セグメント化.文字の極性,セグメント化.文字幅のタイプ,セグメント化.文字幅の最小値,セグメント化.文字幅の最大値を使用,セグメント化.文字幅の最大値,セグメント化.文字の高さの最小値,セグメント化.文字の高さの最大値を使用,セグメント化.文字の高さの最大値,セグメント化.最小文字アスペクト比を使用,セグメント化.最小文字アスペクト比,セグメント化.角度範囲,セグメント化.スキュー範囲,セグメント化.文字フラグメントマージモード,セグメント化.文字フラグメントの最小オーバーラップ値,セグメント化.最小文字内ギャップ値,セグメント化.最小文字間ギャップ値,セグメント化.最小文字フラグメントサイズ,セグメント化.文字サイズの最小化,セグメント詳細設定.正規化モード,セグメント詳細設定.ストローク幅フィルタを使用,セグメント詳細設定.境界フラグメントを無視,セグメント詳細設定.2 値化しきい値,セグメント詳細設定.文字フラグメントのコントラストしきい値,セグメント詳細設定.メインラインまでの最大フラグメント距離,セグメント詳細設定.セグメント解析モード,セグメント詳細設定.最小ピッチ,セグメント詳細設定.文字ピッチ位置,セグメント詳細設定.文字のピッチタイプ,分類の詳細設定.分類テンプレートサイズ幅,分類の詳細設定.分類テンプレートサイズの高さ,分類の詳細設定.文字のアスペクト比を保持,分類の詳細設定.追加の文字検証をスキップ,分類の詳細設定.画像前処理,フィールド化.フィールド化していない文字を無視,フィールド化.文字列長,フィールド化.最大文字列長,フィールド化.最小文字列長,フィールド化.最初にフィールド化した最大インデックス値,フィールド化.最後にフィールド化した最小インデックス値)
| セグメント化 |
セグメント分割の実行に使用されるパラメータ設定を指定します。

|
文字の極性
|
入力画像内の文字の極性を指定します。
注 : 関数のパフォーマンスを改善するには、テキストの極性を指定します。
| 1 = 黒 (白い背景) |
テキストの極性は、白い背景に黒い文字です。 |
| 2 = 白 (黒い背景) |
テキストの極性は、黒い背景に白い文字です。 |
| 4 = 自動 (デフォルト) |
この関数は、テキストと背景の極性を自動的に決定します。 |
|
|
文字幅のタイプ
|
フォントの文字幅の変動方法を指定します。これにより、文字フラグメントをマージするか、分割するかが決定されます。
注 : 文字幅は文字領域 (例: インクの境界ボックス) の幅です。 ROI ではありません (ROI には通常、文字矩形のまわりのパディングも含まれます)。
| 1 = 自動 (デフォルト) |
文字の幅は不明です。このフォントの幅は固定、またはプロポーショナルである可能性があります。指定した最大文字幅よりも広い文字フラグメントは、関数によって決定された文字フラグメントの分割に最適な位置に基づき、個々の文字に分割されます。各文字の幅が同じになるとは限りません。 |
| 2 = 固定 |
フォントの文字領域はすべて同じ幅をしています。指定した最大文字幅よりも広い文字フラグメントは、個々の文字に分割されます。各文字の幅は同じになります。 |
| 4 = 可変 |
フォントの文字の文字領域の幅は一定ではない可能性があります。指定した最大文字幅よりも広い文字フラグメントは、関数によって決定された文字フラグメントの分割に最適な位置に基づき、個々の文字に分割されます。各文字の幅が同じになるとは限りません。 |
|
|
文字幅の最小値
|
文字領域の最小の幅をピクセル単位で指定します (1 ~ 1000、デフォルト = 3)。この値以上の幅を持つ文字がレポートの対象となります。この設定によって、背景ノイズまたはそのほかのテキスト以外の特徴をフィルタ処理することができます。

|
|
文字幅の最大値を使用
|
文字幅の最大値を制限するかどうかを指定します。この設定は、文字フラグメントを分割するか、マージするかを決定する場合に有効です。文字フラグメントを分割する必要がある場合は、[文字幅のタイプ] パラメータで使用する適切な方法を決定します。
