対象領域 (ROI) とマスクを定義してビューを構築する
対象領域の定義 (ROI)
画像を処理するためのツールを追加すると、ぼやけた出力画像になります。これは、「ROI (対象領域) が定義されていません」というメッセージによってセグメンテーションする必要があることを示しています。これらの画像を現在のツールで使用できるようにするには、ツールの処理ボタン ([はさみ] アイコン) をクリックすることで、セグメンテーションする必要があります。
デフォルトのセグメンテーションにより、完全な画像を含むツールが提供されます。または、ROI (画像を右クリックして [ROI の編集] を選択) を手動で調整して、抽出されたビューのサイズ、位置、および方向を設定することができます。多くの場合、対象領域 (ROI) を調整してツールの操作の対象となるビューを定義する必要があります。ROI のサイズと配置は画像内のグラフィックハンドルを使用して調整できます。これによって、ROI のサイズを変更し、画像内で移動できるようになります。
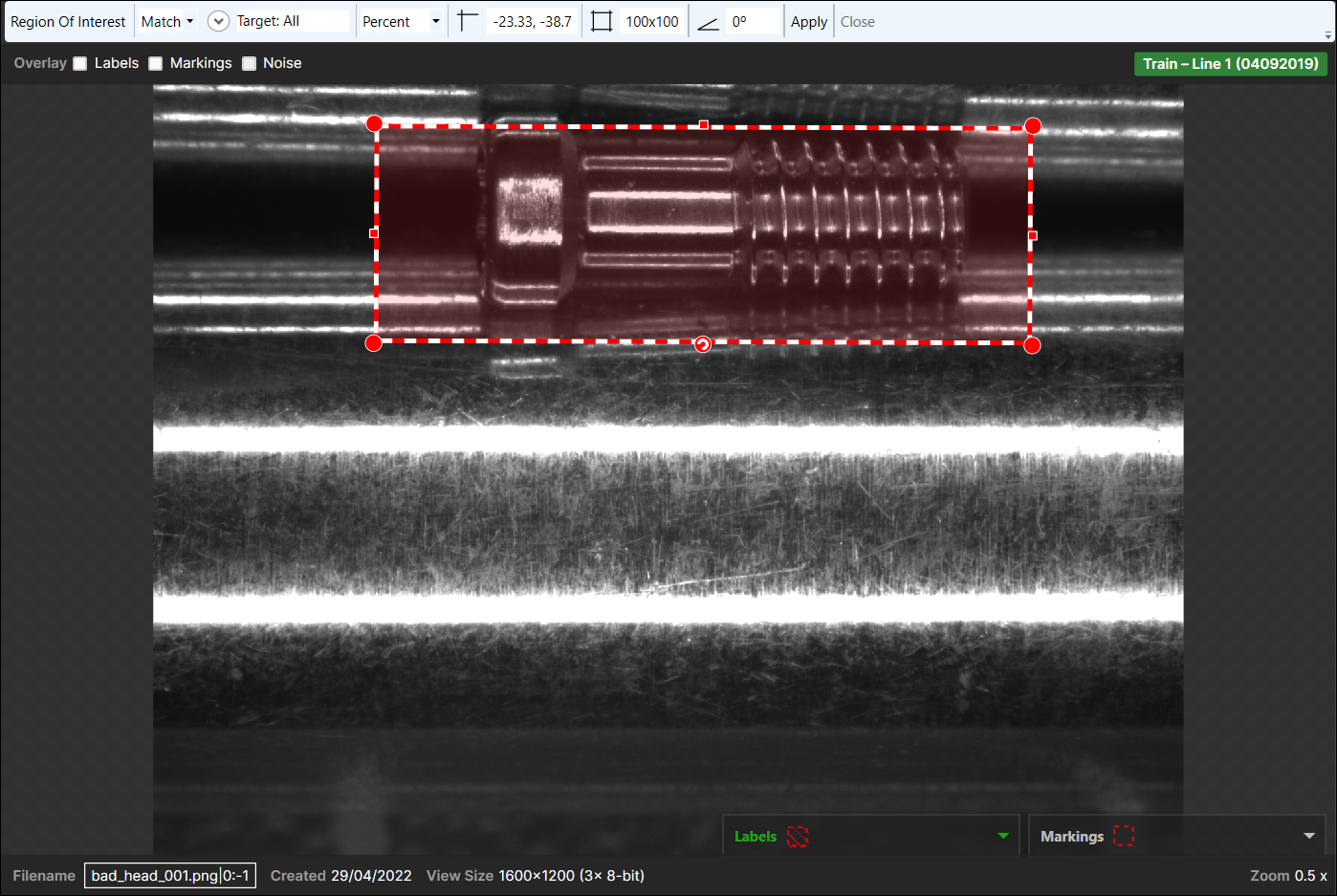
ROI の編集
ツールが最初に追加されたときには、デフォルトの対象領域ツールバーが画像の上部に表示されます (右クリックメニューから [ROI の編集] を選択して開くこともできます)。

[エキスパートモード] バージョン:

| 設定 | 説明 |
|---|---|
|
割合/ピクセル |
ROI が画像の幅と高さのパーセンテージとして作成されるか、ピクセルの寸法で作成されるかを指定します。 Note: 前のツールが位置決め (青) ツールである場合、割合はビューを定義している特徴またはノードモデルの幅と高さに基づきます。
|
|
オフセット |
