ニューラルネットワークの学習
すべてのビューが正しくラベル付けされ、学習画像とテスト画像に分割された後、ニューラルネットワークの学習は、次の一般的な方法で実行されます。
- ツールのパラメータを設定し、学習を開始します。[ブレイン] アイコンを押して、ツールを学習させます。アーキテクチャが フォーカス の場合、学習に使用されている画像セット内の各画像 ([学習セット] ダイアログで定義) が、指定された特徴のサイズを使用して全体でサンプリングされます。
- 結果のサンプルが、VisionPro Deep Learning ディープニューラルネットワークに入力として提供されます。
- ニューラルネットワークは、サンプルごとに特定の応答 (ツールの種類に応じて) を生成し、この応答が、学習画像内のサンプルの位置に関連付けられた画像のラベル付けと比較されます。
- サンプルが処理され、再処理されるにつれて、ネットワーク内部の重みが繰り返し調整されます。ネットワーク学習システムは、ネットワークの応答とユーザによって提供されたラベル付けの間の誤差 (差異または不一致) を低減することを目標にして、ネットワークの重みを絶えず調整します。
- すべての学習画像サンプルが、エポック数パラメータで指定された回数以上含まれるまで、このプロセス全体が何度も繰り返されます。
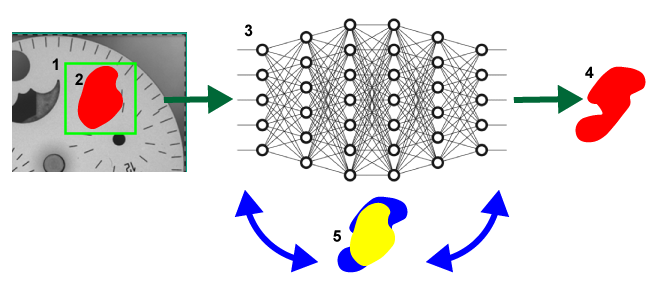
-
サンプリング領域。
-
ユーザが描画したラベル付き欠陥領域。
-
ニューラルネットワーク。
-
ネットワークによる応答。
-
ラベル付き欠陥 (黄) とネットワークの応答 (青) の間の不一致 (つまり、誤差) を低減するために重みを繰り返し調整するプロセス。
ニューラルネットワークの学習の特性は、学習させているツールの種類に応じて多少異なります。スーパーバイズドモードの解析 (赤) ツールのネットワークの学習目標は、欠陥のラベル付けと検出された欠陥の間の空間的不一致を低減することです。解析 (赤) フォーカススーパーバイズド の場合、ネットワークには、画像内の欠陥領域を見つけて識別することを学習させます。スーパーバイズドモードで解析 (赤) ツール用に行うラベル付けでは、ラベル付き画像内のすべての欠陥ピクセルにラベルを付けます。画像内の特定のサンプリング領域の場合、ネットワークの学習目標は、欠陥ピクセルを欠陥として正しく識別することです。
-
サンプリング領域とサンプリングパラメータ
解析 (赤) フォーカススーパーバイズド は、ユーザがサンプリングパラメータで定義したサンプリング領域に関連付けられたサンプラーでピクセルをサンプリングするため、学習を開始する前にサンプリングパラメータを設定してサンプリング領域を決定する必要があります。サンプリング領域に欠陥ピクセルが含まれていない場合は、ネットワークが応答を生成しない必要があります。
-
検証を使用した学習
解析 (赤) フォーカススーパーバイズド は、検証スキームを使用した学習をサポートしていないため、検証データセットを持たず、ツールパラメータで検証セットを設定する必要もありません。検証データを採用する目的は、学習した各ニューラルネットワークを検証し、この検証データの結果に基づいて、指定された学習セットで最もパフォーマンスが高く安定したニューラルネットワークを選択することです。
ツールのパラメータの設定
ツールが追加された後は、ツールのパラメータにアクセスして学習前のツールのパフォーマンスと、ツールがランタイム操作中に画像をどのように処理するかを微調整できます。VisionPro Deep Learning ツールのパラメータは、ニューラルネットワークモデルの学習方法とツールの統計結果の処理方法を調整します。ほとんどのアプリケーションで、調整する最も一般的なツールのパラメータは次のとおりです。
- 特徴のサイズ
- 学習セット
- 摂動
- サンプリング密度
アーキテクチャパラメータ
