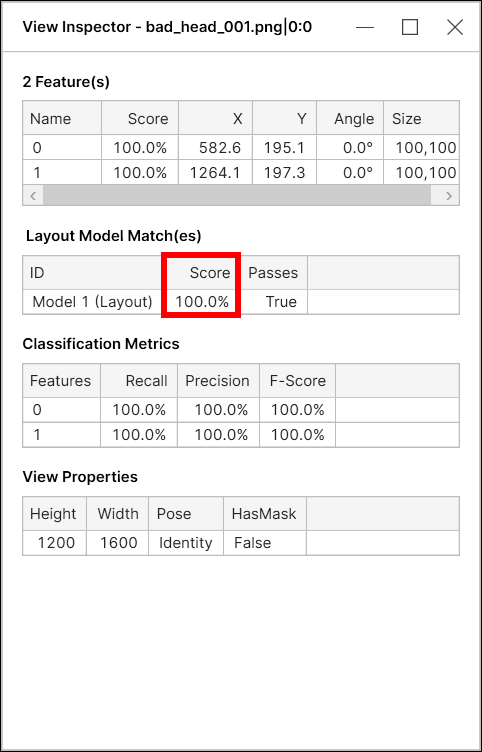
結果の解釈
学習と処理が完了すると、ツールの結果がすべてのビューに対して計算されます。ただし、ツールを正しく評価するには、テストセットでのみ結果を確認する必要があります。
テストセット:結果評価のための画像
VisionPro Deep Learning 内の統計的な測定は、学習したニューラルネットワークのパフォーマンスを評価するために使用されます。ディープラーニングのパラダイム内で評価とは、学習したニューラルネットワークモデルをテストデータ (ユーザによってラベル付けされているが、まだ学習に使用されていないデータ) に対して評価するプロセスのことです。そのため、統計測定を通じてニューラルネットワークモデルの可用性とパフォーマンスを決定する場合、これらの測定はテストデータのみに基づいて計算する必要があります。
ニューラルネットワークモデル、つまりツール (位置決め (青)/読み取り (青)、分類 (緑)、または解析 (赤)) の学習後、モデルが適切に学習しているかどうかを確認したい場合、このモデルの学習に使用したデータに対してモデルをテストすることはできないことを理解しておくことが重要です。学習済みのモデルの評価に学習データを使用することはできません。これは、そのモデルは指定された学習データセットで最大限のパフォーマンスが得られるように学習中にこのデータに既に適合しているためです。そのためこのデータから、モデルがどの程度十分に一般化されているかや、未知の新しいデータに対して望ましいパフォーマンスを発揮するかどうかを知ることはできません。
したがって、モデルの可用性とパフォーマンスを公正かつ正確にテストするには、学習フェーズを含め、未知のデータにモデルを適用する必要があります。モデル評価用のデータがテストデータセットと呼ばれるのはこのためです。
データベースの概要
[データベースの概要] ペインは、学習に使用された画像やビューに関する情報や、Cognex Deep Learning ツールによって出力された統計へのアクセスを提供します。選択されたツールに応じて、このペインの表示は異なります。
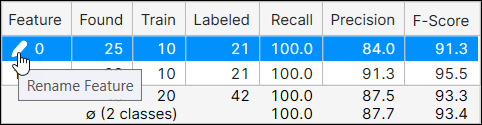
特徴の名前を変更するには、名前をクリックし、鉛筆アイコンを押して [特徴の名前変更] ダイアログを起動します。