ROI の元の位置からの左上のオフセットを指定します。設定は、[割合/ピクセル] の設定に応じて、パーセンテージかピクセルになります。 |
|
ROI サイズ |
[割合/ピクセル] の設定に応じて、パーセンテージまたはピクセル単位の ROI のサイズを指定します。 |
|
角度 |
ROI の元の位置からの角度を指定します。 |
|
グリッド |
グリッド設定に基づいて、画像がより小さいビューに分割されることを指定します。これは、多数の特徴や領域を含んでいることがある大きな画像を取り扱う場合に役立ちます。画像を複数の小さなビューに分割すると、視覚化とラベル付けがさらに簡単になります。別の写真編集プログラムで画像を変更する代わりに、Deep Learning アプリケーションで画像を分割できるようにすると、Deep Learning 内で画像が継続されるため、人工アーティファクトの混入を防ぐことができます。 また、ランタイム中に画像を処理する際は、[グリッド] 設定をデフォルト (1 x 1) にリセットすることができます。それによって、画像全体が一度に処理されます。 たとえば、位置決め (青) ツールによってラベル付けされ、識別される、10,000 個の小さいアイテムを含む大きな画像があるとします。画像を 10 x 10 のグリッドに分割すると、1 つの画像内の 10,000 の特徴ではなく、1 つの画像ごとに 100 の特徴を識別し、ラベル付けするだけで済むようになります。 Note: このオプションは、エキスパートモードでのみ使用可能です。
|
|
外部 |
ROI が、 Note: このオプションは、エキスパートモードでのみ使用可能です。
|
マスクの定義 (オプション)
すべての Cognex Deep Learning ツールでは、マスクを作成して適用することによって、画像の一部を学習から除外する機能をサポートしています。