アーキテクチャパラメータ は、使用されるニューラルネットワークモデルのタイプを選択します。このオプションは、精度の高い結果の取得に有用ですが、学習およびプロセス時間が長くなります。High Detail モード設定および High Detail Quick アーキテクチャ設定では、画像全体が公平に考慮されるようツールが構成されます。一方、フォーカスアーキテクチャ設定は選択的で、有用な情報を含む画像の部分に照準が合わされます。そのため、特に画像のあらゆる場所に重要な情報が存在する場合、重要な情報を十分にネットワークで伝送できない可能性があります。
ネットワークモデルパラメータ
ネットワークモデルパラメータを使用すると、学習ツールネットワークのサイズを削減できます。それによって、処理に必要な時間も短縮されます。デフォルト値 (大規模) は、標準のツールの動作とパフォーマンスを保持します。他の 2 つの値である [小規模] と [中程度] は、より高速なランタイム実行時間を提供します。
[大規模] 以外の値を選択すると、ツールの結果が異なる場合があります。これらの違いは通常はささいなものですが、このオプションを使用する場合は、独自のラベル付きデータを使用してツールのパフォーマンスを検証する必要があります。
サンプリングパラメータ
特徴とは、画像データの中で対象となるピクセルであると同時に、マシンビジョンの問題を解決し、特定の目標を達成するために重要なピクセルのことです。たとえば、解析 (赤) ツール用のビューで、特徴は正常/欠陥ピクセルとなります。
フォーカスモードツールの場合、ツールを効果的に学習させるには、特徴がどのようなものかをできるだけ詳細に指定する必要があります。この仕様は、サンプリングパラメータを設定することで達成されます。フォーカス ツールでは、ビューからピクセル情報をサンプリングする特徴のサンプラーを使用します。サンプリングパラメータを設定することで、この特徴のサンプラーにサンプリングすべき特徴とそうでない特徴のプロパティを伝えます。
サンプリングツールのパラメータは、画像が学習中および処理中にサンプリングされる方法を制御します。
| パラメータ | 説明 | ||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
特徴のサイズ |
一般的な特徴の直径 (ピクセル単位) を指定します。[特徴のサイズ] パラメータは、画像の左下にグラフィックで表示され、その画像内でグラフィックを使用してサイズ変更することで、さらに正確なサイズを設定できます。 特徴のサイズは、処理時間 (n2) に大きく影響します。つまり、特徴のサイズが 100 の場合は、サイズが 10 の場合よりも 100 倍高速ですが、特徴のサイズが 15 より小さいと通常良い結果は得られません。 [特徴のサイズ] を設定するときは、処理時間 (P時間) に関して次の点を考慮してください。
Note: ツールは、実際には [特徴のサイズ] 設定よりも 5 倍大きい領域を視野に含めることになります。ただし、周辺部とは対照的に、特徴の中心部により詳細なレベルが表示されます。
|
||||||||||||||||||||||||||||||||||||||||||
|
カラー |
画像をサンプリングするときに使用するカラーチャネルの数を指定します。1 に設定されている場合、カラー画像はグレースケールに変換されます。
Note:
|
||||||||||||||||||||||||||||||||||||||||||
|
境界線タイプ |
画像の外部のピクセルがサンプリングされる方法を指定します。 Tip: 画像の境界にマスクを追加すると、誤検出率が大幅に減少します。
|
||||||||||||||||||||||||||||||||||||||||||
|
マスキングモード |
