画像の収集
どのような画像を収集するのか?
従来の手法かディープラーニングかを問わずすべてのマシンビジョンアプリケーションにとって、品質とコントラストの高い画像であることが重要な要素です。Deep Learning アプリケーションでは、画像が主な入力であり、ツールの学習に使用される画像によってその成功が決まります。また、ツールの学習に使用される画像は、ツールの展開時に使用される画像と同等でなければなりません。そのため、学習時の画像がより一貫性があり正確な表現であるほど、展開時のツールのパフォーマンスがより優れたものとなります。また、重要なことは、画像の品質が低い場合、ディープラーニングとその機能によってそれを補完することはできないという点です。「garbage in, garbage out (無意味なデータをコンピュータに入力すると無意味な結果が返される)」の原則が適用されます。入力の品質は、Deep Learning によって達成できる結果の品質に直接影響します。
Deep Learning のプログラミングにおいて最も重要な要素は、展開フェーズでソフトウェアに発生する可能性がある事象に基づいて、画像セットを作成することです。画像には、正確な判断を下すために、Deep Learning に必要なあらゆる情報を含める必要があります。目視検査によって欠陥を検査するため、部品を選定し、手動で傾け回転させる場合のシナリオを考えてみましょう。この場合、それら欠陥をキャプチャするため、角度のある画像または照明が必要となる可能性が示唆されます。
他には、人間の検査員が部品上のほこりや油脂を確認し、それらを取り除いて、手動でほこり/油脂を拭き取る場合のシナリオが考えられます。このようなほこり/油脂が欠陥と誤認識される可能性がある場合、ほこり/油脂について Deep Learning に学習させる必要があります。この画像セットには、カメラによってキャプチャされる可能性のあるバリエーションの範囲のすべてを含める必要があります。この場合の目標は、データセットを正しく汎化することです。汎化とは、学習時に使用されなかった新たに取得された画像で使用される場合、ツールがどのくらい効果的であるかを判断するディープラーニングの概念を指します。適切に汎化されたツールは、新しいデータでもパフォーマンスに優れています。このシナリオでは、ニューラルネットによって形成されたモデルは、初期学習セットに適合し、未確認の画像に見られる新しいデータについて考慮する必要があります。
画像ファイルと形式の要件
VisionPro Deep Learning でサポートされている入力画像チャネル、ビット深度、画像ファイル形式、および VisionPro Deep Learning へのインポート後に変換される画像チャネル、ビット深度、画像ファイル形式については、以下の表を参照してください。この表に記載されていない画像チャネル、ビット深度、および画像ファイル形式は、VisionPro Deep Learning ではサポートされていません。