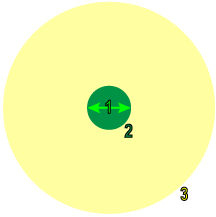
学習中および処理中に、Deep Learning ツールは、サンプリング領域の公称範囲 (ピクセル単位) である特徴のサイズを使用して、画像をサンプリングすることによって機能します。サンプリング中は、サンプル領域周辺からの大量のコンテキスト情報 (コンテキスト領域) も考慮されます。
|
|
|
|
1 |
特徴のサイズ |
|
2 |
サンプリング領域 |
|
3 |
コンテキスト領域 |
画像にマスクが適用されると、サンプリング領域内のマスクされたピクセルは必ず破棄されます。ただし、コンテキスト領域にマスクがどのように適用されるかは、[マスキングモード] パラメータによって決まります。
架空のサンプリング領域とコンテキスト領域がある、次のマスクされた画像について考えてみます。
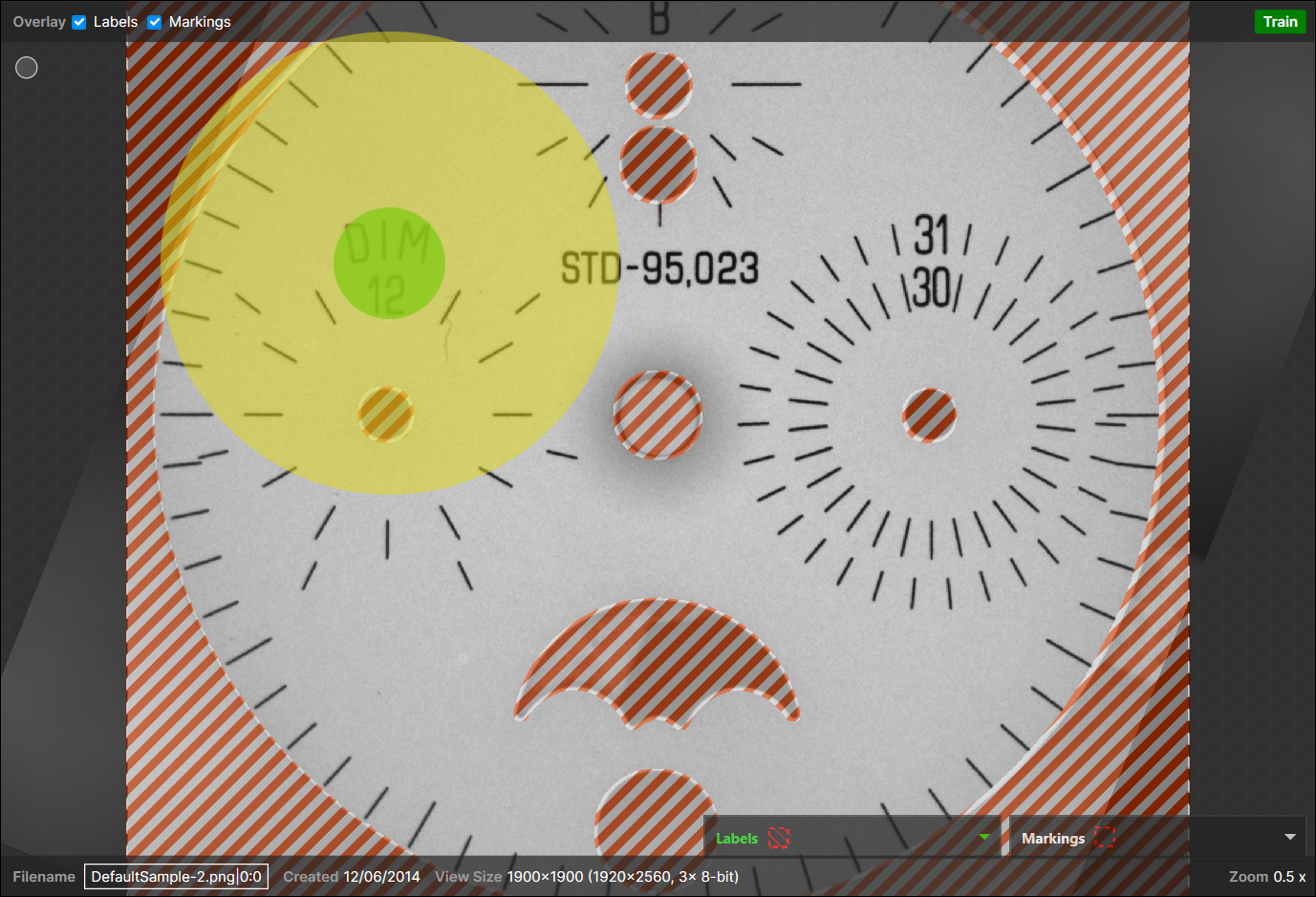
[マスキングモード] パラメータがデフォルトの [透明] に設定されている場合、画像のマスクされていない部分だけでサンプルが収集されます。ただし、コンテキスト情報は、コンテキスト領域内の明るい緑色の領域で示されるマスクされた領域からも収集されます。
![]()
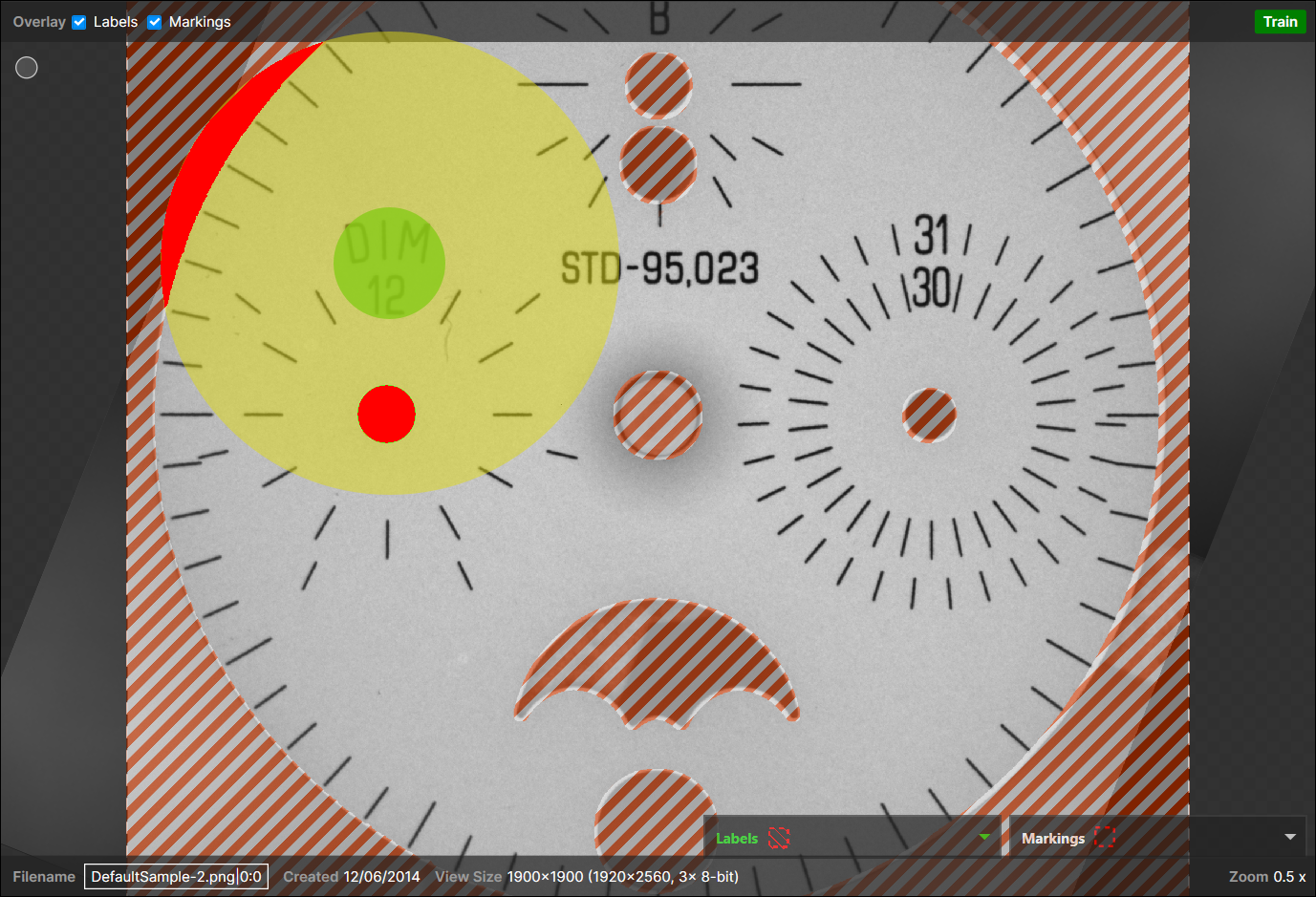
[マスキングモード] パラメータが [マスク] に設定されている場合、コンテキスト領域内の明るい赤い領域で示される、コンテキスト領域内でマスクされたピクセルはすべて破棄されます。この設定は、サンプリング中にツールに ROI の中心にフォーカスすることに効果的に集中させます。
マスクの編集 (オプション)