マスクがサンプリングされた画像にどのように適用されるかを指定します。ツールによって処理される画像の領域を制限するためにマスクが使用されます。 Note: マスクは学習後に設定できますが、学習前に設定すると、学習フェーズに役に立ちます。
|
||||||||||||||||||||||||||||||||||||||||||
|
中心 |
ビューの中心に対して円対称のオブジェクトが検査に含まれている場合に、このパラメータを使用して、オブジェクトが事実上展開される可能性があるため、結果として得られる学習モデルが単純になるようにします。 |

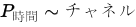


- [境界線タイプ]、[マスキングモード]、および [中心] パラメータは、[エキスパートモード] が有効になっている場合にのみ利用できます。
- ツールの学習が終了した後にサンプリングパラメータを変更すると、基礎となる画像統計が根本的に変化するため、学習が無効になります。これによって、ツールの再学習が必要になります。
サンプリングパラメータの詳細:特徴がどのようにサンプリングされるか
フォーカスモードの分類 (緑) ツール、フォーカスモードの解析 (赤) ツール、位置決め (青) ツール、および読み取り (青) ツールは入力画像を均一にサンプリングしません (ただし画像のサンプリングは画像全体で行われます)。学習中、ツールは特殊な技術を使用して、ネットワークに追加の情報をもたらす可能性が高いと見なされた画像の部分をより高い割合で選択的にサンプリングします。
ネットワークの学習は、サンプル領域内の情報と、サンプル領域の周囲からのコンテキスト情報の両方を使用して実行されるため、画像のエッジで収集されるサンプルからの影響を大きく受ける場合があります。画像内のビューを使用している場合、ビューのエッジで収集されるサンプルのコンテキスト情報では、ビューの外側にあるピクセルもコンテキストデータを取得するために使用されます。
|
|
|
|
|
1 |
特徴のサイズ |
|
|
2 |
サンプル領域 |
|
|
3 |
コンテキスト領域 |
|
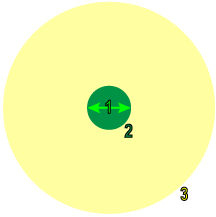

サンプルが画像自体のエッジにある場合、ツールではコンテキストとして使用する合成ピクセルを生成します。この生成に使用される具体的な方法は、マスク、境界、サンプルカラーチャネルなど (それぞれ [境界線タイプ] および [カラー]) を使用して制御できます。
ツールでは、サンプリング中に使用するマスクを指定することもできます。これによって、画像の一部を明示的に学習から除外することができます。ただし、[マスキングモード] パラメータの設定によっては、マスクされた領域もコンテキストとして考慮されます
最後に、カラー画像 (または複数の面またはチャネルを含んでいる画像) を使用している場合は、どのチャネルをサンプリングするかを明示的に指定できます。複数のチャネルを使用すると、学習または処理時間に若干の影響が及びますが、色が画像内の重要な情報を提供するような場合にツールの精度が向上します。
サンプリングパラメータの詳細:特徴のサンプリングと特徴のサイズ
フォーカスモードの分類 (緑)、フォーカスモードの解析 (赤)、位置決め (青)、および読み取り (青) の各ツールは、指定する特徴のサイズに基づいて画像を解析します。ピクセル単位で表された特徴のサイズは、ツールにとって、入力画像における「重要な」特徴または「特殊な」特徴の予想されるサイズに関するヒントとなります。特徴のサイズを選択する最良の方法は、人間の検査員のように入力画像を検査する方法です。特徴とは、画像を「良好」または「不良」に定義したり、欠陥や問題を識別したり、何かがどこにあったのか、それは何だったのかを特定したりするために使用する画像の特徴です。
たとえば、エンジンの数に基づいて飛行機の写真を分類しようとする場合、特徴のサイズは、飛行機のエンジンの大まかなサイズになります。
