OCRMax
Reads and/or verifies a text string within a Region of Interest (ROI), after being trained with user-defined character fonts.
The OCRMax function performs Optical Character Recognition through a process of segmentation and classification. Segmentation occurs first and uses threshold techniques to identify the areas of the image that appear to contain lines of text. After the text has been segmented into characters, the characters are trained and stored as a font database. Classification occurs during run-time, and is responsible for “reading” any text found after the function performs segmentation. This is done by comparing the images of the segmented characters to the trained characters in the font.
During the segmentation process, the OCRMax function determines the location of the line of text within the ROI, and calculates the text's angle, skew and polarity. The region is then normalized to remove unwanted noise before being binarized into foreground and background pixels. Within the binarized image, blob analysis is performed to produce character fragments, with each character fragment representing a single blob. The character fragments are then grouped together to form characters, and the characters are assigned a character region. The character region is a tight, non-editable bounding box enclosing all of the foreground (i.e. ink) pixels in the ROI.
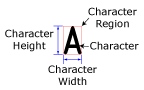
The line of text within the ROI is split into images of the individual characters, and each character is enclosed within a non-editable character rectangle. The ROI defines the approximate location, angle and skew of the line of text. The Angle Range and Skew Range parameters on the Segmentation tab can be used to compensate for variations, if necessary.
OCRMaxInputs
Auto-Tune: Launches the Auto-Tune dialog, which is used to automatically calculate the optimal Segmentation parameters, and train a font database. With one or more images loaded, and with the Auto-Tune dialog running, each image is examined to verify that the characters are being correctly segmented and classified. If the characters are not being correctly segmented, the OCRMax function's Auto-Tune algorithm will calculate the optimal Segmentation parameters that segment the current image, as well as the previously trained images. As more images are trained, the OCRMax function's Auto-Tune algorithm will become more reliable and accurate. Once satisfactory results are achieved, the Auto-Tune dialog is closed, the new Segmentation parameters are applied and the font database is updated with the newly trained characters.
The Auto-Tune dialog provides two primary advantages over manually tuning the Segmentation parameters:
- Images only need to be cycled through once, instead of twice (once to tune the Segmentation parameters, and the second to train).
- Read accuracy should improve because the characters are trained automatically with the Segmentation parameters obtained during the tuning process.
General Tab
Syntax: OCRMax(Image,Fixture.Row,Fixture.Column,Fixture.Theta,Region.X,Region.Y,Region.High,Region.Wide,Region.Angle,Region.Curve,Font,External Settings,Train Mode,Train String,Train Font,Clear Font,Inspection Mode,Match String,Field String,Field Definitions,Spaces. Find Spaces,Spaces. Space Score Mode,Spaces. Space Minimum Width,Spaces. Space Maximum Width,Accept Threshold,Confusion Threshold,Use Subsampling,Timeout,Output Image Graphic,Character Label Position,Show Diagnostics,Curved Region Position,Reset,Show)
| Parameter | Description | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Specifies a reference to a spreadsheet cell that contains an Image data structure; by default, this parameter references A0, the cell containing the AcquireImage Image data structure. This parameter can also reference other Image data structures, such as those returned by the Vision Tool Image functions or Coordinate Transforms Functions. |
|||||||||||||||||||
|
Defines the Region of Interest (ROI) relative to a Fixture input or the output of a Vision Tool function's image coordinate system. Setting the ROI relative to a Fixture ensures that if the Fixture is rotated or translated, the ROI will be rotated or translated in relation to the Fixture. For more information, see Fixture and Vision Tools Functions. The default setting is (0,0,0), the top leftmost corner of the image.
|
|||||||||||||||||||
|
The Region of Interest (ROI) specifies the region of the image that undergoes analysis and creates a rectangular image region that can be transformed and rotated. For more information, see Interactive Graphics Mode. Tip: With this parameter
selected, you can press the Maximize
Region button on the property sheet's toolbar to maximize the region and cover the entire image.
The X-axis of the ROI should be parallel to the baseline of the text, and the Y-axis should be parallel to the vertical strokes of the characters; if there is no skew, the Y-axis is perpendicular to the X-axis. The positive direction of the X-axis corresponds to the reading direction. Note: The baseline of the text may have any angle (0-360) in the image, as long as the ROI is oriented at approximately the same angle.