| 0 = OFF (デフォルト) |
この関数は、文字の文字領域の幅について、許容される最大値を考慮しません。 |
| 1 = ON |
この関数は、文字領域の幅について、許容される最大値を考慮します。有効な場合、指定された値よりも広い幅を持つ文字は、幅が広すぎないように、いくつかに分割されます。 |
|
|
文字幅の最大値
|
文字の文字領域について、許容される最大の幅をピクセル単位で指定します (1 ~ 5000、デフォルト = 100)。
注 : この設定は、[文字幅の最大値を使用] パラメータが有効化されている場合のみ使用可能です。
|
|
文字の高さの最小値
|
文字領域の最小の高さをピクセル単位で指定します (1 ~ 1000、デフォルト = 3)。この値以上の高さを持つ文字がレポートの対象となります。この設定によって、背景ノイズまたはそのほかのテキスト以外の特徴をフィルタ処理することができます。

|
|
文字の高さの最大値を使用
|
この関数で、文字の高さの最大値を有効にするかどうかを指定します。この値の使い方には 2 通りあります。この値は、まず、垂直方向に隣り合うノイズや文字が縦に並んだ行を拒否するなどのために行全体を検出するときに使用します。また、この値を上回る高さを持つ文字は、この高さに合わせてトリミングされます。
| 0 = OFF (デフォルト) |
文字の高さの最大値を考慮しません。 |
| 1 = ON |
文字の高さの最大値を考慮します。 |
|
|
文字の高さの最大値
|
文字の文字領域について、許容される最大の高さをピクセル単位で指定します (1 ~ 5000、デフォルト = 100)。
注 : この設定は、[文字の高さの最大値を使用] パラメータが有効化されている場合のみ使用可能です。
|
|
最小文字アスペクト比を使用
|
文字のアスペクト比の最小許容可能値を考慮に入れるかどうかを指定します。アスペクト比は、文字列全体の高さ/文字列を囲む矩形の幅です。
| 0 = OFF |
文字のアスペクト比の最小許容可能値を考慮に入れません。 |
| 1 = ON (デフォルト) |
文字のアスペクト比の最小許容可能値を考慮に入れます。アスペクト比がこの値よりも小さい (幅が広すぎる) 文字は、複数のセグメントに分割されます。 |
|
|
最小文字アスペクト比
|
1 文字につき許容できる最小アスペクト比 (0 ~ 500、デフォルト = 80) を指定します。この設定値は、文字の行の高さ全体を使用した最大文字幅を間接的に設定する際に使用することができます。この最大幅は、行の高さを [最小文字アスペクト比] の値で割った値と同じになります。このパラメータで許可される幅よりも広い文字フラグメントはマージされず、分割されて、複数のフラグメントを形成します。この文字フラグメントは、幅が広すぎないように [文字幅のタイプ] パラメータによって制御されます。
注 : この設定は、[Use Minimum Character Aspect Ratio] パラメータが有効化されている場合のみ使用可能です。
|
|
角度範囲
|
角度のサーチ範囲 (0 ~ 45、デフォルト = 0) を度単位で指定します。
注 : テキスト行に角度の回転または傾きがある場合、その角度または傾きが各画像で一定の場合は、[領域] を設定してこれらのばらつきを補正します。0 を超える任意の値を指定すると、セグメントプロセスの処理時間が長くなります。
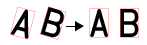
|
|
スキュー範囲
|
スキューのサーチ範囲 (0 ~ 45、デフォルト = 0) を度単位で指定します。
注 : テキスト行に角度の回転または傾きがある場合、その角度または傾きが各画像で一定の場合は、[領域] を設定してこれらのばらつきを補正します。0 を超える任意の値を指定すると、セグメントプロセスの処理時間が長くなります。
