OCRMax
ユーザ定義の文字フォントが登録された後に、対象領域 (ROI) 内のテキスト文字列の読み取りおよび照合を行うか、またはそのどちらかを実行します。
概要
OCRMax 関数は、セグメンテーションと分類のプロセスを通じて光学式文字認識 (OCR) を実行します。セグメンテーションは、最初に実行され、しきい値技術を使用してテキスト行を含むとみなされる画像内の領域を特定します。テキストを文字にセグメンテーションした後、文字を登録し、フォントデータベースとして格納します。分類は、実行時に行われ、関数がセグメンテーションを実行した後に、検出されたテキストの「読み取り」を担います。そして、セグメンテーションされた文字の画像と登録された文字のフォントを比較することで識別されます。
セグメンテーションプロセスでは、OCRMax 関数が ROI 内のテキスト行の位置を判別し、テキストの角度、傾き、および極性を計算します。その後、領域を正規化し、不要なノイズを除去してから、前景ピクセルと背景ピクセルに 2 値化します。2 値化画像内でブロブ解析を実行し、文字フラグメントを生成します。各文字フラグメントが単一のブロブを表します。文字フラグメントをグループ化して文字を形成し、その文字に文字領域を割り当てます。文字領域は、ROI 内の前景 (インクなど) ピクセルすべてを無駄なく囲んだ編集不可のバウンディングボックスです。

ROI 内のテキスト行は、個々の文字の画像に分割され、各文字は編集不可の文字矩形で囲まれます。ROI は、テキスト行のおよその位置、角度、傾きを定義します。必要に応じて、[セグメント] タブの [角度範囲] および [スキュー範囲] パラメータを使用して、偏差を補正できます。
OCRMaxの入力パラメータ
オートチューン: [オートチューン] ダイアログを起動して、自動的に最適な [セグメント] パラメータを計算し、フォントデータベースを登録します。[オートチューン] ダイアログの実行中に 1 つまたは複数の画像をロードすると、各画像が検査され、文字が正しくセグメント化および分類されていることが確認されます。文字が正しくセグメント化されていない場合、OCRMax 関数のオートチューンアルゴリズムは、現在の画像および以前に登録した画像をセグメント化する最適な [セグメント] パラメータを計算します。画像の登録数が増えるほど、OCRMax 関数のオートチューンアルゴリズムの信頼性と正確性が向上します。満足な結果が得られたら、[オートチューン] ダイアログを閉じ、新しい [セグメンテーション] パラメータを適用します。フォントデータベースは新たに登録された文字で更新されます。
[オートチューン] ダイアログには、[セグメンテーション] パラメータを手動でチューニングする場合に比べて、主に 2 つの利点があります。
- 画像に必要なサイクルは、2 回 (1 回目に [セグメンテーション] をチューニングし、2 回目に登録する) ではなく、1 回だけです。
- 読み取り精度は、チューニングプロセス中に取得される [セグメンテーション] パラメータによって文字が自動的に登録されることによって向上します。
[全般] タブ
Syntax:OCRMax(画像,フィクスチャ.行,フィクスチャ.列,フィクスチャ.角度,領域.X,領域.Y,領域.高さ,領域.幅,領域.角度,領域.カーブ,フォント,外部設定,登録モード,フォントの登録,フォントをクリア,検査モード,マッチ文字列,フィールド文字列,フィールド定義,スペース.スペースの検出,スペース.スペース得点モード,スペース.スペース最小幅,スペース.スペース最大幅,アクセプトしきい値,コンフュージョンしきい値,サブサンプリングの使用,タイムアウト,出力画像グラフィックス,文字ラベル位置,診断の表示,カーブ領域位置,リセット,表示)
|
画像データ構造体を含んだスプレッドシートセルを参照するように指定します。デフォルトでは、このパラメータは、AcquireImage 画像データ構造体を含むセル A0 を参照しています。また、このパラメータは、ビジョンツールのグラフィックス関数や、座標補正関数により返された、そのほかの画像データ構造体も参照できます。 |
|||||||||||||||||||
|