The ROI should only contain one line of text to be read, and some surrounding background. The background can be noisy and have significant background gradients/shading. In images with text that are clearly printed and have little noise, the ROI may be significantly larger than the line of text. For noisy images, the ROI should be relatively tight around the line of text. Note: The ROI shouldn’t contain any other significant features in the image, other than the line of text. For example, the ROI shouldn’t partially enclose a different line of nearby text, or the edge of a label.
As an approximate rule of thumb, the ROI should be larger than the line of text by at least half a character width on all sides, if possible (i.e. unless a border that large would cause other features to be enclosed within the ROI).
|
|||||||||||||||||||
|
Optionally, specifies a cell reference to a data structure output by another OCRMax function, containing a trained font. Note: If a reference is set, and the trained characters are edited in the function referencing the trained font, the changes to the trained characters will not be undone if the Undo button is pressed.
|
|||||||||||||||||||
|
Optionally, specifies a cell reference to a data structure output by an OCRMaxSettings or GetInternalSettings function. If the Export to Cell option has been utilized, this parameter will automatically be set as an absolute cell reference to the newly created OCRMaxSettings function's Settings data structure. For more information, see OCRMaxSettings Note:
|
|||||||||||||||||||
|
Specifies the font training behavior.
|
|||||||||||||||||||
|
Specifies the text string to be trained. Note: The OCRMax function only supports training ASCII characters.
|
|||||||||||||||||||
|
Specifies the event on which to train the characters, based on the Train Mode parameter setting. |
|||||||||||||||||||
|
Specifies an event on which all of the characters in the font will be removed. Note: The Train Font and Clear Font parameters can reference the same event, which will initiate the removal of all the characters in the font, and retraining based on the current characters within the ROI.
|
|||||||||||||||||||
|
Specifies the inspection mode of the function during run-time.
|
|||||||||||||||||||
|
Specifies the text string that must be correctly matched when in Read/Verify Inspection Mode. |
|||||||||||||||||||
|
Specifies the number of characters contained in the character string. Fielding is used to provide information about what characters are expected at different positions in the string. Use the controls in the Fielding tab to construct the Field String and Field Definitions (if necessary). Note: This parameter is only available when the Inspection Mode parameter is set to Read.
|
|||||||||||||||||||
|
Optionally, the Field Definitions setting can be used to create user-defined entries for the FieldString. When included in the FieldString, these entries restrict the list of valid characters at the positions in which they are inserted. Use the controls in the Fielding tab to construct the Field String and Field Definitions (if necessary). Note: This parameter is only available when the Inspection Mode parameter is set to Read.
|
|||||||||||||||||||
|
Specifies how the function will account for spaces between characters, if necessary. The OCRMax function processes inter-character gaps by classifying them as space characters, and these are user-defined.
|
|||||||||||||||||||
|
Specifies the minimum acceptable match score(0 to 100; default = 80) for each character. Any character with a match score below the Accept Thresh will fail. |
|||||||||||||||||||
|
Specifies the minimum difference required between the match scores of the highest scoring character and the second highest scoring character (0 to 40; default = 0). |
|||||||||||||||||||
|
Specifies whether or not to enable image subsampling, which decreases character resolution to increase the reading speed of the function.
|
|||||||||||||||||||
|
Specifies the amount of time, in milliseconds(0 to 30000; default = 5000), that the function will search for characters before execution is halted and an #ERR is returned. Setting the value to 0 disables the setting and a timeout is not applied. |
|||||||||||||||||||
|
Specifies the type of output image that should be displayed.
|
|||||||||||||||||||
|
Specifies where to display each character's label in relation to the character region.
|
|||||||||||||||||||
|
Specifies which type of graphical diagnostic data to display on the image.
|
|||||||||||||||||||
|
Specifies the X and Y coordinates for where the straightened Region will be placed in the image, when a curved Region is used. Note: This parameter is only enabled if the Region parameter Curve value is greater than 0.
|
|||||||||||||||||||
|
Specifies that the Segmentation tab parameters will be reset to their default settings, clear font information and remove any Auto-Tune record (.rec) files associated with the function.OCRMaxSettings Note: This button is disabled if the External Settings parameter is set as a reference to a GetInternalSettings or OCRMaxSettings function. For more information, see GetInternalSettings(OCRMax) or OCRMaxSettings.
|
|||||||||||||||||||
|
Specifies which OCRMax graphics overlay the image.
|



Segmentation Tab
The Segmentation tab is used to adjust and modify the settings that segment characters in the ROI. Typically, the default values and settings will read most text, however, in more challenging cases, some parameter values may need to be adjusted. In these types of cases, specifying a minimum character width, a maximum width and/or a minimum pitch (i.e. the character-to-character distance; for example, from the left edge of one character to the left edge of the one after it) will typically address the issues.