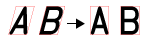
|
|
文字フラグメントマージモード
|
分割された文字フラグメントを結合して文字を形成するときのマージ (結合) 方法を指定します。2 つの文字フラグメントを 1 文字の一部としてみなすためにオーバーラップする必要があるかどうか、または、間に水平ギャップのある文字フラグメントを 1 文字の一部としてみなすかどうかを決定します。
| 1 = 要オーバラップ (デフォルト) |
文字フラグメントは、[文字フラグメントの最小オーバーラップ値] パラメータの値を基準にして水平にオーバーラップする必要があります。 |
| 2 = 最小文字間ギャップ値に設定 |
文字の断片と断片の間に水平方向のギャップがある場合、これらの断片がマージされ、文字が形成されることがあります。[最小文字間ギャップ値] パラメータで定義された値未満のギャップを持つ 2 つの断片はマージされます。 |
| 4 = 最小文字間ギャップ値/最大文字間ギャップ値に設定 |
文字の断片と断片の間に水平方向のギャップがある場合、これらの断片がマージされ、文字が形成されることがあります。2 つの断片をマージするかどうかは、[最小文字間ギャップ値] パラメータと [最大文字内ギャップ値] パラメータで定義された値に基づいて判断されます。 |
|
|
文字フラグメントの最小オーバーラップ値
|
2 つの文字断片が同じ文字の一部とみなされるためには、この文字断片が相互に水平方向にオーバーラップしていなければなりませんが、その最小の割合を指定します (0 ~ 100、デフォルト = 0)。デフォルト値 (0) は 1 ピクセル以上オーバーラップする任意の 2 文字の断片をマージします。これよりも大きい値の場合、文字断片はより多くオーバーラップする必要があります。一部の文字のペアを水平方向に意図的にオーバーラップさせるアプリケーションや (カーニングとも呼ばれます)、最適化段階において回転や傾きを完全に修正できなかった場合は (通常、印刷が一定ではないため)、デフォルト値が必要になります。
|
|
最大文字内ギャップ値
|
損傷している文字であっても、1 つの文字の中で起こり得る水平方向のギャップの最大サイズをピクセル単位で指定します (0 ~ 1000、デフォルト = 5)。
注 : 隣り合う文字間に発生するギャップが損傷した文字内に発生する可能性のあるギャップよりも常に広い、最も一般的なアプリケーションの場合は、[最小文字間ギャップ値] パラメータを [最大文字内ギャップ値] パラメータの値に 1 を足して設定します。例えば、文字の内部に水平ギャップが発生することのない場合は、[最大文字内ギャップ値] パラメータに 0 を設定し、[最小文字間ギャップ値] パラメータに 1 を設定します。

|
|
最小文字間ギャップ値
|
異なる文字に属するために、2 つの文字断片の間に必要な水平方向のギャップの最小サイズをピクセル単位で指定します (0 ~ 1000、デフォルト = 0)。このギャップは、ある文字の文字領域の右端から、その隣の文字の文字領域の左端までの距離です。2 つの断片の間のギャップがこの値よりも小さい場合、これらの断片は同じ文字の一部であるとみなされます。ただし、結合後の文字幅が広くなりすぎる場合は例外です ([文字幅の最大値] または [最小文字アスペクト比] パラメータの指定を参照)。
注 : 隣り合う文字間に発生するギャップが損傷した文字内に発生する可能性のあるギャップよりも常に広い、最も一般的なアプリケーションの場合は、[最小文字間ギャップ値] パラメータを [最大文字内ギャップ値] パラメータの値に 1 を足して設定します。例えば、文字の内部に水平ギャップが発生することのない場合は、[最大文字内ギャップ値] パラメータに 0 を設定し、[最小文字間ギャップ値] パラメータに 1 を設定します。

|
|
最小文字フラグメントサイズ
|