[マスク] ツールバーを起動するには、画像を右クリックし、メニューから [マスクの編集] を選択します。1 つの画像にマスクを適用したら、学習画像セット内のすべての画像にマスクが使用されるように [適用] をクリックします。[閉じる] ボタンを押すと、Deep Learning アプリケーションの構築プロセスに戻ります。

| 設定 | 説明 |
|---|---|
|
描画ツール |
3 つの描画ツールがあり、組み合わせて使用できます。描画領域のサイズは、[幅] の値で定義されます。
Note: 消しゴムツールを使用すると、画像上の余分な描画をトリミング/削除できます。
|
|
幅 |
マスク描画ツール、境界マスク、および拡大領域のピクセル幅を定義します。[幅] は、マスクを適用する前に設定する必要があります。描画ツール、境界マスク、または領域拡大を使用してマスクを編集している間に、[幅] の値を調整した場合、新しい値は次に作成するマスクだけに適用されます (同じ編集セッションでも、作成済みのマスクは変更されません)。 |
|
境界マスク |
[幅] の値に基づいて画像の境界の周囲にマスクを作成します。画像を取得するカメラの視野によってオブジェクトがトリミングされるため、布地や繊維など、オブジェクトを任意で切り取る画像がある場合に、画像の境界にマスクを適用すると役に立ちます。 |
|
領域拡大 |
マスクの領域を [幅] の値まで拡大します。 |
|
反転 |
マスクを反転します。つまり、マスクされた領域のマスクが解除され、マスクに含まれていなかった領域がマスクされます。 |
|
クリア |
画像からマスクを削除します。 |
|
インポート/エクスポート |
インポートおよびエクスポートボタンをクリックすると、マスク画像を .PNG ファイルとしてインポートまたはエクスポートするための [マスク画像のインポート] ダイアログおよび [マスク画像のエクスポート] ダイアログが起動します。