読み取り (青)
読み取り (青) について
読み取り (青) ツール  は、光学文字認識 (OCR) を実行するために使用されます。この事前学習済みのツールは、背景を含む多数のフォントのテキストの大規模な画像データベースで学習されています。事前学習済みのツールの文字は、数字 (0 ~ 9)、大文字 (A ~Z、"O" を除く)、ハイフン (-)、プラス記号 (+)、アンパサンド (&)、コロン (:)、スラッシュ (/) です。
は、光学文字認識 (OCR) を実行するために使用されます。この事前学習済みのツールは、背景を含む多数のフォントのテキストの大規模な画像データベースで学習されています。事前学習済みのツールの文字は、数字 (0 ~ 9)、大文字 (A ~Z、"O" を除く)、ハイフン (-)、プラス記号 (+)、アンパサンド (&)、コロン (:)、スラッシュ (/) です。
位置決め (青) ツールと同様に、読み取り (青) ツールは文字を画像内の特徴として認識し位置決めします。ただし、前述のように、読み取り (青) ツールは事前学習済みのツールであり、読み取りパフォーマンスの一般的なベースラインを提供するため、学習させる必要はありません。したがって、ツールを最初に設定すると、ほとんど瞬時に文字を認識して読み取ることができます。このツールは既に文字の読み取り方法をわかっているため、文字を検索する画像内の場所を定義するだけです。
読み取り (青) ツールの長所は、困難なプロジェクト、つまり低コントラスト、低解像度、変形文字のプロジェクトで作業できることです。また、必要なセグメンテーション設定や画像フィルタを設定することも難しくありません。このツールは、従来のマシンビジョンツールでは、特にノイズの多い背景での変形した文字や曲線の文字など、読み取りにくい文字を読み取ることができます。
このツールを使用するには、学習画像セットを指定した後、読み取る文字の周囲の領域を設定します。特徴のサイズパラメータを調整し、文字にラベル付けします。ほとんどの場合、このツールは自動的に文字を識別して正しく読み取り、その文字のマーキングを生成します。これを今後の学習用のラベルとして承認することができます。1 つ以上の文字のインスタンスにラベルを付けたら、ツールを学習させます。次に、学習フェーズで使用されなかった画像でツールを確認します。
読み取り (青) のニューラルネットワークアーキテクチャは フォーカス であるため、解析 (赤) フォーカススーパーバイズド や 分類 (緑) フォーカス ツールのように、フォーカス アーキテクチャのすべてのプロパティを備えています。
| 読み取り (青) | |
|---|---|
| 画像データセットの構成 | 学習セット、テストセット |
| 検証損失のモニタリング | X |
| 損失のインスペクタ | サポートされていません |
読み取り (青) のための学習ワークフロー
ツールが 読み取り (青) モードの場合、ツールの学習ワークフローは次のとおりです。
- VisionPro Deep Learning を起動します。
- 新しいワークスペースを作成するか、既存のワークスペースを VisionPro Deep Learning にインポートします。
- 文字を含む画像を収集し、VisionPro Deep Learning に読み込みます。
-
読み取り (青) ツールを追加します。
-
ROI と特徴サイズを設定する
-
読み取りツール内で、ROI と特徴サイズを設定します。
Note: 特徴サイズの設定の詳細については、「サンプリングパラメータの設定」を参照してください。 - [画像ディスプレイ] ウィンドウで、最初の画像をクリックします。
- 長方形の ROI が画像全体を囲みます。
- ROI が文字を囲むようにサイズを変更します。ROI には、右上隅と右下隅に 2 つのハンドルがあります。これらを使用すると、ROI をドラッグしてサイズを変更し、すべての画像内の文字とその可能な位置を覆うことができます。
- ROI を設定したら、[適用] ボタンを押します。
- これにより、ROI 設定がすべての画像に適用されます。
- ROI が適用されたら、最初の画像をもう一度クリックします。
-
ディスプレイの左下隅には、対話型の [特徴のサイズ] ボックスがあり、デフォルトの文字サイズが示されます。それをつかんで文字まで引き上げ、文字に合うようにサイズを変更することができます。
Tip: その文字だけを囲むくらいの大きさにしてください。1 つの文字で設定したら、他の文字の周りに移動して、サイズが正しいことを確認できます。 -
文字サイズを設定したら、[ブック] アイコンを押し、新しい文字サイズに基づいてすべての画像を処理します。これにより、新しい文字サイズがすべての画像に適用されます。
Note: ある画像で文字サイズが変更されると、その変更は他のすべての画像に自動的に適用されます。ただし、[スケール調整済み] パラメータオプションが有効な場合、特徴は公称特徴サイズの文字に合わせてアスペクト比を適合させ、公称特徴サイズの [1/4, 4] の間隔内に特徴を固定するだけです。そのためには、[ブック] アイコンを押して画像を再処理し、学習セット内の残りの画像で [特徴のサイズ] の変更結果を確認する必要があります。