前景 (つまり、テキスト) ピクセルの最小値を指定します (0 ~ 1000、デフォルト = 15)。前景のピクセル値がこの値を超えていれば、その文字断片は文字の一部であるとみなされます。この値を設定する際は、本物のテキスト断片を保持できるくらい小さい値に設定する必要がありますが、同時に、背景ノイズから小さな断片を除外できるくらい大きくします。ドットマトリックステキストや、ピリオドなどの小さい文字を含むテキストについては、小さい値が必要になります。文字が複数の小さな断片に分割されにくい文字で形成された、途切れのないストロークテキストの場合は、大きい値が必要になります。
|
|
文字サイズの最小値
|
前景 (つまり、テキスト) ピクセルの最小値を指定します (0 ~ 5000、デフォルト = 30)。前景のピクセル値がこの値以上である 2 値化文字がレポートの対象となり、ピクセル値が少ない文字は破棄されます。この設定によって、背景ノイズまたはそのほかのテキスト以外の特徴をフィルタ処理することができます。
|
|
| セグメント詳細設定 |
セグメントプロセスに適用される追加パラメータを指定します。
|
正規化モード
|
画像の正規化に使用するモードを指定します。このモードは背景のばらつきを除去し、グレースケールの 256 の値 (0 ~ 255) をすべて使用します。
注 : この設定は、登録時と実行時の両方で同じでなければなりません。登録後にこの設定を変更すると、分類で問題が発生する原因となる可能性があります。
| 1 = なし |
正規化は行われません。 |
| 2 = グローバル |
ローカルなばらつきではなく、ROI 全体の情報を使用して、グローバルな正規化が実行されます。このオプションは背景色とテキストが ROI 全体を通して一定であり、高速モードのときに最適に機能します。 |
| 4 = ローカル (デフォルト) |
画像を正規化するために、ROI 内のローカルな文字領域に関する情報を使用して、ローカルな正規化を実行します。このオプションは背景の勾配を除去します。グローバルモードが機能しない場合に使用する必要があります。 |
| 8 = ローカル詳細設定 |
画像を正規化するために、ROI 内のローカルな文字領域に関する情報を使用して、背景だけではなく、前景のコントラストの調整を含むローカルな正規化を実行します。このオプションは背景の勾配を除去し、一定でないテキストのコントラストを調整します。3 つのオプションのうち、実行時間が最も長くかかります。 |
|
|
ストローク幅フィルタを使用
|
残りの画像と同じストローク幅を持たないものをすべて、正規化された画像から削除するかどうかを指定します。このオプションは、近くの文字と接続する可能性のある薄い線などのテキスト以外の特徴について、一部の種類を削除することができます。このオプションによって、2 値化しきい値を超えて偽のフラグメントを作成したり、近くの文字と連結したりする可能性のある、低コントラストの背景のばらつきを除去することもできます。ただし、テキストに一定のストローク幅がない場合や、テキストに大きな可変コントラスト (ストロークの一部が非常に薄いなど) がある場合は、このオプションを使用することによって問題が発生することがあります。
注 : この設定は、登録時と実行時の両方で同じでなければなりません。登録後にこの設定を変更すると、分類で問題が発生する原因となる可能性があります。
| 0 = OFF |
画像にある残りの断片と同じストローク幅を持たないものをすべて、画像から削除しません。 |
| 1 = ON (デフォルト) |
画像にある残りの断片と同じストローク幅を持たないものをすべて、画像から削除します。 |
|
|
境界フラグメントを無視
|
関数が、ROI の境界線に接触する断片をすべて、完全に無視するかどうかを指定します。ラベルのエッジなど、ROI の範囲に含まれる可能性のあるテキスト以外の特徴については、このような断片を無視することが有用です。