| VisionPro Deep Learning へのインポート前 | VisionPro Deep Learning へのインポート後 | ||||
| 入力 画像チャネル |
入力 画像ビット深度 |
入力 画像ファイル形式 |
インポート済み 画像チャネル |
インポート済み 画像ビット深度 |
インポート済み 画像ファイル形式 |
| 1 チャネル | 8 ビット | bmp | 1 チャネル | 8 ビット | png |
| 1 チャネル | 8 ビット | jpg | 1 チャネル | 8 ビット | png |
| 1 チャネル | 8 ビット | png | 1 チャネル | 8 ビット | png |
| 1 チャネル | 8 ビット | tiff | 1 チャネル | 8 ビット | png |
| 1 チャネル | 16 ビット | png | 1 チャネル | 16 ビット | png |
| 1 チャネル | 16 ビット | tiff | 1 チャネル | 16 ビット | png |
| 3 チャネル | 8 ビット | bmp | 3 チャネル | 8 ビット | png |
| 3 チャネル | 8 ビット | jpg | 3 チャネル | 8 ビット | png |
| 3 チャネル | 8 ビット | png | 3 チャネル | 8 ビット | png |
| 3 チャネル | 8 ビット | tiff | 3 チャネル | 8 ビット | png |
| 3 チャネル | 16 ビット | png | 3 チャネル | 16 ビット | png |
| 3 チャネル | 16 ビット | tiff | 3 チャネル | 16 ビット | png |
| 4 チャネル | 8 ビット | bmp | 4 チャネル | 8 ビット | png |
| 4 チャネル | 8 ビット | png | 4 チャネル | 8 ビット | png |
| 4 チャネル | 8 ビット | tiff | 4 チャネル | 8 ビット | png |
| 4 チャネル | 16 ビット | png | 4 チャネル | 16 ビット | png |
| 4 チャネル | 16 ビット | tiff | 4 チャネル | 16 ビット | png |
最大画像サイズと寸法
次のガイドラインは、これらの操作パラメータ内で Deep Learning アプリケーションを最適に設定する方法を判断するのに役立ちます。以下の表の数値 (たとえば、ストリームあたりの画像の最大数) は実験的にテストされたものであり、値は使用するハードウェア設定によって多少異なります。一般的に、メモリ (GPU RAM ではない) とハードディスクの容量が大きいほど、処理できる画像の数とサイズが大きくなります。