- The parameters on this tab may not be referenced to external cells. If cell references are required, set the External Settings parameter to reference an OCRMaxSettings function.
- If the External Settings parameter is configured to reference an OCRMaxSettings function, the controls in the Segmentation tab will be disabled.
- While in the Segmentation tab, the ROI can be adjusted (the Edit Graphic button is enabled) and the segmentation graphics (character rectangles) will be updated as the ROI is modified.
- When viewing the ROI and character regions, the lines of character regions may be partially hidden by the spreadsheet overlay. When adjusting the Segmentation parameters, hide the semitransparent spreadsheet overlay to prevent the character regions from being partially occluded.
Segmentation Guidelines
- Images that contain backgrounds with strong textures and/or so much noise that the characters blend into the background will be difficult to segment.
- The ROI should only contain the characters to be read, and not any extraneous strong features, such as other characters or label edges.
- In instances where two characters touch, most likely, parameters will need to be adjusted. Fixed-width touching characters can be compensated for by specifying the character width; however, proportional fonts with touching characters are problematic, with the function correctly processing some cases, but not others.
- In cases involving short lines of text (for example, three or fewer characters) or relatively short lines with a lot of line jitter, specifying the expected Angle Range should help the function properly compensate for the inherent uncertainty in determining the orientation of a short line of text.
- All the characters in a line of characters must have the same orientation and skew.
- For well-separated dot-matrix print (e.g. where the dots are not touching), adjusting parameters such as the Minimum Character Fragment Size may be necessary to properly segment the characters.
- Character stroke width must be greater than or equal to two pixels.
- The minimum character size for large characters (typically alphanumeric) is 8 x 8 pixels. The minimum character size for small characters (such as periods) is 2 x 2 pixels.
|
Specifies that the current Segmentation tab parameters will be exported to a cell in the spreadsheet as an OCRMaxSettings function. Once used, the Segmentation parameters will be read-only, and the External Settings parameter will be set as a reference to the newly created OCRMaxSettings function. To re-enable the Segmentation parameters, set the External Settings parameter to zero to clear the reference to the OCRMaxSettings function. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Specifies that the Segmentation tab parameters will be reset to their default settings, clear font information and remove any Auto-Tune record (.rec) files associated with the function. Note: This button is disabled if the External Settings parameter is set as a reference to a GetInternalSettings or OCRMaxSettings function. For more information, see GetInternalSettings(OCRMax) or OCRMaxSettings.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Specifies the parameter settings used to perform segmentation.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Specifies additional parameters to be applied during the segmentation process.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Specifies the type of output image that should be displayed. Note: This parameter temporarily over-rides the Output Image Graphic parameter in the General tab. After exiting the Segmentation tab, the Output Image Graphic parameter setting in the General tab will be restored.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Show Diagnostics |
Specifies which type of graphical diagnostic data to display on the image.
|





Train Font Tab
The Train Font tab is used to train, view, rename and remove characters. The tab is divided into two groups, Characters, where the trained fonts are managed, and Training, where the character training parameters are defined.
- The controls on this tab are not linked to the Train Mode, Train String and Train Font parameters on the General tab.
- While in the Train Font tab, the ROI can be adjusted (the Edit Graphic button is enabled) and the segmentation graphics (character regions) will be updated as the ROI is modified.
- Multiple-byte character names (e.g. Kanji) are not supported. Multiple-byte characters can be trained, but the name given to the character must be a single byte name.
Characters Group Box Controls
After training, each trained character will be visible in the tree, where the character will assigned a folder and label, and grouped together (if the characters have matching labels).
- Select the root Font folder to display all of the characters in the font in the panel on the right-side. The characters will be displayed as icons with a label underneath.
- Select a character folder to display all of the trained instances of that character in the panel on the right-side. The characters will be displayed as icons with a label underneath.
- Select a trained instance of a character to display that character, zoomed to fit the panel on the right-side.
-
Import: Launches the Open dialog, where a font, saved as an OCRMax data file (*.ocm), may be imported.
-
Export: Launches the Save As dialog, where a font can be saved as an OCRMax data file (*.ocm).
-
Rename: Press after selecting an item to rename it. Any element in the tree or in the list panel on the right-side can be renamed.