学習およびランタイムの両方で、ツールは、画像のサブ領域内のピクセルやその領域の周囲のコンテキスト情報を使用して、画像からサンプルを収集します。このコンテキスト領域は、特徴のサイズの約 5 倍です。
|
|
|
|
1 |
特徴のサイズ |
|
2 |
サンプリング領域 |
|
3 |
コンテキスト領域 |
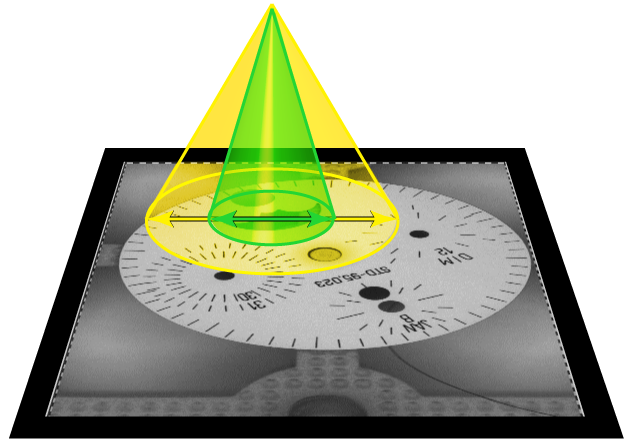
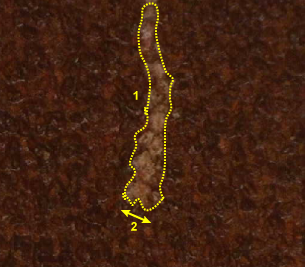
次のいくつかのガイドラインに従う必要がありますが、特徴のサイズの指定は主観的な判断です。解析 (赤) ツールの場合、アンスーパーバイズドモードまたはスーパーバイズドモードのいずれの場合も、特徴のサイズは典型的な欠陥の大まかなサイズになります。縞、染み、スクラッチ、裂け目などの伸長した欠陥の場合、特徴のサイズは欠陥の大まかな幅になります。
|
|
|
|
1 |
欠陥 |
|
2 |
特徴のサイズ |
学習パラメータ
学習処理を制御する学習機能ツールのパラメータ。ツールの学習が終了した後に学習機能ツールのパラメータを変更すると、学習が無効になり、ツールの再学習が必要になります。
| パラメータ | 説明 |
|---|---|
|
学習セット |
[学習セット] ダイアログを表示します。このダイアログは、新しい学習が行われるたびにニューラルネットワーク用の学習サンプルとしてランダムで選択するサンプルセットおよびラベル付けされた画像のパーセンテージを指定するために使用します。 |
|
エポック数 |
学習中に行われる最適化の反復数を指定します。アプリケーションがあまり複雑でないか、異なるパラメータ設定をテストする際に品質の低いモデルが役に立つような場合は、この設定を低くすることができます。 エポックとは、学習セット全体をニューラルネットワークに渡すための用語です。 ツールは通常、約 50 倍の学習画像セットデータが必要になります (微調整領域内)。これはデフォルトの設定であり、ほとんどの標準アプリケーションでは通常はこれで十分です。 使用するエポック数を減らすと、ニューラルネットワークの学習が不十分になったり、問題を正確に解決できなくなる場合があります。一方、エポックが多すぎると、結果のオーバーフィッティング (過剰学習) が生じる場合があります (学習された画像のみが取り込まれ、学習された画像以外のものは無効と見なされます)。ネットワークは、それが学習画像セットの汎化されたものとなる時点まで学習させることが重要です。エポックを増加しすぎると、学習画像セットデータの過剰学習とオーバーフィッティングが生じる恐れがあります。 Tip:
|
|
低適合率 |
ツールが学習後に低適合率モデルを作成するかどうかを指定します。低適合率モデルは、ランタイム操作中に速度の最適化が優先されるアプリケーションに役立ちます。2 つの操作モード間では結果が異なる可能性があります。 有効にした場合は、白い稲妻アイコンがツールのアイコンに追加されます。
Note:
|

学習パラメータの詳細:エポック数
[エポック数] パラメータを使用すると、実施するネットワーク調整の度合いを制御することができます。「ニューラルネットワークの学習」のトピックで説明したように、学習プロセスでは、ネットワークを通して入力サンプルを繰り返し処理して、ネットワークの結果をユーザが提供するラベル付けと比較し、エラーを減らす目的でネットワークの重みを調整します。ネットワークノード (重み) が多数存在するため、このプロセスはほとんど無限に繰り返すことができ、繰り返す内に、わずかながら徐々にエラーを改善することができます。[エポック数] パラメータ設定を上げると、実施される学習の繰り返し回数が増えます。これによって、学習に要する時間は長くなりますが、学習画像のネットワークエラーを減らすことができます。
