API
The VisionPro Deep Learning supports exactly the same functionality through API. It supports API via the following programing languages:
-
C (C++)
-
C# (.NET)
API Overview
For those who want to leverage API, it is highly recommended to go through all the details of the VisionPro Deep Learning GUI introduced in this documentation first, because the GUI and API shares all the fundamental concepts and walkthroughs for the utilization of the VisionPro Deep Learning tools. For the details of each programming language's API , please refer to API documentations in the path below
-
C
-
API Documentation:
C:\Program Files\Cognex\VisionPro Deep Learning\3.2\Develop\docs -
Example Codes:
C:\ProgramData\Cognex\VisionPro Deep Learning\3.2\Examples\c++
-
-
C#
-
API Documentation:
C:\Program Files\Cognex\VisionPro Deep Learning\3.2\Develop\docs
-
Example Codes:
C:\ProgramData\Cognex\VisionPro Deep Learning\3.2\Examples\c++
-
Target Frameworks
- Non-UI NuGet packages now target NET Standard 2.0
- UI assemblies and executables now target .NET Framework 4.7.2
- Non-UI executables now target .NET Core 3.1
NuGet Packages
NuGet packages are project-based, and have dependencies. VisionPro Deep Learning .NET library is compiled targeting a cross-platform framework, wherever possible. All of the UI-related assemblies are compiled targeting either .NET Framework 4.7.2 or NET Standard 2.0. Since VisionPro Deep Learning inherits ViDi, it retains the name ViDi in many parts of the APIs
| Assembly | Framework Target |
|---|---|
|
ViDi.NET.Local |
NET Standard 2.0 |
|
ViDi.NET.Logging |
NET Standard 2.0 |
|
ViDi.NET.Remote |
NET Standard 2.0 |
|
ViDi.NET.Remote.Service |
NET Standard 2.0 |
|
ViDi.NET.Remote.Client |
NET Standard 2.0 |
|
ViDi.NET |
NET Standard 2.0 |
|
ViDi.NET.Base |
NET Standard 2.0 |
|
ViDi.NET.Common |
NET Standard 2.0 |
|
ViDi.NET.Extensions |
NET Standard 2.0 |
|
ViDi.NET.Interfaces |
NET Standard 2.0 |
| ViDi.NET.UI.Interfaces |
.NET Framework 4.7.2 |
|
ViDi.NET.GUI |
.NET Framework 4.7.2 |
| ViDi.NET.UI |
.NET Framework 4.7.2 |
|
ViDi.NET.VisionPro |
.NET Framework 4.7.2 |
NuGet packages were introduced to simplify which assemblies are required to use a certain Cognex Deep Learning Studio functionality.
For example, the ViDi.NET.UI now shows exactly which assemblies are required, along with the requisite licenses for 3rd party assemblies.
VisionPro Deep Learning NuGet packages are located in the following directory:
-
C:\ProgramData\Cognex\VisionPro Deep Learning\X.X\Examples\packages
The NuGet feed is automatically set in the examples, but must be set to a global Visual Studio NuGet package feed. Cognex highly recommends backing up the NuGet packages to another secure repository (or its equivalent) and to keep a copy. This location should then be configured as a new NuGet feed. For more information, see the following Microsoft topic: Hosting your own NuGet feeds
Runtime API Processing Guide
Focused modes support parallel processing as their processings are done on an image basis. You can leverage this power of parallel processing when you organize your code workflow for processing Focused tools in a runtime workspace with API. It is highly recommended to see NVIDIA GPU Selection and Configuration before reading this page for more details about parallel processing of tools.
When you execute processing tasks with VisionPro Deep Learning API in a runtime environment, you are going to handle objects like Threads, GPUs, Samples, etc. for organizing API code workflow.
| Objects | Description/Note |
| Workspace | Thread-Safe |
| Stream | Thread-Safe |
| Tool | Thread-Safe |
| Sample |
A container object that handles an image Not Thread-Safe |
| Image |
An object that has the actual image data to be processed Not Thread-Safe |
| Buffer |
An object that receives the result Not Thread-Safe |
| Thread |
When multiple GPU devices are initialized, you have 2 options for invoking processing by calling API.
Providing "Empty List" as a Device List Argument
if you use an empty list for the "device list" argument when calling API, the processing is executed on any available (unoccupied, released) GPU. This means that you are not choosing the specific GPUs to process specific tools. This strategy is recommended when you:
-
simply require parallel processing itself without any other purpose:
-
simply want to test whether your parallel processing code is working or not.
-
want your code implementation to be executed always and only in a parallel way in whatever situation you belong to.
-
process 2 tools whose expected time for processing are similar to each other, which means that they are good to go for parallel processing without designating specific GPUs
-
process 1 tool in parallel, which means that you want to exploit multiple GPUs to boost processing by parallel processing.