Note: Renaming a group of characters will assign a new label to all of the characters in the group. Renaming a single character will assign a new label to that single, selected character; the character will be moved to a new or different group in the tree. -
Delete: Press after selecting an item to remove it from the font. Any element in the tree or in the list panel on the right-side can be renamed.
Note: Deleting the Font folder will clear the font; all characters will be deleted. Deleting a group of characters will delete all of the characters whose label matched the deleted group's label.
Training Group Box
Before characters can be trained, they must be correctly segmented.
- Add All Characters to Font: Specifies that all of the characters in the ROI will be trained. The characters expected to be trained are entered into the Train String text entry box, before the Train button is pressed. The number of characters in the Train String text entry box must match the number of segmented characters.
- Add New Characters to Font: Specifies that only new characters in the ROI will be trained. The characters expected to be trained are entered into the Train String text entry box, before the Train button is pressed. The number of characters in the Train String text entry box must match the number of segmented characters.
- Add Individual Characters to Font: Specifies that specific characters in the ROI will be trained. When this option is selected, the Train String text entry box will be disabled, and the Train button will launch the Add Selected Characters to Font dialog. This dialog contains an unwrapped image of the ROI, with a label and text-entry boxes below each of the segmented characters. The label is the currently associated symbol for that character (a "?"denotes an unknown or untrained character). Below the label is a text-entry box. Enter a label for each segmented character in the text-entry box; leave the text-entry box empty to not retrain characters. Press the Train button to close the dialog.
- Train String: Specifies the text string to be trained. The number of characters in the Train String text entry box must match the number of segmented characters.
- Train Button: Activates training.
Fielding Tab
The Fielding tab provides a graphical means of creating and editing the Field String and Field Definitions arguments of the OCRMax function. The resulting values are inserted into the function as literal strings.
Fielding provides the functionality to verify and correct strings, returning the set of best matching valid strings. There are two primary usages for Fielding:
- OCR Result Verification: The string returned is determined to be correct or incorrect based on the Field String and Field Definitions parameters.
- OCR Result Correction: The string returned is not among the list of acceptable results, and an attempt is made to find an acceptable string allowed by the field that is closest to the returned string.
A typical use-case for fielding is when the string contains prefix and/or suffix characters, and fielding is used to ignore those prefix/suffix characters. In this case, the Field String and Field Definitions determine the offset of the string position in the ROI.
Field String
Specifies the number of characters contained in the character string. A Field String entry can be any alphanumeric character found in the text entry dialog, including (A to Z), (ato z), (0 to 9), dashes(-), dots (.),and spaces ( ).
Each character in the FieldString corresponds to an indexed field position between 0 and 31. The Field String must contain at least the same number of positions as there are characters in the string for the read to pass (i.e. if there are 10 characters present, but the Field String only specifies 9 characters, the best matching 9 will be returned; however, if there are 8 characters present and the Field String defines 9 characters, the function will return #ERR). By default, each position in the FieldString is represented as an asterisk (*) character, or alphanumeric"wildcard."This means that any character is valid at any position in the string.
However, an individual position in the Field String can be limited to consider only a subset of possible characters at that position. This increases overall performance and reliability because characters that are not possible at a position will not be considered during a read.
The pre-defined FieldString entries are:
|
Field String Entry |
Description |
Valid Characters |
|---|---|---|
|
* |
Wild card |
Any trained character in the font. |
|
N |
Numeric |
0123456789 |
|
A |
Uppercase alphabetical |
ABCDEFGHIJKLMNOPQRSTUVWXYZ |
|
a |
Lowercase alphabetical |
abcdefghijklmnopqrstuvwxyz |
|
H |
Hexadecimal, uppercase alphabetical and numerical |
0123456789ABCDEF |
|
h |
Hexadecimal, lowercase alphabetical and numerical |
0123456789abcdef |
|
O |
Octal |
01234567 |
- To restrict a position in a Field String to a single character, simply enter that character. The character must have been trained in the font and cannot be one of the pre-defined FieldString entries listed above, unless it has been remapped using the Field Definitions parameter.
- To read a string containing a space, include the space in the FieldString. ReadText will not read a space if the corresponding Field String entry in that position is an asterisk (*).
- If the Field String parameter in the General tab is defined as a cell reference, the Field String option in the Fielding tab will be disabled, and the current value of the cell reference will be displayed.