注 : 断片が、文字領域の境界からテキストのメインラインまで伸びている場合、この断片は 1 つの文字とみなされます。このパラメータが有効化されているとき、除外されるテキストのメインラインまで断片が伸びていてはいけません。
| 0 = OFF (デフォルト) |
境界線の断片を無視しません。 |
| 1 = ON |
境界線の断片を無視します。 |
|
|
2 値化しきい値
|
正規化された画像において、テキストと背景の間で画像をバイナリ化するしきい値の計算に使用します。単位はパーセンテージ (0 ~ 100、デフォルト = 50) で指定します。例えば、デフォルト設定の 50% は約 128 (0 ~ 255 のグレースケール範囲で) の 2 値化しきい値を生成します。このとき、0 は白いテキスト上の黒と同じで、100 は黒いテキスト上の白と同じです。50% 未満の値を使用すると 2 値化しきい値が変更され、テキストがより少なく、背景がより広くなります。一方、50% より大きい値を使用すると、背景がより少なく、テキストがより多くなります。通常、デフォルト値は画像を正しく 2 値化しますが、背景テクスチャがある場合、またはそのほかの背景のばらつきがある場合は、この値を小さくすることで背景のばらつきを補正することができます。
注 : この設定は、登録時と実行時の両方で同じでなければなりません。登録後にこの設定を変更すると、分類で問題が発生する原因となる可能性があります。
|
|
文字フラグメントのコントラストしきい値
|
正規化された画像のしきい値に対するコントラストの最小値を、断片全体のグレースケールレベルで指定します (0 ~ 255、デフォルト = 30)。断片のコントラストがこの値を超えていれば、その断片は文字の一部であるとみなされます。断片の各前景ピクセルは常にしきい値を満たすことを保証されますが、断片のすべてのピクセルがしきい値に非常に近いと、断片はテキストではなく、単にノイズとなる可能性が高くなります。値 0 では低コントラストの断片が拒否されるのを妨ぐことができます。
|
|
メインラインまでの最大フラグメント距離
|
テキストを貫通して、水平方向に伸びる「メインライン」から断片を垂直方向に削除する基準となる距離を文字の高さのパーセンテージとして指定します (0 ~ 1000、デフォルト = 0)。本来、文字は最適化された後に (角度方向および傾きを補正する段階)、水平の直線に沿って配置されることが予測されています。しかし、文字に「ジッタ」が見られることがあり、文字位置の縦方向に変動がある可能性があります。デフォルト設定では、これらの文字フラグメントは文字の「メインライン」に沿っていないため、拒否されてしまいます。このパラメータ設定を大きくすることによって、文字の「メインライン」に沿っていないフラグメントを保持することができます。
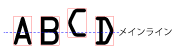
|
|
セグメント解析モード
|
文字の最適なセグメントを実行する文字解析モードのタイプを指定します。このパラメータは、グループステージ以外の追加の解析を実行するかどうかを決定します。
| 1 = 最小 |
基本のセグメント解析を実行します。グループステージ解析のみ実行します。 |
| 2 = 標準 (デフォルト) |
最適なセグメントを決定するために、文字の間隔を含め、行全体の追加の解析を実行します。有効になっている場合、[最小ピッチ値]、[文字のピッチタイプ]、[文字ピッチ位置] パラメータの影響を受けます。 |
|
|
最小ピッチ値
|
2 つの文字の間に発生する可能性のあるピッチの最小値をピクセル単位で指定します (0 ~ 1000、デフォルト = 0)。ピッチは [文字ピッチ位置] パラメータに基づいて計算されます。2 つの断片の間のピッチがこれよりも小さい場合、これらの断片は同じ文字の一部であるとみなされます。ただし、結合後の文字幅が広くなりすぎる場合は例外です([文字幅の最大値] または [最小文字アスペクト比] パラメータの指定を参照)。

|
|
文字ピッチ位置
|