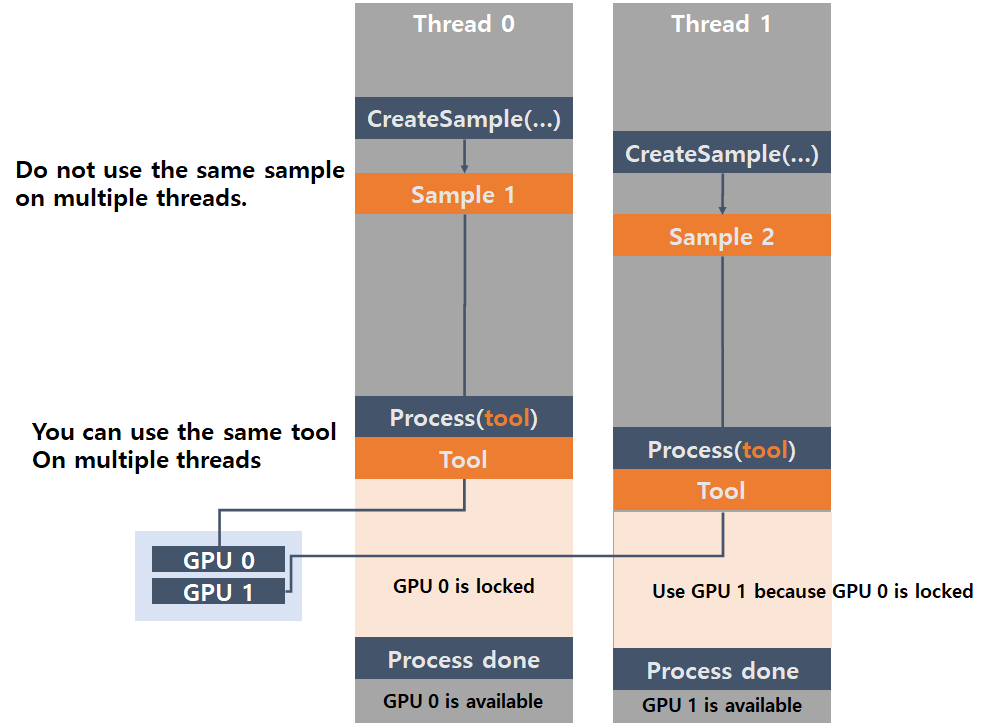
For explanation, it is good to take a view on a simple case that you need to process 1 Focused mode tool with 2 Threads and 2 GPUs.
If you provide an empty list as the device list argument and execute processing this tool in both 2 Threads (Thread 0 and Thread 1), one of the Threads, say Thread 0, occupies GPU 0 only for a while to process an image.
When GPU 0 is occupied by Thread 0, GPU 0 is locked so Thread 1 access GPU 1 and occupy it for processing another image from this tool.
After Thread 0 finishes the processing of an image with GPU 0, it releases GPU 0 and GPU 0 can be occupied by Thread 1 if the processing job of Thread 1 was waiting in the waiting list (Queue). In this way, this single tool can be processed in parallel with 2 GPUs and 2 Threads.
Providing "Non-Empty List" as a Device List Argument
if you use a non-empty list for the "device list" argument when calling API, the processing is executed on the available (unoccupied, released) GPUs that are in the provided "device list". This means that you are choosing a list of one or more GPUs to process specific tools. This strategy is recommended when you:
-
process 2 tools whose expected time for processing are deviating a lot from each other, which means that one of them could be the bottleneck against one another in parallel processing if this tool did not have designated GPU(s) that is(are) solely allocated to this tool.
-
want to control which GPU(s) should be used for processing specific tools and which should not.
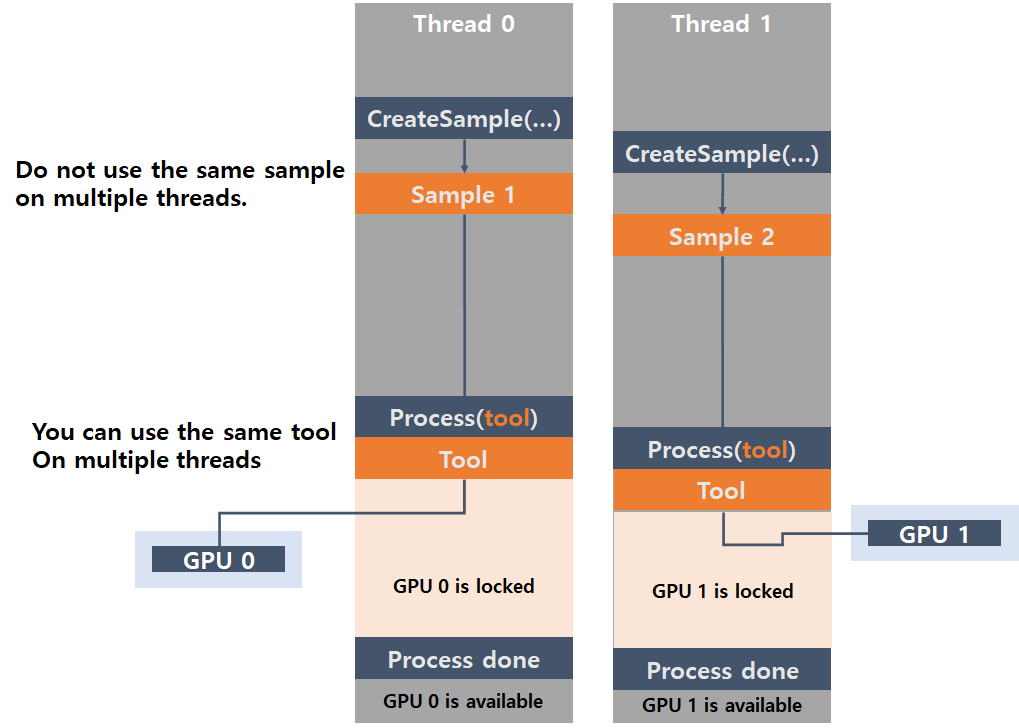
For explanation, it is good to take a view on a simple case that you need to process 1 Focused mode tool with 2 Threads and 2 GPUs.
