速度の最適化
このセクションのトピックでは、VisionPro Deep Learning アプリケーションの処理時間を短縮するのに役立つヒントとコツを紹介します。
ツールとストリームの処理時間
以下に示すように、各ツールの処理時間はデータベースの概要に表示されます。
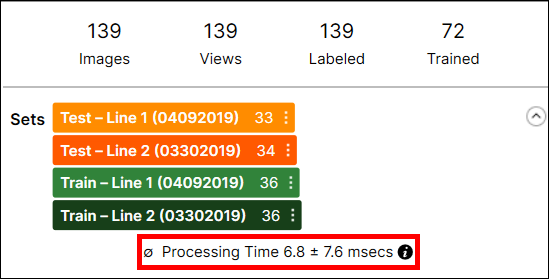
処理時間は、最後の処理タスクの画像あたりの平均処理時間であり、処理時間と後処理時間の合計です。
複数のツールが含まれるストリームの処理時間は、VisionPro Deep Learning GUI を通じて使用することはできません。処理時間には、ツール間のビュー情報の準備および転送に必要な時間が含まれるため、ストリームで各ツールのツール実行時を合計することで予測することはできません。
ストリームの処理に関して、Stream.Process() を呼び出した場合、ストリーム内のツールの処理は常にシリアル化されることに注意してください。明示的に Tool.Process() を使用して個別にツールを処理する場合を除き、一度に 1 つのツールのみが処理されます。
スループット
VisionPro Deep Learning 内で、スループットとは、時間単位あたり処理可能な画像の合計数を指します。アプリケーションが異なるスレッドを使用して、同時に複数のストリームを処理できる場合、システムのスループットを向上させることができますが、各ツールの処理が遅くなります。
ソフトウェア面: パラメータの最適化
このセクションのトピックでは、さまざまな VisionPro Deep Learning ツールのパラメータを最適化して、パフォーマンスを最大限にする方法について説明します。
| パラメータ | 特徴のサイズ | サンプリング密度 | カラーチャネル | 適合率 | 反復 |
|---|---|---|---|---|---|
| ツール | 位置決め、解析、分類 | 位置決め、解析、分類 | 位置決め、解析、分類 | 青 | 赤 |
| 処理時間 |
|
|
|
|
|
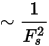
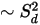
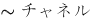

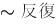
ツールのパラメータの選択内容は、ツールの実行速度に直接影響しますが、ツールの速度と、精度または堅牢性の間で通常トレードオフがあります。
| ツールのパラメータ | 速度にどのような影響を与えるか | ベストバリューオプション | 注意事項... |
|---|---|---|---|
| アーキテクチャ | High Detail モードの処理時間は、後処理と前処理のロジックがどちらも異なるため、通常、フォーカスモード (および SuaKIT セグメンテーション/分類) の処理時間よりも長くなります。 | ||
|
特徴のサイズ (フォーカスモード) |
ランタイム時に、Deep Learning ツールは入力画像全体をサンプリングする必要があります。特徴のサイズにより、指定された画像サイズに必要なサンプルの数が決まります。特徴のサイズが大きいほど、サンプル数が少なくなります。 |
O(n2) は、より大きな特徴のサイズで速度を上げます。 |
より大きな特徴サイズは、ツールによる特徴または欠陥の検出ミスにつながる可能性があります。 パラメータ検索のパラメータ最適化ユーティリティを使用すると、最適な特徴サイズを検出することができます。 |
|
サンプリング密度 (フォーカスモード) |
特徴のサイズと同様に、サンプリング密度により、指定された画像サイズに必要なサンプルの数が決まります。 |
O(n2) は、より小さなサンプリング密度で速度を上げます。 |
特徴または欠陥の検出ミスのリスク。 |
|
調整パラメータ |
位置決め (青) ツールおよび解析 (赤) ツールには、実行時間は増加しますが、より正確な結果を提供する、次の処理時間パラメータが含まれます。
|
反復値を増加すると、処理時間は線形に増加します。 |
|
|
低適合率 (フォーカスモード) |