ただし、ネットワークを学習させる目的は、学習に使用される画像だけでなく、すべての画像で正確に動作することなので注意してください。エポック数を上げると、ネットワークはオーバーフィット (用語) する傾向があり、未学習画像におけるエラーが増え、学習された画像におけるエラーは減ります。このために、エポック数を調整しながら、すべての画像におけるネットワークパフォーマンスを注意深くモニタする必要があります。最適値はデータセット、特にデータセットの統計的多様性によって異なるため、データセットに最適なエポック数を選択する必要があります。
摂動パラメータ
VisionPro Deep Learning ニューラルネットワークには、実際に見た画像内の特徴だけを学習させることができます。学習画像セットには、すべての標準的な画像およびパーツのばらつきを表す典型的な画像のセットが含まれていることが理想です。ただし、多くの場合は、典型的ではない画像セットを使用して学習を実行する必要があります。特に、画像セットは短期間で収集される場合が多いため、時間の経過による標準的なパーツや照明のばらつき、およびカメラの光学的特性や外的特性の変化や調整が反映されません。
VisionPro Deep Learning 学習システムでは、次のような摂動パラメータを使用して、操作中に予想される外観のばらつきの種類を指定することによって画像セットを補うことができます。
- 輝度
- コントラスト
- 回転
- スケール
The Perturbation parameters allow the VisionPro Deep Learning tools to artificially generate images to be trained on, improving results for applications with high amounts of variance.これらのパラメータは、すべてのツール間で共通しています。摂動パラメータは、組み合わせることもできます。パラメータを個別に使用したり、組み合わせて使用することで、さらに複雑な画像を生成できるようになります。
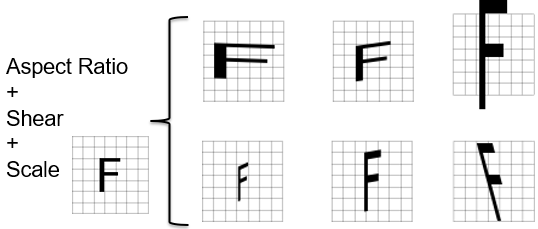
摂動の種類ごとに、摂動の範囲を指定できます。
| パラメータ | 説明 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
|
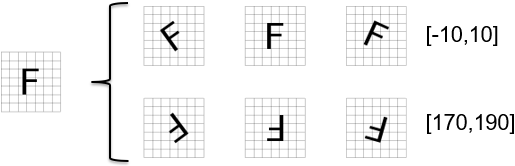
回転
|
摂動回転角度が引き出される区分的な均一分布を定義する、可能な回転を指定します ([0°,0°] に設定すると、回転摂動は使用されません)。 たとえば、[-10°, 10°] または [170°, 190°] の設定では、パーツは -10 ~ 10 度または 170 ~ 190 度の範囲で検出できます。これらのタイプの設定は、パーツに標準の回転、または角度のバリエーションが少ない、上下を逆にした回転を適用できる場合に特に役立ちます。ですが、これらの中間の回転には役に立ちません。
|
||||||||
|
スケール
|
摂動スケール係数が引き出される、1 前後の正規分布を指定します (0% に設定すると、使用されません)。 たとえば、100% の [スケール] 設定は、元のサイズの半分の画像を 2 倍にします (元の 0.5 倍から 2.0 倍)。
|
||||||||
|
アスペクト比
|
摂動アスペクト比係数が引き出される、1 前後の正規分布を指定します (0% に設定すると、使用されません)。 |
||||||||
|
せん断歪
|
摂動せん断歪係数が引き出される、1 前後の正規分布を指定します (0% に設定すると、使用されません)。 |
||||||||
|
反転
|
サンプリング中に、画像を垂直方向または水平方向、あるいはその両方の方向にランダムに反転するかを指定します。これは、オブジェクトまたは表面が対応する対称性を示す場合に役立ちます。 この設定は、学習データの量を大幅に増加する上で役立ちます。