マスク画像は、マスクがあるビューと同じサイズの 2 次元配列のピクセルです。マスク画像内のピクセル値によって、ビュー内の対応するピクセルが学習とランタイム処理のどちらに使用されるかが決まります。インポート/エクスポートオプションを使用すると、以前作成したマスク画像をインポートしたり、作成したマスク画像をエクスポートしたりできます。 |
|
取り消し/適用/閉じる/すべて適用 |
マスクのアプリケーションを制御するためのオプション。
|
ビューの構築
VisionPro Deep Learning ツールは、ビューという画像の領域で動作します。VisionPro Deep Learning のビューは、画像ファイルとは若干異なります。ビューは、ツールと用途に応じて、画像全体、ユーザが定義した画像より小さな矩形領域、またはツールの出力のいずれかになる場合があります。最初のビューは、最初のツールの対象領域 (ROI) が定義された後に描画されます。ROI は、元の画像からアフィン変換 (位置、角度、拡大、スキュー) によって定義され、ツールに画像内のどこで動作するかを指示します。画像からビューを選択するプロセスは、セグメンテーションと呼ばれます。最初に追加されたツールでは、手動でセグメンテーションを行います。つまり、ビューを作成するために ROI を定義します。
-
画像全体がオレンジ色の枠で囲まれており、ROI は赤い点線の矩形として定義されています。

-
ビューは緑色の枠で囲まれています。

ROI とビューのインデックス
1 つの画像ファイルから多くの異なる ROI を生成でき、ビューも生成できます。同じ 1 つの画像ファイルから多くの異なるビューを生成できるため、ビューのインデックスは各ビューの一意の識別子として機能します。簡単に言うと、同じ画像ファイルから 3 つのビューが生成された場合、それらのインデックスは 0、1、および 2 になります。