システムが所定の要件 (CUDA Compute Capability 6.1 以降) を満たす場合、解析 (赤) ツールおよび分類 (緑) ツールの低適合率処理モードを有効にすることができます。低適合率モードを有効にすると、既存の学習済みツールは、処理時に低適合率コンピューティングモードを使用するように変換され、無効にするまで、それ以降のすべての学習操作において低適合率ツールを生成します。 Note: ツールが低適合率モードを使用するように変換された場合、低適合率モードを無効にするように再学習させる必要があります。低適合率ツールは、通常の適合率ツールより 25% から最大で 50% まで高速で実行できます。
|
低適合率ツールの追加のランタイム速度の向上は、Turing Tensor コア搭載のシステムで見られます。 | 低適合率モードを使用するようにツールを変更すると、ツールが生成する結果が微妙に変動する場合があります。一般的に、高レベルな特徴の識別、欠陥の分類、および一般的な分類は変化しませんが、特定の特徴と欠陥領域、および得点は若干変化する場合があります。 |
特徴のサイズの最適化
特徴のサイズは、処理時間 (n2) に大きく影響します。つまり、特徴のサイズが 100 の場合は、サイズが 10 の場合よりも 100 倍高速ですが、特徴のサイズが 15 より小さいと通常良い結果は得られません。
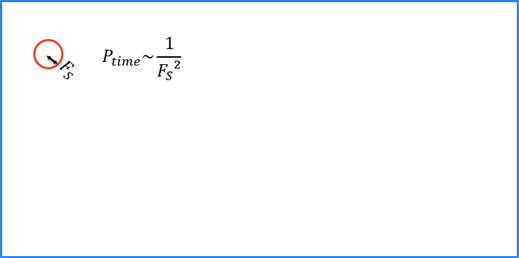
学習およびランタイムの両方で、各 Deep Learning ツールは画像の範囲を完全にカバーする画像サンプルを収集します。
特徴のサイズは実行するのに必要な時間に直接関連していますが、ツールの学習への影響は比較的小さいです。特徴のサイズが大きいほど短時間で処理を行うことができますが、特徴のサイズが大きいと小さな特徴を「検出」したり、小さな特徴に「応答」したりすることができません。
学習中は、ツールは入力画像の全範囲のサンプリングを行い、詳細を含んでいるとツールが判断した領域のオーバーサンプリングを行います。
サンプリング密度の最適化
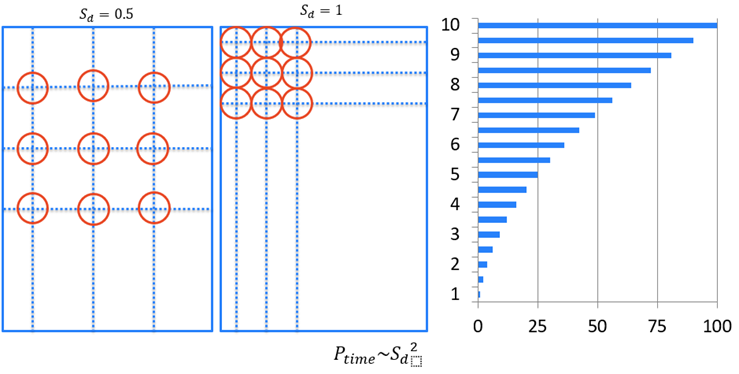
[サンプリング密度] パラメータは、画像をどの程度の密度でサンプリングするかを決定します。数字が小さいほど、画像のサンプル数は少なくなります。
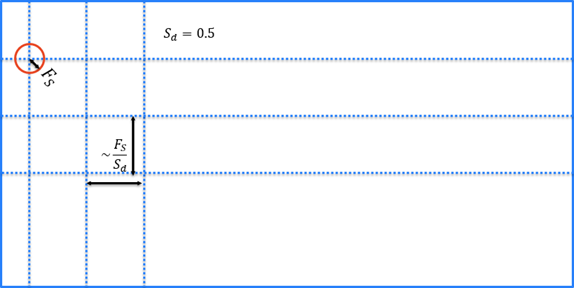
[サンプリング密度] を 0.5 に設定すると、1 [0(n2)] を設定した場合の 4 倍の速さになります。
カラーチャネルの最適化
アプリケーションがカラー画像に依存している場合は、最小限必要な数のカラーチャネルのみを使用し、正しい数のチャネルを持っている画像のみを送信して変換を回避してください。その理由は次のとおりです:
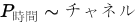
適合率の最適化
位置決め (青) ツールには、固有のパラメータである [適合率] が含まれています。このパラメータを使用して、ツールが目的の位置適合率に達した後に特徴の検索を停止するタイミングを示します。これは、検索されている特徴のサイズの割合として設定されます。
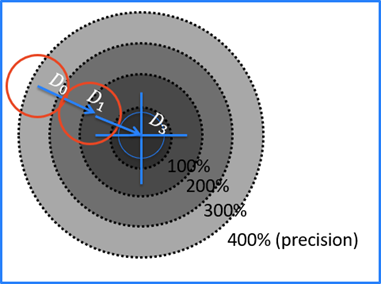
適合率が 400% になると、位置決め (青) ツールは D0 で停止します。
200%: D1
100%: 適合率と一致
停止基準: 

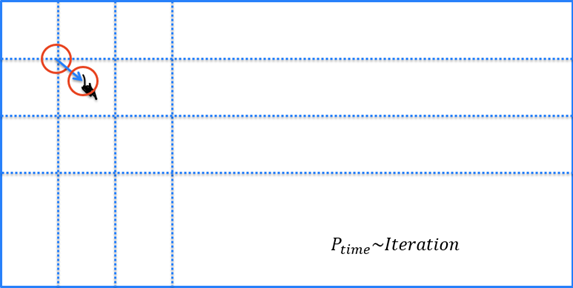
反復の最適化
解析 (赤) ツール – アンスーパーバイズドモードでは、ツールが [エキスパートモード] の場合、追加のパラメータ [反復] があります。このパラメータは、ツールが解析結果をローカルで改善するために実行する、対象領域における追加の反復回数を指定します。
ソフトウェア面: 対象領域 (ROI) の最適化
対象領域 (ROI) を設定する場合は常に、できるだけ小さい ROI を作成するようにします。また、解析 (赤) ツールを使用する場合は、アプリケーションに関連しない画像内のすべてをマスクします。
ハードウェア面: GPU の最適化
以下は、Windows で GPU ドライバモードを選択する際の考慮事項です。
Tesla Compute Cluster (TCC)
- NVIDIA RTX / Quadro®、Tesla®、および GeForce® GTX TITAN 専用 (ただし、NVIDIA からは正式に通知されていません)。
- 表示に GPU は使用できない。
- NVIDIA RTX / Quadro® の場合、デフォルトのモードは WDDM。
Windows Display Driver Model (WDDM)
- NVIDIA GeForce® または NVIDIA RTX / Quadro® 向け。