フィクスチャ入力、またはビジョンツール関数の画像座標系の出力に関連する対象領域 (ROI) を定義します。フィクスチャに関連する ROI を設定すると、フィクスチャが回転または移動した場合に、フィクスチャに対応して ROI を確実に回転または移動できます。 デフォルト設定は画像の左上隅で、(0, 0, 0) になります。
|
|||||||||||||||||||
|
これは対象領域 (ROI) とも呼ばれ、解析の対象となる画像の領域を表します。変換および回転可能な矩形の画像領域を作成します。このパラメータを選択して、プロパティシートのツールバーにある [領域の最大化] ボタンを押すと、画像全体が対象になるように領域が自動的に拡張されます。 ROI の X 軸はテキストのベースラインと平行となり、Y 軸は文字の垂直ストロークと平行になります。傾きがない場合は、Y 軸は X 軸に垂直になります。X 軸の正の方向が読み取り方向に対応します。 注 :
経験則として、可能な場合、ROI はすべての側でテキスト行より文字幅の半分以上大きくします (ROI に他の特徴が含まれてしまう大きさにならない限り)。
|
|||||||||||||||||||
|
必要に応じて、別の OCRMax 関数によって出力され、登録フォントを含むデータ構造体へのセル参照を指定します。 注 : 参照が設定されており、登録フォントを参照する関数内で登録文字を編集する場合、登録文字への変更は、[取り消し] ボタンを押しても取り消されません。
|
|||||||||||||||||||
|
必要に応じて、OCRMaxSettings または GetInternalSettings 関数によって出力されたデータ構造体へのセル参照を指定します。[セルにエクスポート] オプションを使用している場合、このパラメータは新しく作成した OCRMaxSettings 関数の設定データ構造体への絶対セル参照として自動的に設定されます。 注 :
|
|||||||||||||||||||
|
フォントの登録方法を指定します。
|
|||||||||||||||||||
|
登録するテキスト文字列を指定します。 注 : OCRMax 関数は ASCII 文字の登録のみをサポートしています。
|
|||||||||||||||||||
|
[登録モード] パラメータの設定に基づいて、文字を登録するためのイベントを指定します。 |
|||||||||||||||||||
|
フォント内のすべての文字を削除するためのイベントを指定します。 注 : [フォントの登録] および [フォントをクリア] パラメータは、フォント内のすべての文字の削除を開始するイベントと同じイベントを参照し、ROI 内の現在の文字に基づいて再登録することができます。
|
|||||||||||||||||||
|
実行時の関数の検査モードを指定します。
|
|||||||||||||||||||
|
認識と照合検査モード時に、正確に一致する必要のあるテキスト文字列を指定します。 |
|||||||||||||||||||
|
文字列に含まれる文字数を指定します。[フィールド化] を使用して、文字列のさまざまな位置にあると予測される文字に関する情報を提供します。[フィールド化] タブのコントロールを使用して、フィールド文字列とフィールド定義を作成します (必要な場合)。 注 : このパラメータは、[検査モード] パラメータが [読み取り] に設定されている場合のみ使用可能です。
|
|||||||||||||||||||
|
必要に応じ、フィールド定義設定を使用してフィールド文字列のユーザ定義エントリを作成できます。このエントリがフィールド文字列に含まれると、このエントリの挿入位置で有効となる文字のリストが限定されます。[フィールド化] タブのコントロールを使用して、フィールド文字列とフィールド定義を作成します (必要な場合)。 注 : このパラメータは、[検査モード] パラメータが [読み取り] に設定されている場合のみ使用可能です。
|
|||||||||||||||||||
|
必要な場合に、関数が文字間のスペースを考慮する方法を指定します。OCRMax 関数は、文字間のギャップをスペース文字として分類することで処理します。これらはユーザによって定義されます。
|
|||||||||||||||||||
|
各文字の許容できる最低一致得点(0~100、デフォルト = 80)を指定します。[アクセプトしきい値] を下回る一致得点の文字は拒否されます。 |