If the FieldString is **********AN, any character in the font is valid in the first 10 Field String positions. But in the 11th position, only uppercase alpha characters will be considered during the read. And in the 12th position, only numeric characters will be considered.
The font contains only numeric characters 0-9 and /. If the Field String is NN/NN/NN, only numeric characters will be considered in the first and second, fourth and fifth, and seventh and eighth positions. Only the forward slash (/) character will be considered in the third and sixth positions.
But if the Field String is NN/NN/AA, the read would return #ERR because the font does not contain any alpha characters.
Field Definitions
Optionally, the Field Definitions settings can be used to create user-defined entries for the FieldString. When included in the FieldString, these entries restrict the list of valid characters at the positions in which they are inserted. There are several pre-defined field definitions, and user-defined field definitions can be added. The pre-defined definitions are displayed in grey text and may not be deleted or edited, only enabled or disabled. User-defined definitions are displayed in black text, can be added, deleted or edited. To add a field definition, press the Add New button, assign an icon for the Character and then assign a definition to the Character.
- The number of user-defined definitions is limited by the OCRMax function's expression length (249).
- Any user-defined definitions that are disabled when the OCRMax property sheet is closed will be removed and will not be available when re-opening the function's property sheet.
- If the Field Definitions parameter in the General tab is defined as a cell reference, the Field Definitions option in the Fielding tab will be disabled, and the current value of the cell reference will be displayed.
Characters listed for a Field Definitions entry must be contained in the font. For example: #=123 is valid if 1, 2, and 3 are included in the user-trained font. However,#=123 would be invalid if 1, 2, and 3 are not included in the font.
If the value of Field Definitions is #=123;$=3456;%=789, and the FieldString is #$%*******, then the only characters that will be valid in the first position will be 1, 2, or 3. The only valid characters in the second position will be 3, 4, 5, or 6. And in the third position, only 7, 8, or 9 will be valid. Any character in the font is valid in the fourth through tenth positions.
If the value of Field Definitions is #=123;$=3456;%=789, A=A, and the FieldString is #$%******A, then the only characters that will be valid in the first position will be 1, 2, or 3. The only valid characters in the second position will be 3, 4, 5, or 6. And in the third position, only 7, 8, or 9 will be valid. Any character in the font is valid in the fourth through ninth positions. Only the A character will be considered in the tenth position because the Field Definition A=A remaps the predefined FieldString entry.
Field Definitions Controls
-
Match Only Against Characters in Field String: Specifies whether the function will only attempt to match characters against characters indicated by the Field String.
Note: If the vision system is running 5.x.x firmware, when the Inspection Mode is set to Read/Verify, this parameter fields against the text string specified in the Match String parameter. -
Variable Length Strings: Specifies whether or not the defined Field String might be a sub-string within the complete read text string. If a sub-string is found, it will return the best-match sub-string.
Note: If the External Settings parameter is set as a reference to an OCRMaxSettings function, the Match Only Against Characters in Field String and Variable Length Strings parameters will be disabled. - Minimum Length: When the Variable Length Strings parameter is enabled, this parameter specifies the minimum acceptable string length (0 - 100; default = 1).
- Maximum Length: When the Variable Length Strings parameter is enabled, this parameter specifies the maximum acceptable string length (0 - 100; default = 25).
- Maximum Start Index: When the Variable Length Strings parameter is enabled, this parameter specifies the fielding subsequences to be considered, which must start at a position that is no greater than this index value (0 - 100; default = 100).
- Minimum End Index: When the Variable Length Strings parameter is enabled, this parameter specifies the fielding subsequences to be considered, which must end at a position that is no smaller than this index value (0 - 100; default = 0).
Results Tab
The Results tab displays the overall results and scores for each character, and is divided into two sections: Overall Results and Character Results.
Overall Results
- Status: Displays the function's overall result - Pass or Fail.
Character Results
-
Char: Displays the character read at that position.
-
Status: Displays the status (Bad Read, Good Read, Ignored, Confused, Mismatch, Confused Mismatch or Validation Failed) of the read character.
-
Bad Read: No characters scored high enough above the Accept Threshold to be considered a good read.
-
Good Read: The function successfully read the character at this position.
-
Ignored: When fielding is enabled, if a fielding string is specified and it is shorter than the string read by the function, the characters at the beginning or end of the string will be segmented (in yellow), but will not be included with the overall result. For example, if the fielding definition is ABC, and the string read by the function is "12ABC34", then "1234" will be ignored.
