API
VisionPro Deep Learning は、全く同じ機能を API でサポートしています。また、次のプログラミング言語による API をサポートしています。
-
C (C++)
-
C# (.NET)
API の概要
API を利用する場合はまず、このドキュメントで説明されている VisionPro Deep Learning GUI の詳細をすべて確認することを強く推奨します。GUI と API は、VisionPro Deep Learning ツールを利用するための基本的な概念とウォークスルーをすべて共有しているからです。各プログラミング言語の API の詳細については、以下のパスにある API のドキュメントを参照してください。
-
C
-
API ドキュメント:
C:\Program Files\Cognex\VisionPro Deep Learning\2.1\Develop\docs -
コード例:
C:\ProgramData\Cognex\VisionPro Deep Learning\2.1\Examples\c++
-
-
C#
-
API ドキュメント:
C:\Program Files\Cognex\VisionPro Deep Learning\2.1\Develop\docs
-
コード例:
C:\ProgramData\Cognex\VisionPro Deep Learning\2.1\Examples\c++
-
ターゲットフレームワーク
- UI 以外の NuGet パッケージが NET Standard 2.0 を対象とするようになりました
- UI アセンブリと実行可能ファイルが .NET Framework 4.7.2 を対象とするようになりました
- UI 以外の実行可能ファイルが .NET Core 3.1 を対象とするようになりました
NuGet パッケージ
NuGet パッケージはプロジェクトベースであり、依存関係があります。 VisionPro Deep Learning .NET ライブラリは、可能な限り、クロスプラットフォームフレームワークを対象としてコンパイルされています。UI 関連のアセンブリはすべて、.NET Framework 4.7.2 または NET Standard 2.0 のいずれかを対象としてコンパイルされています。VisionPro Deep Learning は ViDi を継承するため、API の多くの部分で ViDi という名前が保持されています
| アセンブリ | フレームワークターゲット |
|---|---|
|
ViDi.NET.Local |
NET Standard 2.0 |
|
ViDi.NET.Logging |
NET Standard 2.0 |
|
ViDi.NET.Remote |
NET Standard 2.0 |
|
ViDi.NET.Remote.Service |
NET Standard 2.0 |
|
ViDi.NET.Remote.Client |
NET Standard 2.0 |
|
ViDi.NET |
NET Standard 2.0 |
|
ViDi.NET.Base |
NET Standard 2.0 |
|
ViDi.NET.Common |
NET Standard 2.0 |
|
ViDi.NET.Extensions |
NET Standard 2.0 |
|
ViDi.NET.Interfaces |
NET Standard 2.0 |
| ViDi.NET.UI.Interfaces |
.NET Framework 4.7.2 |
|
ViDi.NET.GUI |
.NET Framework 4.7.2 |
| ViDi.NET.UI |
.NET Framework 4.7.2 |