|||||||||||||||||||
|
最高得点の文字と 2 番目である得点の文字の一致得点の間に必要な最小差を指定します (0 ~ 40、デフォルト = 0)。 |
|||||||||||||||||||
|
画像のサブサンプリングを有効にするかどうかを指定します。有効にすると、文字解像度が低下し関数の読み取り速度が向上します。
|
|||||||||||||||||||
|
この関数による文字のサーチ時間をミリ秒単位で指定します (0 ~ 30000、デフォルト = 5000)。指定された時間が経過すると、実行は停止し、#ERR が返されます。値を 0 に設定すると設定値が無効になり、タイムアウトは適用されません。 |
|||||||||||||||||||
|
表示する出力画像の種類を指定します。
|
|||||||||||||||||||
|
文字領域に対する各文字のラベルを表示する相対位置を指定します。
|
|||||||||||||||||||
|
画像に表示するグラフィックス診断データのタイプを指定します。
|
|||||||||||||||||||
|
カーブ領域を使用する場合、歪みのない領域の画像上の位置を X 座標と Y 座標で指定します。 注 : このパラメータは [領域] パラメータのカーブ値が 0 より大きい場合のみ有効です。
|
|||||||||||||||||||
|
[セグメント] タブのパラメータがデフォルト設定にリセットされ、フォント情報がクリアされ、この関数に関連するオートチューンレコード (.rec) ファイルが削除されるように指定します。 |
|||||||||||||||||||
|
画像上の OCRMax グラフィックスオーバレイの表示モードを指定します。
|



[セグメント] タブ
[セグメント] タブを使用して、ROI 内の文字をセグメンテーションする設定を調整および変更できます。通常は、デフォルト値とデフォルト設定で大半の文字は読み取れます。ただし、比較的困難な場合には、一部のパラメータ値を調整する必要が生じることがあります。このような場合は、最小文字幅、最大幅や最小ピッチ (文字間の距離。例えば、1 つの文字の左端からその次の文字の左端まで) を指定すると、通常は問題が解決します。
- このタブのパラメータは、外部セルから参照することはできません。セル参照が必要な場合は、[外部設定] パラメータが OCRMaxSettings 関数を参照するように設定します。
- [外部設定] パラメータが OCRMaxSettings 関数を参照するように設定されている場合、[セグメント] タブ内のコントロールは無効になります。
- [セグメント] タブ内では、ROI を調整でき ([グラフィックスの編集] ボタンが有効)、ROI が変更されるとセグメンテーショングラフィックス (文字矩形) が更新されます。
- ROI と文字領域を表示した場合に、文字領域の線がスプレッドシートオーバレイによって部分的に非表示になることがあります。[セグメント] パラメータの調整時に、半透明のスプレッドシートオーバレイを非表示にすると、文字領域の部分的な遮蔽を防ぐことができます。
セグメンテーションのガイドライン
- 背景に強度なテクスチャまたは大量のノイズ、あるいはその両方が含まれ、その背景に文字が混在している画像は、セグメンテーションが困難です。
- ROI には、読み取る文字のみを含め、他の文字やラベルエッジなどの無関係な強い特徴は含めないようにします。
- 2 つの文字が接触している場合は、通常、パラメータを調整する必要があります。固定幅の接触文字は文字幅を指定することで補正できますが、接触文字のプロポーショナルフォントが問題となり、関数が正しく処理できる場合とできない場合があります。
- 短いテキスト行 (例えば、3 文字以下) または線ジッタの多い比較的短い行の場合、予測される [角度範囲] を指定すると、関数が固有の不確定度を適切に補正し、短いテキスト行の向きを決定できます。
- 1 行の中のすべての文字が同一の向きと傾きを持っている必要があります。
- 十分に分離されたドットマトリックスプリント (ドットが接触していない) の場合、文字を適切にセグメンテーションするには、[最小文字フラグメントサイズ] などのパラメータを調整する必要が生じることがあります。