-
Confused: The function identified a character that scored high enough to be a good read (above the Accept Threshold parameter value), however, a different character scored close enough to the same score (within the Confusion Threshold parameter value), such that the function is not confident that it picked the correct character [Confused = (Primary Score - Secondary Score)/Confidence Threshold].
-
Mismatch: The function found a character that does not match the fielding, which scored much higher than any characters that do not match the fielding. It is likely that a character that does not match the fielding was printed at this position. Fielding must be enabled to return this status.
Note: The Mismatch status is only returned if the OCRMaxSettings function is being utilized and the function's Ignore Unfielded Characters is disabled. - Confused Mismatch: The function found a character that meets both the requirements of Confused and Mismatch.
- Validation Failed: If the OCRMaxSettings function is being utilized and the function's Skip Additional Character Validation parameter is disabled, the function will parse the characters through an additional validation step, to ensure that the function does not produce false reads.
-
- Score: Displays a score that measures how closely the read character matches the trained character in the font database.
- Confused With: Displays the next, best matching character.
- Confusion Score: Displays a measure of how certain the function is of the chosen match, when compared against the next, best match.
Diagnostics Tab
The Diagnostics tab displays information about how the OCRMax function segmented characters in the ROI. This data can be useful in determining which parameters to adjust, and how much, if characters and/or character fragments are not being correctly segmented. Use this tab in conjunction with the Show Diagnostics parameter for a graphic display of the diagnostic data.
Mainline Data
- Angle: Displays the angular orientation measurement of the character regions, relative to the ROI, in degrees.
- Skew: Displays the angular skew measurement of the character regions, relative to the ROI, in degrees.
- Pitch: Displays the minimum and maximum pitch measurement of the characters, in pixels.
- Inter-Character Gap: Displays the minimum and maximum measured inter-character gap, in pixels.
- Intra-Character Gap: Displays the minimum and maximum measured intra-character gap, in pixels.
Accepted Characters
- Width: Displays the minimum and maximum measured width of the accepted characters, in pixels.
- Height: Displays the minimum and maximum measured height of the accepted characters, in pixels.
- Size: Displays the minimum and maximum measured size of the accepted characters, in pixels.
Rejected Characters
-
Width: Displays the minimum and maximum measured width of the rejected characters, in pixels.
-
Height: Displays the minimum and maximum measured height of the rejected characters, in pixels.
-
Size: Displays the minimum and maximum measured size of the rejected characters, in pixels.
Note: If there are no rejected characters, #ERR will be displayed.
Accepted Fragments
- Size: Displays the minimum and maximum measured size of the accepted fragments, in pixels.
- Contrast: Displays the minimum and maximum measured contrast of the accepted fragments, as a percentage.
- Distance to Mainline (%): Displays the maximum Y distance of all the accepted fragments, as a percentage of the mainline height.
Rejected Fragments
- Size: Displays the minimum and maximum measured size of the rejected fragments, in pixels.
- Contrast: Displays the minimum and maximum measured contrast of the rejected fragments, as a percentage.
- Distance to Mainline (%): Displays the maximum Y distance of all the rejected fragments, as a percentage of the mainline height.
OCRMaxOutputs
|
Returns |
An OCRMax data structure containing the character string that was read, or #ERR if any of the input parameters are invalid. |
|
Results |
When OCRMax is initially inserted into a cell, a result table is automatically created in the spreadsheet. |
OCRMaxVision Data Access Functions
The following Vision Data Access functions are automatically inserted into the spreadsheet to create the result table. For more information, see OCRMax.
|
String |
GetString(OCRMax) |
Returns the text string in the referenced data structure. |
|
StringPass |
GetPassed(OCRMax) |
Returns the pass/fail status of the entire string in the referenced data structure. |
|
Index |
||
|
Char |
GetChar(OCRMax, Index) |
Returns the indexed character in the referenced data structure. |
|
Score |
GetScore(OCRMax, Index) |
Returns the match score (0 to 100) for the indexed character in the referenced data structure. |
|
Passed |
GetPassed(OCRMax, Index) |
Returns the pass/fail status of the indexed character in the referenced data structure. |
|
2nd Char |
GetChar(OCRMax, Index0, [Index1]) |
Returns the second highest scoring character. |
|
2nd Score |
GetScore(OCRMax, Index0, [Index1]) |
Returns the score of the second highest scoring character. |
|
Char Difference |
Returns the difference between the indexed character's Score and 2nd Score values. |