エキスパートモードでは、[フィルタ] フィールドを使用して画像/ビューを分割したり、これらの画像/ビューで統計分析を実行したりすることができます。画像/ビューをフィルタ処理するためのシンタックスの詳細については、「表示フィルタ」および「フィルタ」を参照してください。フィルタの使用可能性の詳細については、「テスト画像サンプルセット」のトピックを参照してください。
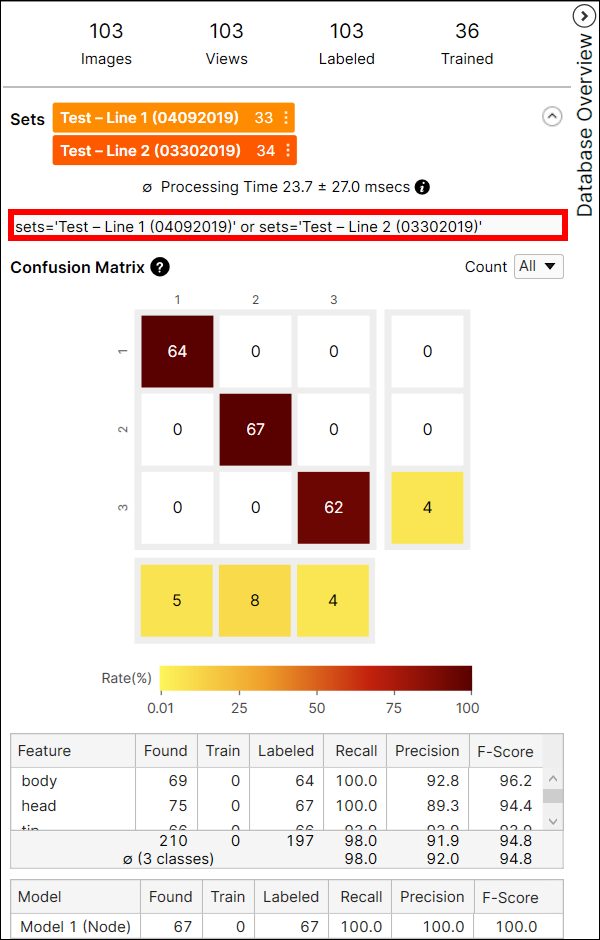
処理時間
以下に示すように、各ツールの処理時間はデータベースの概要に表示されます。
処理時間は、最後の処理タスクの画像あたりの平均処理時間であり、処理時間と後処理時間の合計です。複数のツールが含まれるストリームの処理時間は、VisionPro Deep Learning GUI を通じて使用することはできません。処理時間には、ツール間のビュー情報の準備および転送に必要な時間が含まれるため、ストリームで各ツールのツール実行時を合計することで予測することはできません。
コンフュージョンマトリックス
コンフュージョンマトリックスは、教師データとツールの予測を視覚的に表したものです。ツールのコンフュージョンマトリックスは、再現率と適合率の得点をグラフで表したものです。コンフュージョンマトリックスの各行は、ユーザがラベル付けした特徴数 (教師データ) を表し、コンフュージョンマトリックスの各列は、ツールが予測した特徴数 (マーキング) を表します。[データベースの概要] のコンフュージョンマトリックスで各セルをクリックすると、テーブルの各セルの対応する項目 (ビュー) がビューブラウザに表示されます。
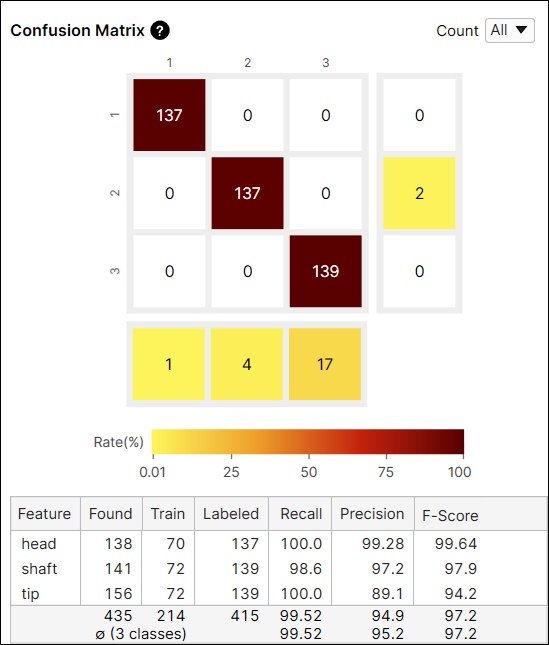
コンフュージョンマトリックスのセルの色は、予測される特徴の数 (セルの値) とラベル付けされた特徴の総数 (行の合計) の比率を表します。色が暗いほど比率が高く、明るいほど比率が低くなります。
たとえば、ラベルが「shaft」である特徴のうち、「shaft」と予測される特徴の数が 127 であり、ラベルが「shaft」である特徴の 90.7% (127/140) を占めているため、インデックス (2,2) のセルの色は茶色となります。
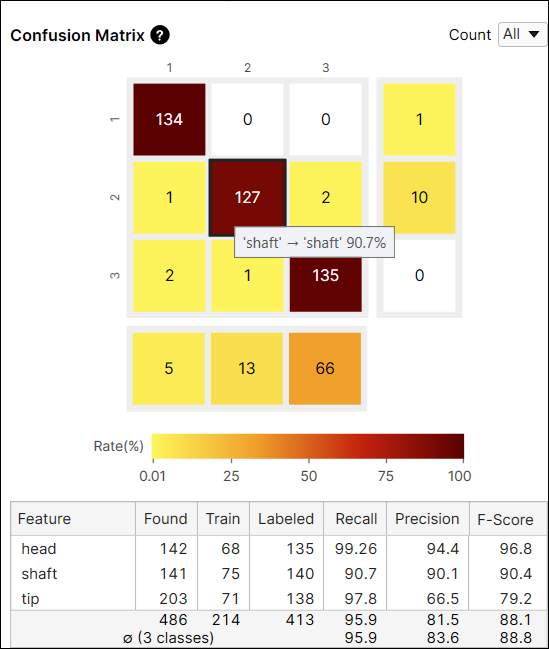