- 文字ストローク幅は 2 ピクセル以上にする必要があります。
- 大きな文字 (通常、英数字) の最小文字サイズは 8 × 8 ピクセルです。小さい文字 (ピリオドなど) の最小文字サイズは 2 × 2 ピクセルです。
| セルにエクスポート | 現在の [セグメント] タブのパラメータがスプレッドシート内のセルに OCRMaxSettings 関数としてエクスポートされるように指定します。使用する場合、[セグメント] パラメータは読み取り専用となり、[外部設定] パラメータは新しく作成した OCRMaxSettings 関数への参照として設定されます。[セグメント] パラメータを再び有効にするには、[外部設定] パラメータを 0 に設定して OCRMaxSettings 関数への参照を取り消します。 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| リセット |
[セグメント] タブのパラメータがデフォルト設定にリセットされ、フォント情報がクリアされ、この関数に関連するオートチューンレコード (.rec) ファイルが削除されるように指定します。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| セグメントパラメータ |
セグメント分割の実行に使用されるパラメータ設定を指定します。
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 高度なセグメンテーションパラメータ |
セグメントプロセスに適用される追加パラメータを指定します。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 出力画像グラフィックス |
表示する出力画像の種類を指定します。 注 : このパラメータは、[全般] タブの [出力画像グラフィックス] パラメータを一時的に上書きします。[セグメント] タブを終了すると、[全般] タブの [出力画像グラフィックス] パラメータの設定が復元されます。
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 診断の表示 |
画像に表示するグラフィックス診断データのタイプを指定します。
|


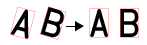
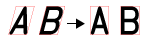


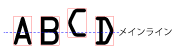

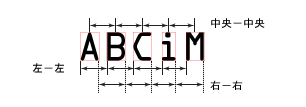
[フォントの登録] タブ
[フォントの登録] タブを使用して、文字の登録、表示、名前の変更、および削除を実行できます。タブは、登録フォントを管理する [文字] と、文字登録パラメータを定義する [登録] の 2 つのグループに分かれています。
[文字] グループボックスコントロール
登録後、各登録文字はツリーで表示できます。ツリーでは、文字はフォルダとラベルが割り当てられ、それに応じてグループ化されます (文字が一致するラベルを持つ場合)。
- ルートのフォントフォルダを選択すると、右側のパネルにフォント内のすべての文字が表示されます。文字は、下にラベルの付いたアイコンとして表示されます。
- 文字フォルダを選択すると、右側のパネルにその文字の登録インスタンスがすべて表示されます。文字は、下にラベルの付いたアイコンとして表示されます。
- 文字の登録インスタンスを選択すると、右側のパネルに合わせてズームされた文字が表示されます。
- インポート: [開く] ダイアログを起動します。このダイアログでは、OCRMax データファイル (*.ocm) として保存されたフォントをインポートできます。
- エクスポート: [名前を付けて保存] ダイアログを起動します。このダイアログでは、フォントを OCRMax データファイル (*.ocm) として保存できます。
-
名前変更: 項目を選択した後にクリックして、名前を変更します。ツリーまたは右側のリストパネル内の要素の名前を変更できます。