2 つの連続する文字間のピッチの測定方法を指定します。ピッチは、隣り合う文字の対応する点と点の間の (おおよその) 距離として定義されます。ある文字の末尾から隣の文字の始めまでの距離 (文字間ギャップ) ではありません。文字に異なる幅がある固定ピッチフォントでは、通常、適切なピッチメトリクスが使用されている場合のみ、ピッチは一定の値を持ちます。
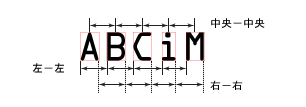
注 : [セグメント解析モード] パラメータが [最小] に設定されている場合、このパラメータは無効になります。
| 1 = 自動 (デフォルト) |
未知のメトリクスが使用されていることを示します。適切なピッチはその他のピッチ位置のいずれかである可能性もありますし、一定のピッチ位置がない可能性もあります (プロポーショナルピッチフォントの場合)。また、OCRMax 関数によって適切なピッチメトリクスが決定されます。 |
| 2 = 左-左 |
ある文字の文字領域の左端から隣の文字の文字領域の左端までの距離を測定したピッチを指定します。
注 : 「左」および「右」という用語は、ROI により定義された座標を基準にしています。つまり、「右」は正の X 方向です。
|
| 4 = 中央-中央 |
ある文字の文字領域の中央から隣の文字の文字領域の中央までの距離を測定したピッチを指定します。 |
| 8 = 右-右 |
ある文字の文字領域の右端から隣の文字の文字領域の右端までの距離を測定したピッチを指定します。
注 : 「左」および「右」という用語は、ROI により定義された座標を基準にしています。つまり、「右」は正の X 方向です。
|
|
|
文字のピッチタイプ
|
連続する文字の文字間隔に 1 つの固定値を確保するか、特定の文字によって異なるのかを指定します。ピッチは、隣り合う文字の対応する点と点の間の (おおよその) 距離として定義されます。ある文字の末尾から隣の文字の始めまでの距離 (文字間ギャップ) ではありません。
注 : [セグメント解析モード] パラメータが [最小] に設定されている場合、このパラメータは無効になります。
| 1 = 自動 (デフォルト) |
ピッチタイプは不明だが、固定、またはプロポーショナルのどちらかで、可変ではないことを表します。OCRMax 関数によって最適なタイプが決定されます。 |
| 2 = 固定 |
ピッチが固定、つまり任意の 2 文字のピッチは一定であることを表します。たとえば、文字矩形の幅は関係ありません。このピッチは、[文字ピッチ位置] パラメータを基準に測定されます。 |
| 4 = 比例 |
ピッチがプロポーショナルである、つまり任意の 2 文字のピッチはその文字によって異なることを表します。例えば、2 つの小文字「i」の間の距離は、2 つの大文字「M」の間の距離よりもかなり少なくなります。
注 :
- ピッチの計測値は文字列全体を通して一定ではありませんが、通常、文字間ギャップはほぼ一定です (文字間ギャップとは、ある文字の文字領域の右端から、隣の文字の文字領域の左端までの距離です)。
- 「左」および「右」という用語は、ROI により定義された座標を基準にしています。つまり、「右」は正の X 方向です。
|
| 8 = 可変 |
文字列全体で、文字から文字までのメトリックが一定ではなく (たとえば、文字の配置がばらばらである)、ピッチは固定でもプロポーショナルでもないことを表します。OCRMax 関数でピッチのタイプを特定することは推奨しません。
注 : [変数] ピッチは [自動] とは異なります。[自動] は、ピッチは固定またはプロポーショナルのどちらかではあるが、不明であることを前提にしています。
|
|
|
| 分類の詳細設定 |
分類プロセスを調整するパラメータを指定します。登録文字と取り込んだ画像内の文字の相違に基づいて文字を分類する方法を指定します。
| 分類テンプレートサイズ幅 |
登録文字矩形と実行時文字矩形間の許容可能な X スケール係数を指定します (5 ~ 50、デフォルト = 10)。有効な場合は、スケール制約を満たすインスタンスのみが計算されます。 |