-
-
文字にラベルを付ける
次の主なステップは、文字のラベル付けです。各文字の少なくとも 1 つのインスタンスにラベルを付ける必要があります。ラベル付けのプロセスは、学習する前に、ツールが文字を正しく解釈しているかどうかを判断するための便利なメカニズムです。
- [データベースの概要] ウィンドウを展開します。表には、ツールによって検出されたすべての文字がリストされています。
- 表を一文字ずつ調べて、見つかった各文字のインスタンスを選択します。
- 表で文字を選択してダブルクリックします。こうすると、表示ウィンドウがその文字のインスタンスのみを表示するように変更されます。
- 表示された文字から、文字の適切なインスタンスを選択します。
- メインディスプレイがその画像に切り替わります。画像を右クリックして、[ビューの受け入れ] を選択します。
- これにより、文字のそのインスタンスのラベルが作成されます。
- また、文字を選択して右クリックし、[特徴の削除] を選択すると、ツールが間違って文字をラベル付けしたインスタンスも削除されます。
Note: 文字の複数のインスタンスをラベル付けして受け入れることで、ツールは、学習時よりもさらに学習した結果を発揮します。ラベル付けの詳細については、「特徴ラベルの作成 (特徴のラベル付け)」を参照してください。 - [データベースの概要] ウィンドウを展開します。表には、ツールによって検出されたすべての文字がリストされています。
-
ツールを学習させる
読み取り (青) を使用して文字を識別する場合は、次のステップに従います。
-
各文字のラベル付きインスタンスが完了したら、ツールを学習させます。ツールを学習させるには、まず、目的の画像を学習セットに追加します。
-
ビューブラウザで画像を選択し、右クリックのポップアップメニューで [ビューを学習セットに追加する] をクリックします。
-
ビューブラウザで複数の画像を選択するには、Shift を押しながらマウスの左ボタンをクリックします。または、表示フィルタを使用して、学習対象の画像のみを表示し、[... ビューのアクション] → [ビューを学習セットに追加する] の順にクリックして、これらを学習セットに追加します。
-
-
学習の前に、[ツールのパラメータ] でパラメータを設定する必要があります。学習、サンプリング、および摂動パラメータを設定することも、これらのデフォルト値を使用することもできます。サポートされているパラメータの詳細については、「ツールのパラメータの設定」を参照してください。
-
サンプリングパラメータの [特徴のサイズ] パラメータが設定されていることを確認します。[特徴のサイズ] パラメータは、ネットワークに、識別する対象の文字のサイズについてヒントを与えます。そのため、[特徴のサイズ] パラメータの設定がアプリケーションの文字のサイズから明らかに外れている場合、ツールが画像内の文字を識別しない可能性があります。
-
学習や処理をより細かく制御するには、[ヘルプ] メニューの [エキスパートモード] をオンにして、ツールパラメータの追加パラメータを初期化します。
-
-
学習セットに適切な画像を含めたら、[ブレイン]
 アイコンを押すと、ソフトウェアが学習用の計算を開始します。
アイコンを押すと、ソフトウェアが学習用の計算を開始します。-
途中で [停止]
 アイコンを押して学習を停止すると、学習は停止されますが、それまでに学習させた現在のツールは失われます。
アイコンを押して学習を停止すると、学習は停止されますが、それまでに学習させた現在のツールは失われます。
-
-
学習させた後、結果を確認します。[データベースの概要] パネルを開き、各文字および各モデルのコンフュージョンマトリックスと適合率、再現率、F 値を確認して、結果を確認します。結果の解釈の詳細については、「結果の解釈」を参照してください。
-
結果を確認した後、すべての画像を調べて、ツールが各画像の特徴とモデルをどのように正しくマークしているか、または正しくマークしていないかを確認します。
-
-
文字モデルの確認
学習が完了したら、予測される文字の数、それらの間隔と配置、およびそれらのフィールド化に基づいて文字モデルを生成できます。
-
学習の確認
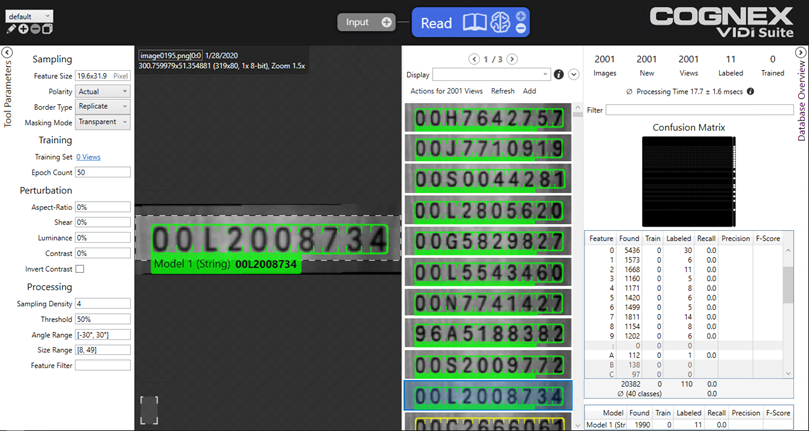
学習が完了したら、画像を見直して、ツールが画像内の文字を正しく識別していることを確認します。この場合も、[データベースの概要] ウィンドウを使用して、文字の表を見直し、結果を確認することができます。ツールが見つけた各文字は、予想される文字になります。たとえば、#2 の場合、表示ウィンドウのすべてのインスタンスは #2 になります。たとえば、"5" または "S" があるインスタンスがある場合は、その画像をクリックして、それらのインスタンスに正しいラベルを付け直す必要があります。
ツールがすべてのインスタンスを正しく見つけた場合、ランタイム展開の準備が整っています。ただし、インスタンスの一部にラベルを付け直す必要がある場合は、ツールを再度学習させてから、確認プロセスを繰り返す必要があります。
各ステップの詳細は、「読み取り (青) の学習」の各サブセクションで説明します。