注 : 文字グループの名前を変更すると、グループ内のすべての文字に新しいラベルが割り当てられます。単一文字の名前を変更すると、新しいラベルがその単一の選択された文字に割り当てられます。文字はツリー内の新しいグループまたは異なるグループに移動されます。 -
削除: 項目を選択した後にクリックして、フォントから削除します。ツリーまたは右側のリストパネル内の要素の名前を変更できます。
注 : フォントフォルダを削除すると、フォントがクリアされ、すべての文字が削除されます。文字グループを削除すると、削除したグループのラベルと一致するラベルを持つ文字はすべて削除されます。
[登録] グループボックス
文字を登録するには、事前に文字が正しくセグメンテーションされている必要があります。
- すべての文字をフォントに追加: ROI 内のすべての文字を登録するように指定します。登録対象の文字を [文字列の登録] テキスト入力ボックスに入力してから、[登録] ボタンをクリックします。[文字列の登録] テキスト入力ボックスの文字数は、セグメンテーションされた文字の数に一致している必要があります。
- 新規文字をフォントに追加: ROI 内の新しい文字のみを登録するように指定します。登録対象の文字を [文字列の登録] テキスト入力ボックスに入力してから、[登録] ボタンをクリックします。[文字列の登録] テキスト入力ボックスの文字数は、セグメンテーションされた文字の数に一致している必要があります。
- 個々の文字をフォントに追加: ROI 内の特定の文字を登録するように指定します。このオプションを選択すると、[文字列の登録] テキスト入力ボックスは無効になり、[登録] ボタンをクリックすると [個々の文字をフォントに追加] ダイアログが起動します。このダイアログでは、ROI の展開された画像と、セグメンテーションされた各文字の下にラベルとテキスト入力ボックスが示されます。ラベルは、その文字に現在関連付けられているシンボルです (「?」は、不明または未登録の文字を示します)。ラベルの下にテキスト入力ボックスがあります。セグメンテーションされた各文字のラベルをテキスト入力ボックスに入力します。テキスト入力ボックスを空のままにすると、文字は再登録されません。[登録] ボタンをクリックしてダイアログを閉じます。
- 文字列の登録: 登録するテキスト文字列を指定します。[文字列の登録] テキスト入力ボックスの文字数は、セグメンテーションされた文字の数に一致している必要があります。
- [登録] ボタン: 登録をアクティブ化します。
[フィールド化] タブ
[フィールド化] タブでは、OCRMax 関数の [フィールド文字列] 引数と [フィールド定義] 引数をグラフィカルに作成および編集することができます。結果の値は、リテラル文字列として関数に挿入されます。
[フィールド化] は、文字列を確認し修正する機能を提供し、一連の最適一致した有効な文字列を返します。[フィールド化] には 2 通りの基本的な用途があります。
- OCR の結果の検証。[フィールド文字列] および [フィールド定義] パラメータに基づいて、返された文字列が正しいかどうかを判断します。
- OCR の結果の修正。返された文字列が許容可能な結果リストにない場合は、返された文字列に最も近い、そのフィールドで許可されている許容文字列の検索を試みます。
フィールド化の標準的な使用例では、文字列にプレフィックス文字またはサフィックス文字、あるいはその両方が含まれている場合に、フィールド形式を使用してプレフィックス/サフィックス文字を無視します。この場合、[フィールド文字列] と [フィールド定義] によって ROI 内の文字列位置のオフセットが決まります。
フィールド文字列
文字列に含まれる文字数を指定します。フィールド文字列エントリには、(A~Z)、(a~z)、(0~9)、ハイフン(-)、ドット(.)、スペース( )など、[テキスト入力] ダイアログのすべての文字を使用できます。
フィールド文字列の各文字は、0 ~ 31 のインデックス付きフィールド位置に対応します。フィールド文字列には、読み取りを成功させたい文字列の文字と少なくとも同じ数の位置が含まれている必要があります (つまり、10 文字存在し、フィールド文字列で 9 文字のみ指定した場合は、最適一致が 9 つ返されます。しかし、8 文字存在し、フィールド文字列で 9 文字指定した場合、関数は #ERR を返します)。デフォルトでは、フィールド文字列の各位置は、アスタリスク(*)か英数字の「ワイルドカード」で示されます。これは、文字列のどの位置でもすべての文字が有効であることを意味します。