|
||||||||
|
輝度
|
摂動輝度係数が引き出される、1 前後の正規分布を指定します (0% に設定すると、使用されません)。. |
||||||||
|
コントラスト
|
摂動コントラスト係数が引き出される、1 前後の正規分布を指定します (0% に設定すると、使用されません)。 |
||||||||
|
コントラストの反転
|
学習サンプルでコントラストの反転をシミュレートするために、コントラストをランダムに反転するかどうかを指定します。 Note: [コントラストの反転] パラメータは、[エキスパートモード] が有効になっている場合にのみ利用できます。
|













最後のパラメータの回復:パラメータの復元
[パラメータの復元] ボタンは、ツールのパラメータ値を最後の学習タスクで選択した値に簡単に戻すための機能です。最後の学習セッションで使用されたツールパラメータのすべての値が記憶されています。したがって、その値のいずれかを変更し、その変更を元に戻したい場合は、このボタンをクリックして、最後の学習で使用されたツールパラメータ値にロールバックすることができます。ツールを学習させていない場合、またはツールパラメータ値の初期セットから変更していない場合は、このボタンは無効になっています。
次の手順では、パラメータの復元がどのように機能するかを説明します。
-
現在のツールを学習させていない場合、[パラメータの復元] ボタンは常に無効です。
-
現在のツールを学習させると、パラメータロールバックのチェックポイントが最後の学習セッションのツールパラメータの値に設定されます。この時点で、ツールパラメータの値を変更した場合、ボタンが有効になります。
-
[パラメータの復元] ボタンをクリックすると、変更した値がチェックポイントの値に戻ります。
-
ツールパラメータをいくつか変更して現在のツールに再び学習させた場合、パラメータロールバックのチェックポイントは変更後のパラメータ値に更新されます。この場合も、ツールパラメータの値をさらに変更しない限り、ボタンは無効です。
-
さらに変更して [パラメータの復元] ボタンをもう一度クリックすると、変更した値が更新後のチェックポイントの値に戻ります。
処理パラメータの値を変更した後に学習済みツールを再処理する場合、パラメータロールバックのチェックポイントは更新されないため、[パラメータの復元] は有効なままになります。チェックポイントは、ツールの学習が完了した後にのみ更新されます。
|
無効 |
有効 |
これらのパラメータを変更するとツールがリセットされる不可逆的なパラメータ
[ネットワークモデル]、[排他的]、[特徴のサイズ]、[マスキングモード]、[カラー]、[中心]、[スケール調整済み]、スケール調整済みのモード ([均一]/[不均一])、[レガシーモード]、[回転済み]、[詳細]
本質的に可逆的ではない不可逆的なパラメータ
[低適合率]、[単純領域]
その他の不可逆的なパラメータ
分類 (緑) High Detail および 分類 (緑) High Detail Quick の [学習セット]、[ヒートマップ] (このパラメータは予測パフォーマンスに影響しません)
読み取り (青) のマスキングモードの [オーバーレイ] パラメータ
ニュートラルネットワークの学習の制御
解析 (赤) フォーカススーパーバイズド の学習は、ツールのパラメータと学習セットを設定することで制御できます。
学習セット
ネットワークの学習フェーズに影響を与える最大で唯一の決定要素は、学習セットの構成です。ネットワークの学習フェーズを制御するための最善の方法は、ツールに適切な学習セットを構築することです。この方法で、ツールが画像/ビューを正しく汎化しているかどうかをユーザが判断できるカテゴリに分類します。