| 分類テンプレートサイズの高さ |
登録文字矩形と実行時文字矩形間の許容可能な Y スケール係数を指定します (5 ~ 50、デフォルト = 18)。有効な場合は、スケール制約を満たすインスタンスのみが計算されます。 |
| 文字のアスペクト比を保持 |
実行時に展開された画像を再サンプリングする際にアスペクト比を維持するかどうかを指定します。
| 0 = OFF (デフォルト) |
実行時に展開された画像を再サンプリングする際にアスペクト比を維持しません。 |
| 1 = ON |
実行時に展開された画像を再サンプリングする際にアスペクト比を維持します。 |
|
| 追加の文字検証をスキップ |
分類時に追加の文字検証を実行するかどうかを指定します。
| 0 = OFF |
分類時に追加の文字検証を実行します。これは、誤読 (文字を誤って許容するなど) の可能性を低減します。 |
| 1 = ON (デフォルト) |
分類時に追加の文字検証を実行しません。ただし、このオプションでは誤読が発生することがあります。 |
|
| 画像前処理 |
分類前に実行する画像処理関数を指定します。
| 0 = なし |
分類前に画像処理を実行しません。 |
| 1 = 正規化ヒストグラム (デフォルト) |
ヒストグラムに基づいて画像を正規化します。 |
| 2 = 中央値を減算 |
ローカルの近傍の中央値に基づいて減算します。 |
| 3 = 正規化ヒストグラム & 中央値を減算 |
分類時に正規化ヒストグラムと中央値の減算の両方の画像処理を実行します。
注 : このオプションが選択されると、ヒストグラムの正規化が実行されてから中央値が減算されます。
|
|
|
| フィールド化 |
[フィールド化] を使用して、文字列のさまざまな位置にあると予測される文字に関する情報を提供します。
| フィールド化していない文字を無視 |
文字位置ごとに、文字のフィールド形式によって指定された文字のみを含めるように結果を制約するかどうかを指定します。有効な場合は、分類得点に関係なく、フォント内の他のすべての文字が無視されます。
| 0 = OFF (デフォルト) |
文字のフィールド形式に基づいて結果を制約しません。 |
| 1 = ON |
文字のフィールド形式に基づいて結果を制約します。 |
|
| 文字列長 |
フィールド形式を固定長モードまたは可変長モードのどちらで実行するかを指定します。
| 0 = 可変 |
可変長モードで動作します。 |
| 1 = 固定 (デフォルト) |
固定長モードで動作します。 |
|
| 最大文字列長 |
許容可能な最大文字数を指定します (0 ~ 100、デフォルト = 25)。
注 : [文字数] パラメータが [固定] に設定されている場合、このパラメータは使用できません。
|
| 最小文字列長 |
許容可能な最小文字数を指定します (0 ~ 100、デフォルト = 1)。
注 : [文字数] パラメータが [固定] に設定されている場合、このパラメータは使用できません。
|
| 最初にフィールド化した最大インデックス値 |
考慮対象となる、フィールド化の部分列を指定します。部分列はこのインデックス値を超えない位置で開始する必要があります (0 ~ 100、デフォルト = 100)。
注 : [文字数] パラメータが [固定] に設定されている場合、このパラメータは使用できません。
|
| 最後にフィールド化した最小インデックス値 |
考慮対象となる、フィールド化の部分列を指定します。部分列はこのインデックス値を超えない位置で終了する必要があります (0 ~ 100、デフォルト = 0)
注 : [文字数] パラメータが [固定] に設定されている場合、このパラメータは使用できません。
|
|
OCRMaxSettingsの出力
| 戻り値 |
読み取られた文字列を含んでいる設定データ構造体。入力パラメータが無効であれば #ERR を返します。 |