-
最大画像サイズ (チャネルパラメータを 1 ~ 4 に設定)
- 最高 32MP (高さまたは幅が最高 16k) の画像をサポート
- 幅が最高 32k ピクセル (GPU リソースに応じた 1 つの寸法) の画像
- 32k を超える画像はサポート不可
- 解析 (赤) のストリームあたりの画像の最大数
- 1000
- 解析 (赤) の画像あたりの欠陥の最大数
- 1000
画像のキャプチャ
Deep Learning ツールは、画像や照明のバリエーションに対応できますが、そのバリエーションがどのようなものであるかをツールに学習させる必要があります。画像によって照明が明るい、または暗い場合は、画像にそのバリエーションをキャプチャし、学習画像セットにそれらの画像を追加することによって照明のそのバリエーションを使用してツールを学習させます。
照明および画像のオプションを設定するときに、一般的なマシンビジョンの照明および光学系の技術を使用することができます。ただし、Deep Learning で、照明および光学系が学習と生産の間で一貫していることを確認してください。たとえば、特定の照明および光学系の設定に基づいて画像を学習させてから、ツールのパフォーマンスはその初期設定に基づくため、生産中にその設定を変更した場合、生産時に動作不良となります。
可能な場合、制御された照明を使用すると、照明の設定における差異につながる可能性がある周囲の照明や視覚的変化によって生じる影響を避けることができます。カメラをセットアップする場合、ラボ内のカメラのセットアップが生産時に使用されるセットアップと同じであることを確認してください。また、遠近歪み、レンズのフォーカス、被写界深度、および視野における変化を最小限にするようにしてください。
画像を VisionPro Deep Learning に読み込む
ワークスペースが追加されるか、開かれた後で、[データベース] メニューから ([画像の追加] を選択して)、GUI の表示スペースにある [画像の追加] を押す、または Windows エクスプローラーから画像をドラッグしてビューブラウザにドロップすることで、画像を追加することができます。
画像ファイルを読み込む
ビューブラウザで画像ファイルを読み込む

メインメニューで画像ファイルを読み込む
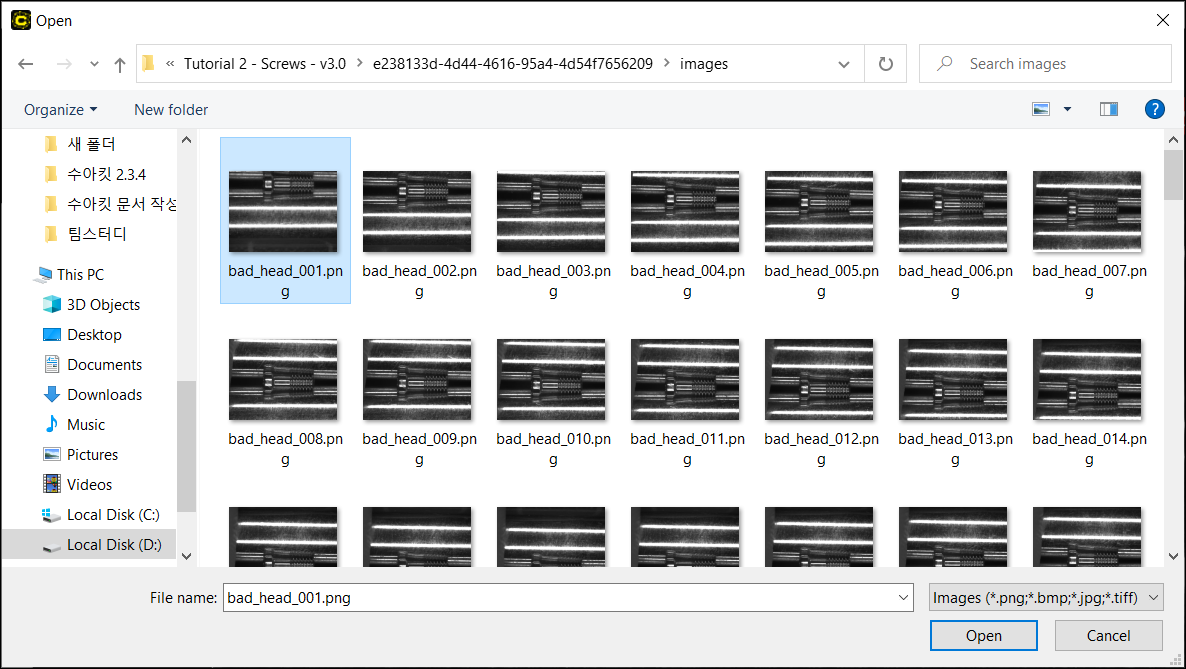
複数の画像ファイルを読み込む
ビューブラウザで複数の画像ファイルを読み込む

メインメニューで複数の画像ファイルを読み込む
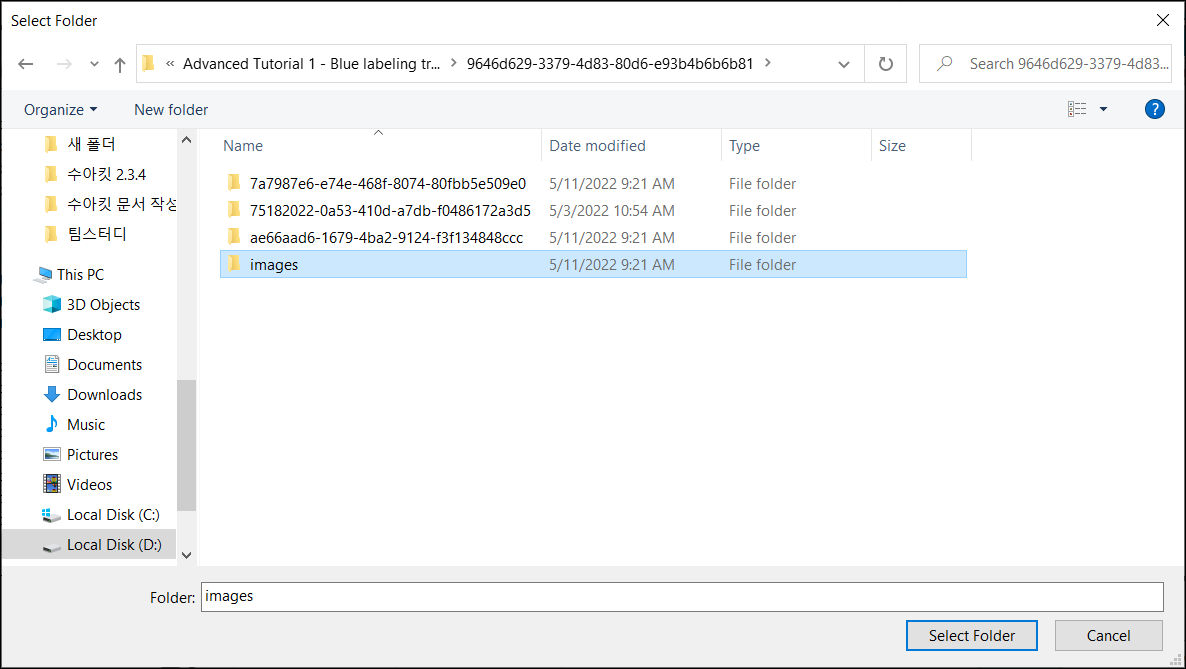
画像を追加すると、画像のサムネイルがビューブラウザの GUI の右側に表示されます。ビューブラウザから画像を選択すると、画像がアクティブになり、[画像表示領域] に表示されます。