ただし、フィールド文字列の個別の位置は、その位置に一部の文字しか想定されないように制限することができます。すると、対象外の文字は読み取り時に考慮されないため、全体的な性能と信頼性が向上します。
定義済みのフィールド文字列エントリは、次のとおりです。
|
フィールド文字列 エントリ |
説明 | 有効な文字 |
| * | ワイルドカード | フォントに含まれる任意の登録文字です。 |
| N | 数字 | 0123456789 |
| A | 大文字の英字 | ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| a | 小文字の英字 | abcdefghijklmnopqrstuvwxyz |
| H | 16 進値(大文字の英字と数字) | 0123456789ABCDEF |
| h | 16 進値(小文字の英字と数字) | 0123456789abcdef |
| O | 8 進値 | 01234567 |
- フィールド文字列のある位置を特定の文字に制限する場合は、その文字を入力してください。文字はフォントに登録されている必要があります。また、[フィールド定義] パラメータを使用して再マップしない限り、上記の定義済みフィールド文字列エントリの文字を使用することはできません。
- スペースを含む文字列を読み取るには、フィールド文字列にスペースを含めます。その位置の対応するフィールド文字列エントリがアスタリスク(*)の場合、ReadText 関数はスペースを読み取りません。
- [全般] タブの [フィールド文字列] パラメータがセル参照として定義されている場合、[フィールド化] タブの [フィールド文字列] オプションは無効になり、セル参照の現在の値が表示されます。
フィールド文字列が「**********AN」の場合、1~10 番目のフィールド文字列位置ではフォントに含まれるすべての文字が有効です。ただし、11 番目の位置は、読み取り時に大文字の英字だけが想定されます。また、12 番目の位置は、数字だけが想定されます。
フォントには、0~9 の数字と / だけが含まれます。フィールド文字列が「NN/NN/NN」の場合、1、2、4、5、7、および 8 番目の位置では数字だけが想定されています。また、3 および 6 番目の位置ではスラッシュ(/)だけが想定されています。
ただし、フィールド文字列が「NN/NN/AA」の場合は、フォントに英字が含まれていないため、#ERR が返されます。
フィールド定義
必要に応じ、フィールド定義設定を使用してフィールド文字列のユーザ定義エントリを作成できます。このエントリがフィールド文字列に含まれると、このエントリの挿入位置で有効となる文字のリストが限定されます。いくつかの定義済みフィールド定義があり、ユーザ定義のフィールド定義を追加できます。定義済み定義はグレーのテキストで表示され、削除も編集もできず、有効または無効の切り替えのみ可能です。ユーザ定義の定義は黒色のテキストで表示され、追加、削除、または編集できます。フィールド定義を追加するには、[新規追加] ボタンをクリックし、文字のアイコンを割り当ててから、定義を文字に割り当てます。
フィールド定義エントリのために示す文字は、フォントに含まれている必要があります。次に例を示します。#=123 は、ユーザ登録フォントに 1、2、3 が含まれる場合に有効です。ただし、#=123 は、フォントに 1、2、3 が含まれない場合は無効です。
フィールド定義の値が「#=123;$=3456;%=789」で、フィールド文字列が「#$%*******」の場合、1 番目の位置で有効な文字は、1、2、または 3 だけです。2 番目の位置で有効な文字は、3、4、5、または 6 だけです。また、3 番目の位置では、7、8、または 9 だけが有効です。また、4~10 番目の位置ではフォントに含まれるすべての文字が有効です。