たとえば、ラベルが「shaft」である特徴のうち、「tip」と予測される特徴の数が 2 であるため、インデックス (2,3) のセルの色は黄色となります。「tip」と予測される特徴の数は、ラベルが「tip」である特徴の 1.4% (2/140) を占めています。
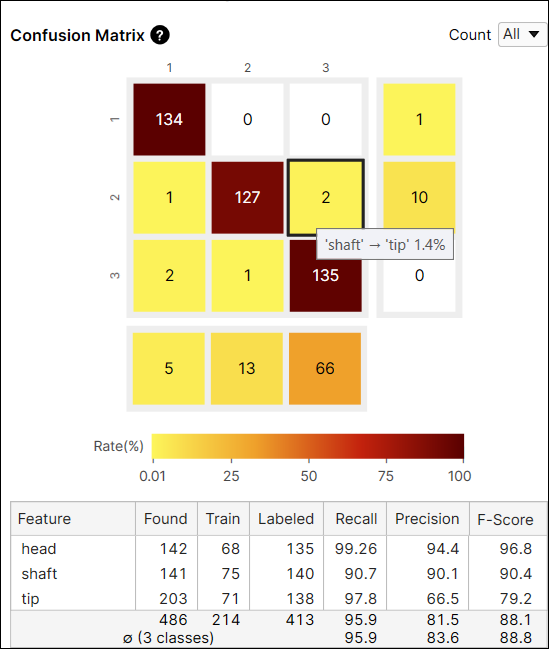
望ましい結果を表すため、通常は暗い色のセルをコンフュージョンマトリックスの対角インデックスに配置することをお勧めします。
|
|
|
|
パフォーマンス良好 |
パフォーマンス不良 |
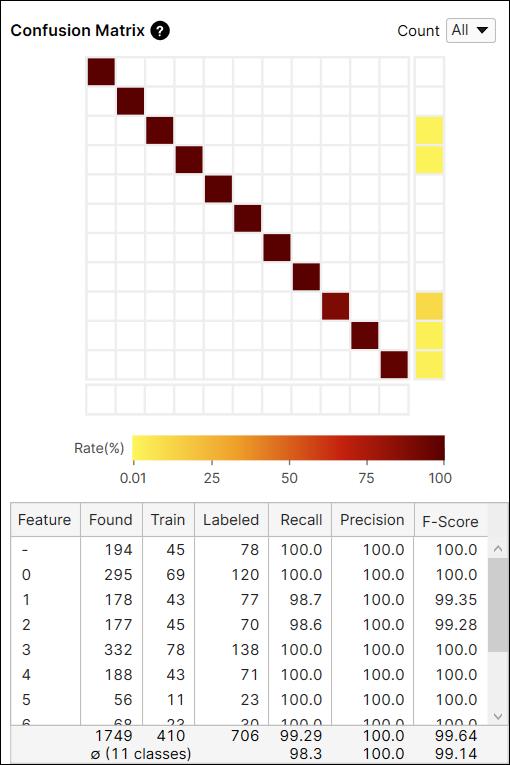
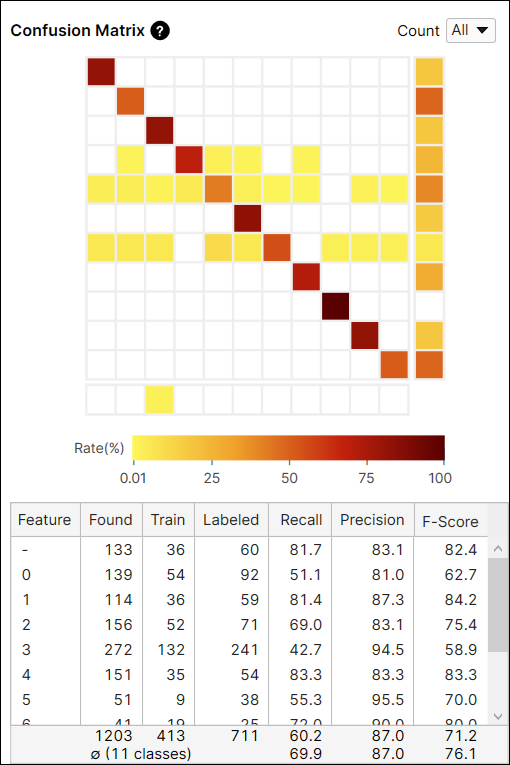
コンフュージョンマトリックスの計算:すべてのビューと未学習ビュー
コンフュージョンマトリックスの [カウント] オプションは、すべてのビュー (すべて)、または学習セットに含まれていないビュー (未学習ビュー) のみから計算された現在のツールの結果を提供します。学習画像とテスト画像を含むすべてのビューから生成された結果と、テスト画像である未学習ビューのみから生成された結果を切り替えることができます。
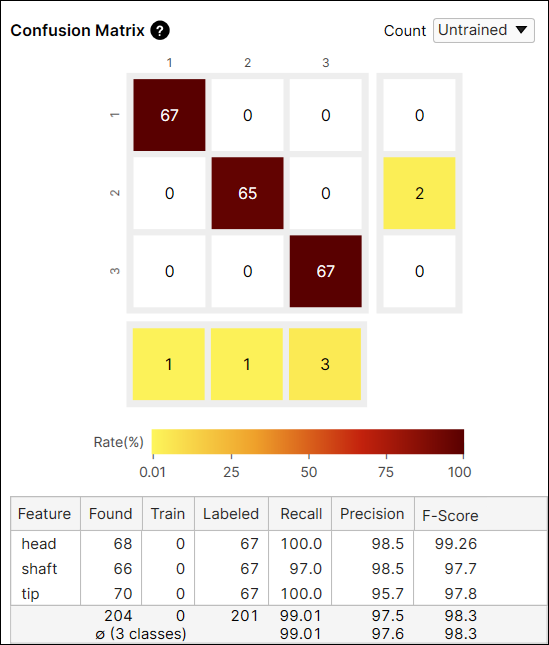
測定結果
位置決め (青) の [データベースの概要] には 2 つの表があり、それぞれ異なる結果を示します。上の表は画像の各特徴の測定結果を示し、下の表は画像の各モデルの測定結果を示します。ここで、モデルはノードモデルとレイアウトモデルのいずれかを表し、位置決め (青) のニューラルネットワークモデルではありません。
「ラベル付きモデル」は、ビュー上でユーザが作成した (ラベル付けした) モデルです。処理ステップで、位置決め (青) はラベル付きモデルを使用して、このモデルがビュー上で見つかったかどうかを判断します。つまり、「見つかったモデル」とは、学習済みの位置決め (青) によってビュー上で見つかったモデルです。
ほぼ同じ位置にラベル付きモデルがあり、対応するラベル付きの特徴に近い位置に、見つかったモデルにも特徴がある場合、見つかったモデルは正しい一致 (正しくマークされたモデル) であると言えます。モデルの適合率、再現率、F 値は、この根拠に基づいて計算され、1 つのビューに複数のモデルがある場合は、すべてのモデルの指標がモデルごとに個別に計算されます。
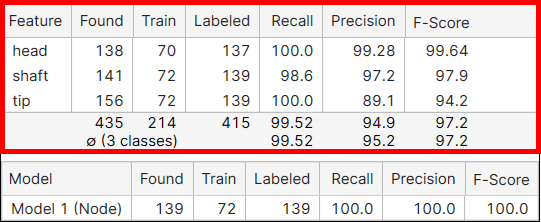