|
ViDi.NET.VisionPro |
.NET Framework 4.7.2 |
NuGet パッケージは、特定の Cognex Deep Learning Studio 機能を使用するために必要なアセンブリを簡素化するために導入されました。
たとえば、ViDi.NET.UI は、サードパーティアセンブリに必要なライセンスとともに、必要なアセンブリを正確に表示するようになりました。
VisionPro Deep Learning NuGet パッケージは次のディレクトリにあります:
-
C:\ProgramData\Cognex\VisionPro Deep Learning\X.X\Examples\packages
NuGet フィードは例で自動的に設定されますが、グローバル Visual Studio NuGet パッケージフィードに設定する必要があります。Cognex では、NuGet パッケージを別の安全なリポジトリ (または同等のもの) にバックアップし、コピーを保持することを強くお勧めします。この場所を新しい NuGet フィードとして設定する必要があります。詳細については、次の Microsoft トピックを参照してください。独自の NuGet フィードをホスティングする
ランタイム API 処理ガイド
フォーカスモードでは、処理が画像単位で行われるため、並列処理がサポートされます。API を使用してランタイムワークスペースでフォーカスツールを処理するためのコードワークフローを編成するときに、この並列処理を活用できます。ツールの並列処理の詳細については、このページを読む前に「NVIDIA GPU の選択と設定」を参照することを強くお勧めします。
ランタイム環境でVisionPro Deep Learning API を使用して処理タスクを実行する場合、API コードワークフローを編成するために、スレッド、GPU、サンプルなどのオブジェクトを処理します。
| オブジェクト | 説明/注意 |
| ワークスペース | スレッドセーフ |
| ストリーム | スレッドセーフ |
| ツール | スレッドセーフ |
| サンプル |
画像を処理するコンテナオブジェクト スレッドセーフではない |
| 画像 |
処理される実際の画像データを含むオブジェクト スレッドセーフではない |
| バッファ |
結果を受け取るオブジェクト スレッドセーフではない |
| スレッド |
複数の GPU デバイスを初期化する場合、API を呼び出して処理を開始するには 2 つの方法があります。
デバイスリスト引数として「空のリスト」を提供する
API を呼び出すときに「デバイスリスト」引数に空のリストを使用する場合、処理は利用可能な (占有されていない、解放されている) GPU で実行されます。つまり、特定のツールを処理する GPU をユーザは選択しません。この方法は、次の場合に推奨されます。
-
他の目的がなく、並列処理自体が必要な場合。
-
並列処理コードが機能しているかどうかをテストする場合。
-
コードの実装を、どのような状況でも常に並列で実行する必要がある場合。
-
処理の予想時間がほぼ同じ 2 つのツールを処理する場合 (特定の GPU を指定せずに並列処理を行うのに適している場合)。
-
1 つのツールを並列処理する場合 (複数の GPU を利用して並列処理により処理を強化したい場合)。
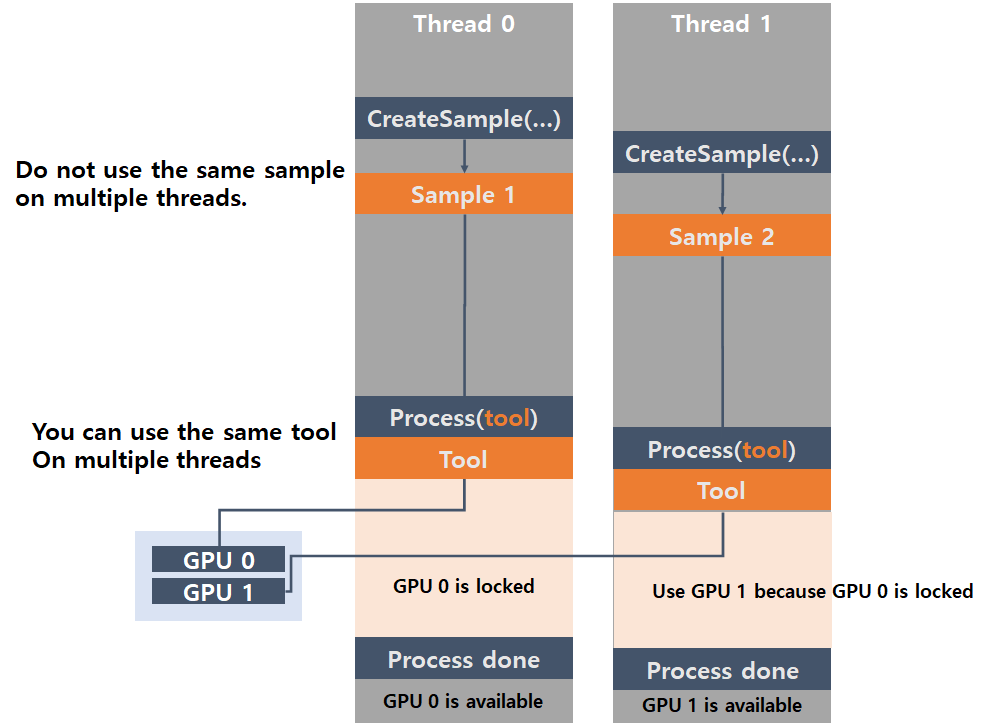
2 つのスレッドと 2 つの GPU で 1 つのフォーカスモードツールを処理するシンプルなケースに適しています。
デバイスリスト引数として空のリストを指定し、2 つのスレッド (スレッド 0 とスレッド 1) の両方でこのツールの処理を実行する場合、スレッドの 1 つ (スレッド 0) が 1 つの画像を処理する間だけ GPU 0 を占有します。