フィールド定義の値が「#=123;$=3456;%=789, A=A」で、フィールド文字列が「#$%******A,」の場合、1 番目の位置で有効な文字は、1、2、または 3 だけです。2 番目の位置で有効な文字は、3、4、5、または 6 だけです。また、3 番目の位置では、7、8、または 9 だけが有効です。また、4~9 番目の位置ではフォントに含まれるすべての文字が有効です。フィールド定義「A=A」は定義済みのフィールド文字列エントリを再割り当てするため、10 番目の位置では A だけが想定されています。
フィールド定義のコントロール
-
フィールド文字列内の文字のみにマッチを行う: 関数が、フィールド文字列によって示されている文字に対してのみ文字の比較を試みるかどうかを指定します。
-
可変長文字列: 定義されたフィールド文字列が読み取りテキスト文字列全体の中の部分文字列であるかどうかを指定します。部分文字列が検出された場合は、最適一致の部分文字列が返されます。
注 : [外部設定] パラメータが OCRMaxSettings 関数への参照として設定されている場合、[フィールド文字列内の文字のみにマッチを行う] および [可変長文字列] パラメータは無効になります。 - 最小長: [可変長文字列] パラメータが有効な場合、このパラメータは許容可能な文字列長の最小値を指定します (0 ~ 100、デフォルト = 1)。
- 最大長: [可変長文字列] パラメータが有効な場合、このパラメータは許容可能な文字列長の最大値を指定します (0 ~ 100、デフォルト = 25)。
- 最大開始インデックス値: [可変長文字列] パラメータが有効な場合、このパラメータは考慮対象となる、フィールド形式の部分列を指定します。部分列はこのインデックス値を超えない位置で開始する必要があります (0 ~ 100、デフォルト = 100)。
- 最小終了インデックス値: [可変長文字列] パラメータが有効な場合、このパラメータは考慮対象となる、フィールド化の部分列を指定します。部分列はこのインデックス値以上の位置で終了する必要があります (0 ~ 100、デフォルト = 0)。
[結果] タブ
[結果] タブは、総合結果と各文字の得点を表示します。[全体結果] と [文字結果] の 2 つのセクションに分かれています。
全体結果
- ステータス: 関数の総合結果が合格か不合格かを表示します。
文字結果
- 文字: その位置で読み取った文字を表示します。
- ステータス: 読み取り文字のステータス ([読み取り (Bad)]、[読み取り (Good)]、[無視]、[コンフュージョン]、[ミスマッチ]、[コンフュージョンミスマッチ]、または [検証失敗]) を表示します。
- [読み取り (Bad)]:良好な読み取りとみなされる [アクセプトしきい値] を上回る十分に高い得点の文字ではありません。
- [読み取り (Good)]:関数はこの位置の文字を正常に読み取りました。
- [無視]:フィールド形式が有効な場合、フィールド形式文字列が指定され、それが関数によって読み取られた文字列より短いと、文字列の先頭または末尾の文字がセグメンテーションされますが (黄色)、総合結果には含まれません。例えば、フィールド形式定義が ABC の場合、関数によって読み取られた文字列が「12ABC34」であると、「1234」は無視されます。
- [コンフュージョン]:関数は、良好な読み取りとして十分に得点の高い文字を識別しました ([アクセプトしきい値] パラメータ値を上回る)。ただし、得点が非常に近い別の文字があり ([コンフュージョンしきい値] パラメータ値以内)、関数が正しい文字を選択したかどうかは確実ではありません (コンフュージョン = (1 番目の得点 - 2 番目の得点)/信頼性しきい値)。
-
[ミスマッチ]:関数は、フィールド化に一致しないどの文字よりも非常に得点の高い、フィールド形式に一致しない文字を検出しました。フィールド形式に一致しない文字は、この位置に印刷されることが多くあります。このステータスを返すには、フィールド形式が有効になっている必要があります。
- コンフュージョンミスマッチ:コンフュージョンとミスマッチの両方の条件を満たす文字を検出しました。
- [検証失敗]:OCRMaxSettings 関数が使用されており、その関数の [追加の文字検証をスキップ] パラメータが無効の場合、関数は追加の検証手順を通じて文字を解析し、関数が誤った読み込みを生成しないように保証します。
- 得点: 読み取った文字がフォントデータベース内の登録文字にどのぐらい近いかを測定した得点を表示します。