特徴の指標
| 表 | 指標 | 説明 |
|---|---|---|
|
特徴 |
特徴の名前。 |
|
検出 |
すべてのビューで処理した結果、この特徴クラスの特徴オブジェクトがいくつ見つかったかを示します。 | |
|
学習 |
この特徴クラスの特徴オブジェクトが学習セットにいくつ含まれているか (ラベル付けされているか) を示します。 | |
| ラベル付き | この特徴クラスの特徴オブジェクトがすべてのビューにいくつ含まれているか (ラベル付けされているか) を示します。 | |
|
再現率 |
ツールがラベル付けされた特徴オブジェクトを見つける可能性を示します。再現率は、目的とする特徴が実際に存在する場合に、ニューラルネットワークがそれを見つける能力を表します。これは、正しくマークされた特徴をラベル付けされた特徴で割ったものとして示されます。高い再現率得点は、すべてのラベル付き特徴が見つかったことを意味するのが理想です。ただし、再現率では誤って検出された特徴が考慮されないため、高い再現率でもタイプ I エラーである場合があります。詳細については、「基本概念:偽陽性、偽陰性」を参照してください。 | |
|
適合率 |
ラベル付けされている特徴をツールが見つける正確さを示します。適合率は、ニューラルネットワークが特徴を正しく配置できる能力を表します。これは、見つかった特徴の合計数のうち、正しくマークされた特徴の数として示されます。高い適合率は、見つかったすべての特徴が画像内に存在することを意味するのが理想です。ただし、高い適合率は、存在するが見つからなかったすべての特徴を考慮するわけではないため、検出されなかった特徴が数多く存在する、タイプ II エラーである場合もあります。詳細については、「基本概念:偽陽性、偽陰性」を参照してください。 | |
|
F 値 |
適合率と再現率の調和平均。 |
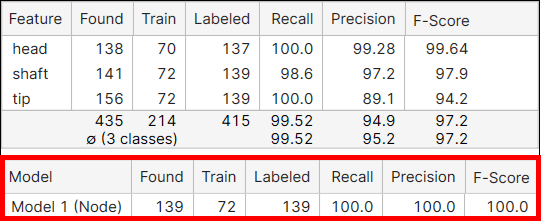
モデルの指標
| 表 | 指標 | 説明 |
|---|---|---|
|
モデル |
モデルの名前。 |
|
検出 |
すべてのビューで処理した結果、モデルがいくつ見つかったかを示します。 | |
|
学習 |
学習セットにラベル付きモデルがいくつ含まれているかを示します。 | |
|
ラベル付き |
すべてのビューにラベル付きモデルがいくつ含まれているかを示します。 | |