GPU 0 がスレッド 0 によって占有されている間、GPU 0 はロックされるため、スレッド 1 はGPU 1 にアクセスし、このツールの別の画像を処理するために占有します。
スレッド 0 は GPU 0 で 1 つの画像の処理を終了すると GPU 0 を解放し、スレッド 1 の処理ジョブが待機リスト (キュー) で待機していた場合はスレッド 1 が GPU 0 を占有できるようになります。このようにして、この単一のツールを 2 つの GPU と 2 つのスレッドで並列で処理できます。
デバイスリスト引数として「空でないリスト」を提供する
API を呼び出すときに「デバイスリスト」引数に空でないリストを使用する場合、処理は指定された「デバイスリスト」にある利用可能な (占有されていない、解放されている) GPU で実行されます。つまり、特定のツールを処理するために 1 つ以上の GPU のリストをユーザが選択します。この方法は、次の場合に推奨されます。
-
処理の予想時間が互いに大きく異なる 2 つのツールを処理する場合。つまり、このツールには GPU が単独で割り当てられていない場合、並列処理ではそれらの 1 つが互いにボトルネックとなる可能性があります。
-
特定のツールの処理に使用する GPU と使用しない GPU を制御する場合。
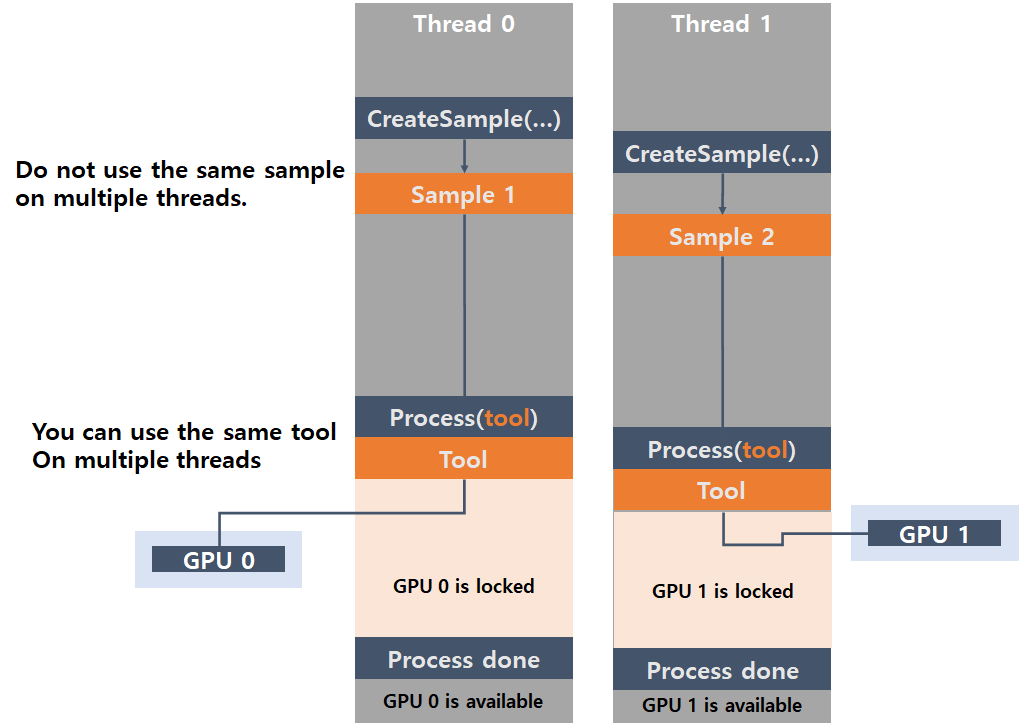
2 つのスレッドと 2 つの GPU で 1 つのフォーカスモードツールを処理するシンプルなケースに適しています。
デバイスリスト引数を使用してスレッド 0 に GPU 0 を含むリストを指定し、スレッド 1 に GPU 1 を含むリストを指定して、2 つのスレッド (スレッド 0 とスレッド 1) でこのツールの処理を実行する場合、GPU 0 はスレッド 0 に割り当てられ、GPU 1 はスレッド 1 に割り当てられます。
スレッド 0 は、特定の画像セットの処理ジョブが完了するまで GPU 0 のみを使用し、スレッド 1 と GPU 1 も同様です。
別のケースとして、今度は 2 つのスレッド (ツール A にスレッド 0、ツール B にスレッド 1) と 3 つの GPU (GPU 0、GPU 1、GPU 2) で 2 つのフォーカスモードツール (A、B) を処理するとします。ツール B が処理する画像の数がツール A よりも非常に多いか、ツール B の画像データの解像度がツール A よりもはるかに高いとすると、ツール B の処理に非常に時間がかかります。
このような状況でも、空のデバイスリストを使用して並列処理を行うことをお勧めします。合計処理時間 (A と B の両方の処理を完了するために必要な時間) は、空でないデバイスリストを指定した場合と比較して変わりません。
ただし、この場合の問題は、ツール B のワークロードが高いためにほとんどの場合は 3 つの GPU がスレッド 1 によって占有され、さらにフォーカスツールの処理が画像単位で実行されるために、ツール B の処理によってツール A の処理が遅くなる可能性があることです。
したがって、ツール A の処理が大幅に遅れることなく、ツール A と B の並列処理を行うには、スレッド 1 にデバイスリスト [GPU 1] または [GPU 1、GPU 2] を指定して、これらの GPU をツール B の処理専用にします。また、スレッド 0 にデバイスリストまたは空のリストを指定することもできます。これにより、並列処理でツール B がツール A のボトルネックになるのを防ぐことができます。
API による複数の GPU の使用
C API による初期化