If you provide a list that contains GPU 0 for Thread 0 and a list that contains GPU 1 for Thread 1, each, as the device list argument and execute processing this tool in both 2 Threads (Thread 0 and Thread 1), GPU 0 is solely allocated to Thread 0 and GPU 1 is to Thread 1.
Thread 0 uses only GPU 0 until it finishes its processing jobs for a given set of images, and it is same to Thread 1 and GPU 1.
For another case, this time you have to process 2 Focused mode tools (A, B) with 2 Threads (Thread 0 for tool A, Thread 1 for tool B) and 3 GPUs (GPU 0, GPU 1, GPU 2). Tool B takes much more time for processing, since the number of its images to be processed is significantly larger than those of tool A or the resolution of the image data of tool B is much higher than that of tool A.
Even with this circumstance, you are good to go for parallel processing provided with an empty device list. The total processing time (the time required to finish processing of both A and B) would remain the same compared to when a non-empty device list is provided.
But the problem of this case is that the processing of tool B could slow down the processing of tool A, since for the most part 3 GPUs are going to be occupied by Thread 1 because of tool B's high workload and since the processing of Focused tool is done on image.
Therefore, if you want this parallel processing of tool A and B without significantly slowing down the processing of tool A, you can provide a device list, [GPU 1] or [GPU 1, GPU 2], for Thread 1 to make sure these GPUs are dedicated to the processing of tool B. You can either also provide a device list or an empty list for Thread 0. This will prevent tool B from being the bottleneck against tool A in parallel processing.
Multiple GPUs Utilization with API
Initialization Through the C API
Initialization via the C API is performed using the VIDI_UNIT vidi_initialize(VIDI_INT gpu_mode, VIDI_STRING gpu_devices) argument.
| GPU Mode gpu_mode | No GPU Support | Single Device per Tool |
|---|---|---|
|
Int value |
-1 |
0 |
|
C Define |
VIDI_GPU_MODE_NO_SUPPORT |
VIDI_GPU_MODE_SINGLE_DEVICE_PER_TOOL |
When processing with the following:
- vidi_runtime_process
- vidi_runtime_process_single_tool
- vidi_runtime_process_sample
- vidi_training_stream_process_sample
- vidi_training_tool_process_database
- vidi_training_process_sample
The GPU device selection is performed using the VIDI_STRING gpu_list argument.
| GPU Device gpu_list | Default Value | Device List |
|---|---|---|
|
String value |
" " |
"0,1,2" |
|
C Define |
VIDI_AUTO_SELECT_GPU_DEVICE |
|
|
Description |
Uses all of the available GPUs. |
Only uses the specified GPUs (for example 0, 1 and 2). |
Initialization Through the .NET API
When creating a new control using one of the following:
- ViDi2.Runtime.Local.Control (ViDi2.GpuMode gpuMode, List<int> gpuDevice)
- ViDi2.Runtime.Local.Control (LibraryAccess libraryAccess, ViDi2.GpuMode gpuMode, List<int> gpuDevices, bool activateDebugLogging)
- ViDi2.Training.Local.Control (ViDi2.GpuMode gpuMode, List<int> gpuDevice)
- ViDi2.Training.Local.Control (LibraryAccess libraryAccess, ViDi2.GpuMode gpuMode, List<int> gpuDevices, bool activateDebugLogging)
| GPU Mode | ViDi2.GpuMode gpuMode |
|---|---|
|
Single Device per Tool (default) |
GpuMode.SingleDevicePerTool |
|
No GPU Support |
Gpu.Mode.NoSupport |
When processing with the following:
- ViDi2.Runtime.ITool.Process
- ViDi.Runtime.IStream.Process
- ViDi2.Training.ITool.Process
- ViDi.Training.IStream.Process
- ViDi2.IDatabase.Process
The device selection is performed through the List<int> gpuDevices argument.
| List<int> gpuDevices | Default Value | Device List |
|---|---|---|
|
Value |
null |
new List<int> {0,1} |
|
Description |
Uses all of the available GPUs. |
Only uses the specified GPUs (for example 0 and 1). |