|
再現率 |
ツールがラベル付きモデルを見つける可能性を示します。再現率は、目的とするモデルが実際に存在する場合に、ニューラルネットワークがそれを見つける能力を表します。これは、正しくマークされたモデルをラベル付きモデルの数で割ったものとして示されます。高い再現率得点は、すべてのラベル付きモデルが見つかったことを意味するのが理想です。ただし、再現率では誤って検出された特徴が考慮されないため、高い再現率でもタイプ I エラーである場合があります。詳細については、「基本概念:偽陽性、偽陰性」を参照してください。 |
|
|
適合率 |
ラベル付けされているモデルをツールが見つける正確さを示します。適合率は、ニューラルネットワークがモデルを正しく配置できる能力を表します。これは、見つかったモデルの合計数のうち、正しくマークされたモデルの数として示されます。高い適合率は、見つかったすべてのモデルが画像内に存在することを意味するのが理想です。ただし、高い適合率は存在するが見つからなかった多くのモデルを考慮しないため、検出されなかったモデルが数多く存在する、タイプ II エラーである場合もあります。詳細については、「基本概念:偽陽性、偽陰性」を参照してください。 | |
|
F 値 |
適合率と再現率の調和平均。 |
基本概念:偽陽性、偽陰性
統計結果のコンポーネントに加えて、偽陽性および偽陰性の結果に対するそれらの影響を理解することも重要です。
画像の欠陥を取り込むために構築された画像検査システムがあるとします。ある画像で 1 つ以上の欠陥が取り込まれた場合、その画像の検査結果は「陽性」となり、欠陥がまったく取り込まれない場合、その画像の検査結果は「陰性」となるとします。検査タスクの統計結果は、以下のように要約できます。
-
偽陽性 (タイプ I エラーとも呼ばれる)
-
検査システムは特徴のクラスを識別しますが、この特徴は実際にはそのクラスに属していません。
-
-
偽陰性 (タイプ II エラーとも呼ばれる)
-
この特徴は特徴のクラスに属するものとして識別されるべきですが、検査システムは特徴のクラスを識別できませんでした。
-
基本概念:適合率、再現率、F 値
次に偽陽性と偽陰性についてまとめ、指標として適合率と再現率を使用して再度示します。これらの指標はすべての VisionPro Deep Learning ツールで使用される統計結果です。
- 適合率