- コンフュージョン:次の最適一致の文字を表示します。
- コンフュージョン得点:次の最適一致と比較した場合に、選択した一致がどのぐらい確実かを示す測定値を表示します。
[診断] タブ
[診断] タブには、OCRMax 関数による ROI 内の文字のセグメンテーション方法に関する情報が表示されます。このデータは、調整するパラメータ、調整する量、文字や文字フラグメントが正しくセグメント化されていないかどうかを判断する際に有用です。このタブは、診断データのグラフィックス表示を指定する [診断の表示] パラメータとともに使用します。
メインラインのデータ
- [メインライン角度]:ROI に対する文字領域の、角度方向の計測値を角度で表示します。
- [文字スキュー]:ROI に対する文字領域の、角度スキューの計測値を角度で表示します。
- [文字ピッチ]:文字の最小および最大ピッチ測定値をピクセル単位で表示します。
- [文字間ギャップ]:文字間ギャップの最小および最大測定値をピクセル単位で表示します。
- [文字内ギャップ]:文字内ギャップの最小および最大測定値をピクセル単位で表示します。
合格した文字
- [幅]:合格した文字の幅の最小および最大測定値をピクセル単位で表示します。
- [高さ]:合格した文字の高さの最小および最大測定値をピクセル単位で表示します。
- [サイズ]:合格した文字サイズの最小および最大測定値をピクセル単位で表示します。
除外した文字
- [幅]:除外された文字の最小および最大測定幅をピクセル単位で表示します。
- [高さ]:除外された文字の高さの最小および最大測定値をピクセル単位で表示します。
- [サイズ]:除外された文字サイズの最小および最大測定値をピクセル単位で表示します。
合格したフラグメント
- [サイズ]:合格したフラグメントのサイズの最小および最大測定値をピクセル単位で表示します。
- [コントラスト]:合格したフラグメントのコントラストの最小および最大測定値を割合 (%) で表示します。
- [メインラインまでの距離 (%)]:合格したすべてのフラグメントの最大 Y 距離を、メインラインの高さの割合 (%) で表示します。
除外したフラグメント
- [サイズ]:除外されたフラグメントのサイズの最小および最大測定値をピクセル単位で表示します。
- [コントラスト]:除外されたフラグメントのコントラストの最小および最大測定値を割合 (%) で表示します。
- [メインラインまでの距離 (%)]:除外されたすべてのフラグメントの最大 Y 距離を、メインラインの高さの割合 (%) で表示します。
OCRMaxの出力
| 戻り値 | 読み取られた文字列を含んでいるデータ構造体。入力パラメータが無効であれば #ERR を返します。 |
| 結果 | OCRMax 関数が初めてセルに挿入されると、スプレッドシート内に結果テーブルが自動的に作成されます。 |
OCRMaxデータアクセス関数
次のデータアクセス関数がスプレッドシートに自動挿入され、結果テーブルが作成されます。
| 文字列 | GetString(OCR 最大) | 参照されているデータ構造体のテキスト文字列を返します。 |
| 文字列合格 | GetPassed(OCRMax) | 参照されているデータ構造体の文字列全体の合格/不合格ステータスを返します。 |
| インデックス | ||
| 文字 | GetChar(OCRMax, インデックス) | 参照されているデータ構造体のインデックス付き文字を返します。 |
| 得点 | GetScore(OCRMax, インデックス) | 参照されているデータ構造体のインデックス付き文字の一致得点 (0 ~ 100) を返します。 |
| 合格 | GetPassed(OCRMax, インデックス) | 参照されているデータ構造体のインデックス付き文字の合格/不合格ステータスを返します。 |
| 2 番目文字 | GetChar(OCRMax, インデックス 0, [インデックス 1]) | 2 番目に高い得点の文字を返します。 |
| 2 番目得点 | GetScore(OCRMax, インデックス 0, [インデックス 1]) | 2 番目に高い得点の文字の得点を返します。 |
| 文字差 | インデックス付き文字の得点と 2 番目の得点値の差を返します。 |