- GPU は、表示と計算で共有。
メモリ割り当て時間
- WDDM >> TCC
マルチ GPU 構成の改善
- WDDM << TCC
解決策:
- TCC を搭載した NVIDIA プロフェッショナルまたは GeForce® GTX TITAN カードのみを使用します。
- VisionPro Deep Learning の GPU メモリの最適化機能を使用します。
GPU メモリの最適化

VisionPro Deep Learning メモリ使用量:
- ディスプレイ: 計算前に画像を保存するためのメモリ
- VisionPro Deep Learning 予約済み: 計算用に予約されているメモリ
- 空き: 使用されているメモリの量が不明であるため、空き状態になっているメモリ
学習の例:
- 2.5GB の予約済みメモリ (学習用の最小値)
- 約 1GB の空きメモリ
- その結果、3.5GB 以上のメモリを搭載したグラフィックカードになる
ランタイムの例:
- 512MB の予約済みメモリ
- 約 256MB の空きメモリ
- その結果、最小限のメモリを必要としないグラフィックスカードになる
GPU メモリの最適化機能 (デフォルトで有効になっており、デフォルト値 2GB を使用) を使用すると、Windows Display Driver Model (WDDM) ドライバと Tesla Compute Cluster (TCC) ドライバで速度が大幅に改善されます。ただし、アプリケーションによっては、予約メモリを慎重に選択する必要があります。パフォーマンスが最も向上するのは、小さい画像を処理するアプリケーションの場合です。
| 長所 | 短所 |
|---|---|
|
グラフィックスカードのメモリを予約する |
予約するメモリの正しい量を見積もるのが難しい |
|
メモリ割り当てのための時間損失がない |
-
このオプションをオンにすると、ツールの最適化のために GPU メモリが事前に割り当てられます。学習と処理を高速化するためにフォーカスモードツール (解析 (赤) フォーカス - スーパーバイズド/アンスーパーバイズド、位置決め (青)、読み取り (青)、分類 (緑) フォーカス) を使用する場合は、このオプションをオンにすることをお勧めします。
-
このオプションをオフにすると、GPU メモリの事前割り当ては行われません。High Detail モードおよび High Detail Quick モード (分類 (緑) High Detail、解析 (赤) High Detail、分類 (緑) High Detail Quick) の学習では、学習速度が遅くなるため、このオプションをオフにすることをお勧めします。
API またはコマンドライン引数を使用して、機能を無効にしたり割り当て設定を変更したりできます。
たとえば、.NET API では、次のように設定します (control.OptimizedGPUMemory(2.5*1024*1024*1024ul);)。C API では、次のように設定します (vidi_optimized_gpu_memory(2.5*1024*1024*1024);)。
複数の GPU の最適化
VisionPro Deep Learning は、複数の GPU を使用して、アプリケーション全体に GPU リソースを分散させることができます。Deep Learning ツールごとに単一の GPU を使用するとスループットが最大になり、ツールごとに複数の GPU を使用すると遅延を最小限に抑えられます。ここで、スループットは特定の時間内に処理されるタスクの量を意味し、遅延は API メソッドを呼び出してから処理結果を受け取るまでにかかる時間を意味します。
-
スループット/秒:1 秒/遅延
-
スループット/分:60 秒/遅延
複数の GPU の使用の詳細については、「NVIDIA GPU の選択と設定」と「複数 GPU の設定」を参照してください。
ランタイムパフォーマンスの予測
次の数字は、異なるカードファミリの潜在的なランタイムパフォーマンスの増加についてのおおよそのガイドです (ベースライン = 非 TensorCore、標準モード)。
| ディープラーニング操作モード |
Tensor Cores なし (例 GTX) |
Volta Tensor Cores (例 V100) |
Turing Tensor Cores (例 T4) |
|---|---|---|---|
|
標準 |
100% |
150% |
150% |
|
低適合率 |
125% |
125% |
175% |