- 適合率の低いニューラルネットワークは通常、提供された画像データ (テストデータ) から検出されるべき特徴を正しく検出できず、多くの偽陽性の判定 (タイプ 1 エラー) を返します。
- 適合率の高いニューラルネットワークは通常、提供された画像データ (テストデータ) から特徴を正しく検出することに成功しますが、再現率が低い場合、多くの偽陰性の判定 (タイプ 2 エラー) が発生する可能性があります。
- 再現率
- 再現率の低いニューラルネットワークは通常、提供された画像データ (テストデータ) から検出されるべき特徴を十分に検出できず、多くの偽陰性の判定 (タイプ 2 エラー) を返します。
- 再現率の高いニューラルネットワークは通常、提供された画像データ (テストデータ) から特徴を十分に検出することに成功しますが、適合率が低い場合、多くの偽陽性の判定 (タイプ 1 エラー) が発生する可能性があります。
まとめると、
- 適合率 - 検出された特徴がラベル付き特徴に一致する割合。
- 再現率 - 検出された特徴がツールによって正しく識別される割合。
- F 値 - 再現率と適合率の調和平均。
ほぼすべての検査 (例外的な検査もあり得る) で理想的な統計結果を得るには、適合率と再現率がどちらも高いことが求められます。
ノードモデルの得点
位置決め (青) ツールの場合、ノードモデルの得点 (モデル一致得点) は次の 2 つの得点の組み合わせです。
-
このモデルの特徴の平均得点
-
このモデルの特徴の幾何学的配置に基づく「形状得点」
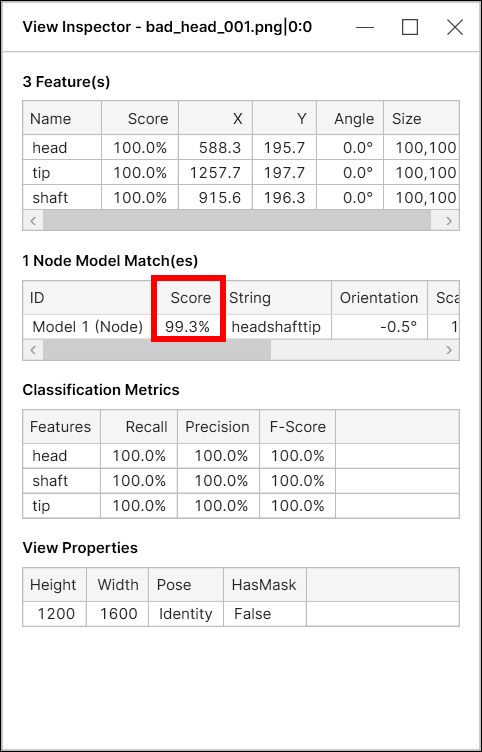
幾何学的配置はモデル全体の一致得点の計算に含まれるため、すべての特徴が 100% の満点であっても、形状得点が 100% 未満の場合、ノードモデルの得点は 100% 未満になる可能性があります。
「形状得点」とは、簡単に言えば、特徴の相対的な位置が、モデル内のノードの相対的な位置とどれだけ異なっているかを示す指標です。たとえば、3 つのノードを持つノードモデルの場合、各特徴の得点が 100% でも、特徴の空間的なレイアウトがモデルの空間的なレイアウトと完全に一致しない限り、形状得点は 100% 未満になるため、モデル全体の一致得点はわずかに 100% を下回ります。
レイアウトモデルの得点
位置決め (青) ツールの場合、レイアウトモデルの得点 (モデル一致得点) は、このモデルの特徴の平均得点です。