ニューラルネットワークの処理 (推論)
ランタイム時には、ランタイム画像からの各サンプルが、ツールの学習済みネットワークを使用して個別に処理され、サンプルごとに個々のネットワーク応答が取得されます。ネットワークからの応答は、確率マップとして表現されます。つまり、サンプリングされた入力画像の領域内の各ピクセルに確率が割り当てられます。確率マップの意味は、どのツールが使用されているかによって異なります。解析 (赤) フォーカススーパーバイズド に対しては、応答はサンプリング領域内の各ピクセルが画像の欠陥内に存在する確率になります。これらの画像全体の確率マップは、個々のサンプルに対して補間されたネットワーク応答から収集されます。ユーザに返される最終結果 (特徴のポーズと識別、欠陥領域) は、ユーザが欠陥の確率に対するしきい値を指定することで制御する結果の形成プロセスに基づきます。
上のコンテキストでは、ツールによって返される確率は、我々が特定の判断を下す可能性をそのまま反映したものではないこともあります。これは、ツールの "世界観が限られている" ことが主な原因です。つまり、我々の広範囲にわたる豊富な視覚経験に対してではなく、少数のクラスの非常に限られた視覚の世界に関する確率が返されるためです。
学習済みツールの処理 (推論) は、問題なく学習が終了すると自動的に実行されます。学習済みツールを手動で再処理する場合は、![]() ボタンをクリックします。
ボタンをクリックします。
処理に特徴のサンプリングを使用する
各入力画像はランタイム時に徹底的にサンプリングされ、その後個々のサンプルが学習済みネットワークによって処理されます。学習に使用されるものと同じ特徴のサイズがランタイム時にも使用されます (学習に使用された入力と一貫した入力を学習済みネットワークが処理するようにするため)。
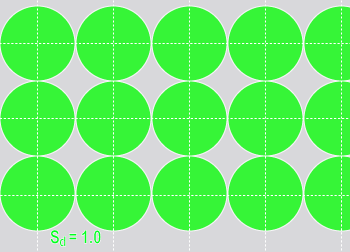
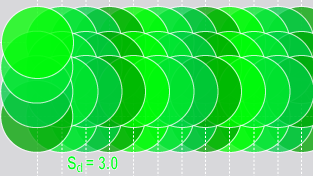
サンプリング密度が自動的に決定される学習とは異なり、ランタイム時のすべての Deep Learning ツールに対するサンプリング密度は制御が可能です。サンプリング密度は隣接するサンプル間の重なり度合いを決定します。1 のサンプリング密度レートは、サンプリング位置がサンプル間の特徴のサイズによって増分されることを意味します。ほとんどのツールのデフォルトのサンプリング密度レートは 3 です。これは、サンプリング位置が特徴のサイズの 3 分の 1 で増分されることを意味します。
| サンプリング密度 = 1 (4 つのサンプル) | サンプリング密度 = 3 (4 つのサンプル) |
|---|---|
|
|
|

処理パラメータの設定
The Processing parameters control the way that images are processed by the tool. This is often called ‘inference’ in deep learning. Processing with the same models will always give you the same results. Changing these parameters does not require the tool to be retrained; the effect can be seen right away by reprocessing the database. ツールの再処理を行うには、![]() ボタンをクリックします。
ボタンをクリックします。
| パラメータ | 説明 | ||||
|---|---|---|---|---|---|
|
サンプリング密度 |
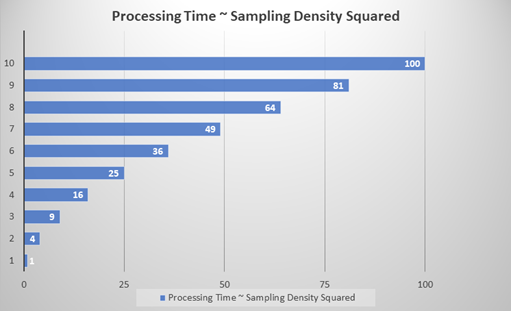
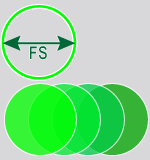
ツールの [特徴のサイズ] (FS) 設定に対するサンプリングポイントの密度を指定します。サンプリング密度は隣接するサンプル間の重なり度合いを決定します。1 のサンプリングレートは、サンプリング位置がサンプル間の特徴のサイズによって増分されることを意味します。ほとんどのツールのデフォルトのサンプリングレートは 3 です。これは、サンプリング位置が特徴のサイズの 3 分の 1 で増分されることを意味します。 Tip: [サンプリング密度] パラメータの 1 つの重要な側面は、ツールの処理時間と精度の関係です。ツールの処理時間は、[サンプリング密度] (Sd) の値にほぼ 2 次関数的に変化します。たとえば、1 の [サンプリング密度] 設定は、3 の設定よりも約 9 倍高速になります (n2)。[サンプリング密度] 設定が高いほど精度がより高くなり、ツールの処理時間に大きく影響します。
|
||||
|
しきい値 |
T1 と T2 の 2 つの設定があります ([T1,T2] と表す)。これらは、領域が検出され、良好または不良としてマークされるかどうかを判断するためのしきい値を決定します。T1 より下の値は良好として分類され、T2 より上の値は不良として分類されます。T1 と T2 の値は、「データベースの概要」の [得点] グラフィックを使用してインタラクティブに設定することもできます。 |
||||
| 自動 | [自動] (自動しきい値) を有効にすると、ドロップダウンメニューの各基準に従って、[データベースの概要] のコンフュージョンマトリックスの F1 得点が最大になる T1 および T2 しきい値が計算されます。4 つの基準は [データベースの概要] の [カウント] ドロップダウンメニューの基準と同じです。詳細については、「得点カウントフィルタ」を参照してください。 | ||||
|
単純領域 |
ツールが「単純領域」(つまり、穴のない多角形) のみを抽出するように指定します。 |
||||
|
見つかった領域の基準として使用するツールのフィルタを指定します。フィルタを指定することで、フィルタに一致しない領域は結果から削除されます。パラメータを空白のままにした場合は、すべての領域が返されます。 Note: フィルタのシンタックスは、表示フィルタに使用されるシンタックスと同じです。詳細については、「カスタム表示フィルタ」を参照してください。
使用可能な領域のプロパティは、次のとおりです。
|
|||||