C API による初期化は、VIDI_UNIT vidi_initialize(VIDI_INT gpu_mode, VIDI_STRING gpu_devices) 引数を使用して実行されます。
| GPU モード gpu_mode | GPU サポートなし | 1 つのツールに 1 つのデバイス |
|---|---|---|
|
整数値 |
-1 |
0 |
|
C 定義 |
VIDI_GPU_MODE_NO_SUPPORT |
VIDI_GPU_MODE_SINGLE_DEVICE_PER_TOOL |
以下を使用して処理する場合:
- vidi_runtime_process
- vidi_runtime_process_single_tool
- vidi_runtime_process_sample
- vidi_training_stream_process_sample
- vidi_training_tool_process_database
- vidi_training_process_sample
GPU デバイスの選択は、VIDI_STRING gpu_list 引数を使用して実行されます。
| GPU デバイス gpu_list | デフォルト値 | デバイスリスト |
|---|---|---|
|
文字列値 |
" " |
"0,1,2" |
|
C 定義 |
VIDI_AUTO_SELECT_GPU_DEVICE |
|
|
説明 |
使用可能なすべての GPU を使用します。 |
指定された GPU (0、1、2 など) だけを使用します。 |
.NET API による初期化
次のいずれかを使用して新しいコントロールを作成する場合:
- ViDi2.Runtime.Local.Control (ViDi2.GpuMode gpuMode, List<int> gpuDevice)
- ViDi2.Runtime.Local.Control (LibraryAccess libraryAccess, ViDi2.GpuMode gpuMode, List<int> gpuDevices, bool activateDebugLogging)
- ViDi2.Training.Local.Control (ViDi2.GpuMode gpuMode, List<int> gpuDevice)
- ViDi2.Training.Local.Control (LibraryAccess libraryAccess, ViDi2.GpuMode gpuMode, List<int> gpuDevices, bool activateDebugLogging)
| GPU モード | ViDi2.GpuMode gpuMode |
|---|---|
|
1 つのツールに 1 つのデバイス (デフォルト) |
GpuMode.SingleDevicePerTool |
|
GPU サポートなし |
Gpu.Mode.NoSupport |
以下を使用して処理する場合:
- ViDi2.Runtime.ITool.Process
- ViDi.Runtime.IStream.Process
- ViDi2.Training.ITool.Process
- ViDi.Training.IStream.Process
- ViDi2.IDatabase.Process
デバイスの選択は、List<int> gpuDevices 引数を使用して実行されます。
| List<int> gpuDevices | デフォルト値 | デバイスリスト |
|---|---|---|
|
値 |
null |
new List<int> {0,1} |
|
説明 |
使用可能なすべての GPU を使用します。 |
指定された GPU (0 や 1 など) だけを使用します。 |