別の例として、解析 (赤) 親ツール (先行ツール) をツールチェーンで使用する場合、その子ツールは、[領域を個々の ROI として抽出します] 機能によって親ツールの欠陥領域を ROI として使用した場合、多くのビューを持つことができます。
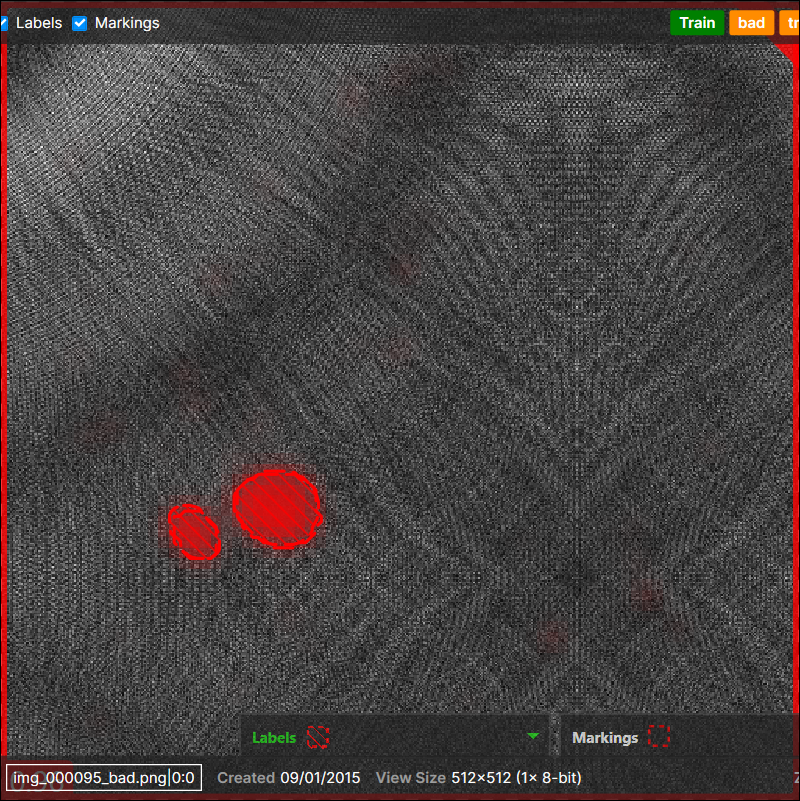
解析 (赤) - 分類 (緑) ツールチェーン

解析 (赤) 親ツールのビュー (画像ファイル) 上の 2 つの欠陥
分類 (緑) 子ツールの ROI の設定:領域を個別の ROI として抽出します


1 つの画像ファイルから 2 つのビュー (1 つの欠陥に対して 1 つのビュー) が生成されます
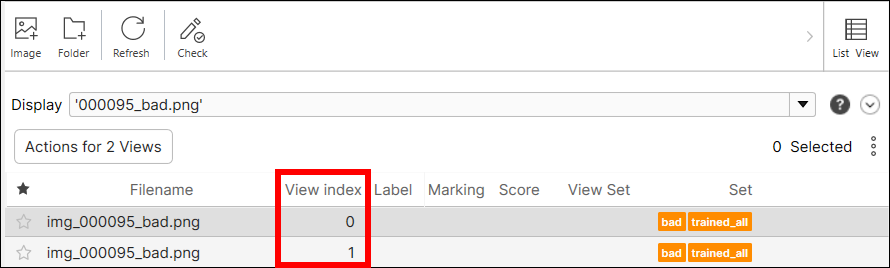
 を選択し、[列の編集] を開き、[ビューのインデックス] チェックボックスを有効にして、[適用] を選択します。
を選択し、[列の編集] を開き、[ビューのインデックス] チェックボックスを有効にして、[適用] を選択します。
ROI が設定されていないビューのインデックスは -1 です。たとえば、上記の場合、解析 (赤) 親ツールのビューに欠陥領域がない場合、子ツールはこのビューから ROI を抽出できないため、このビューには ROI がなく、ビューのインデックスは -1 になります。さらに、ビューに ROI がない場合、ファイル名の末尾に黄色の警告記号が表示されます。

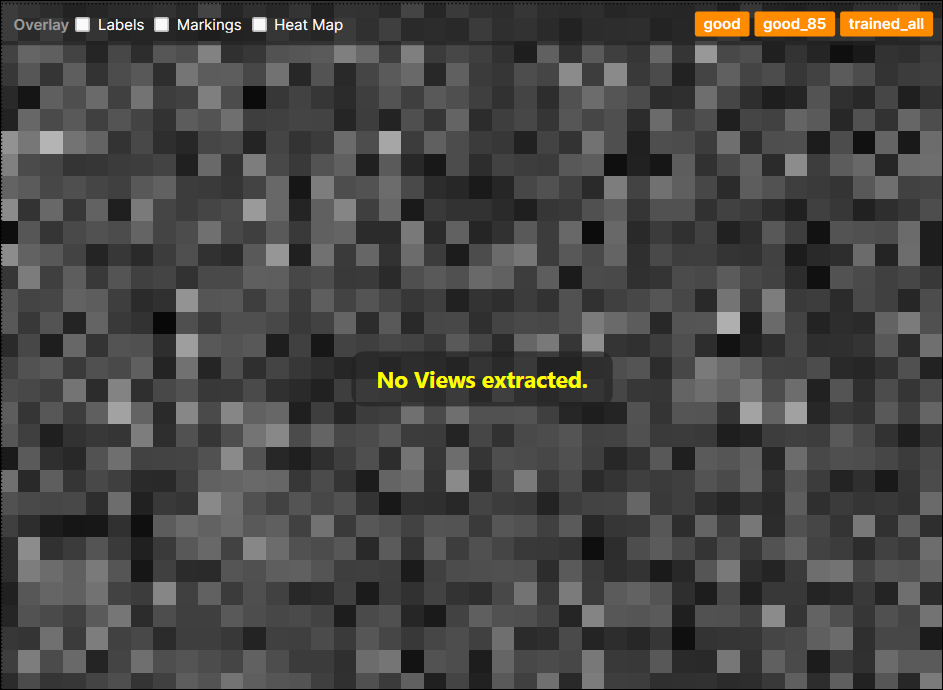
ビューのステータスの確認
各ビューのステータスの詳細は、ビューブラウザのリストモードのビュー情報テーブルに記載されています。各ビューのステータス情報は、ツールのタイプによって異なります。
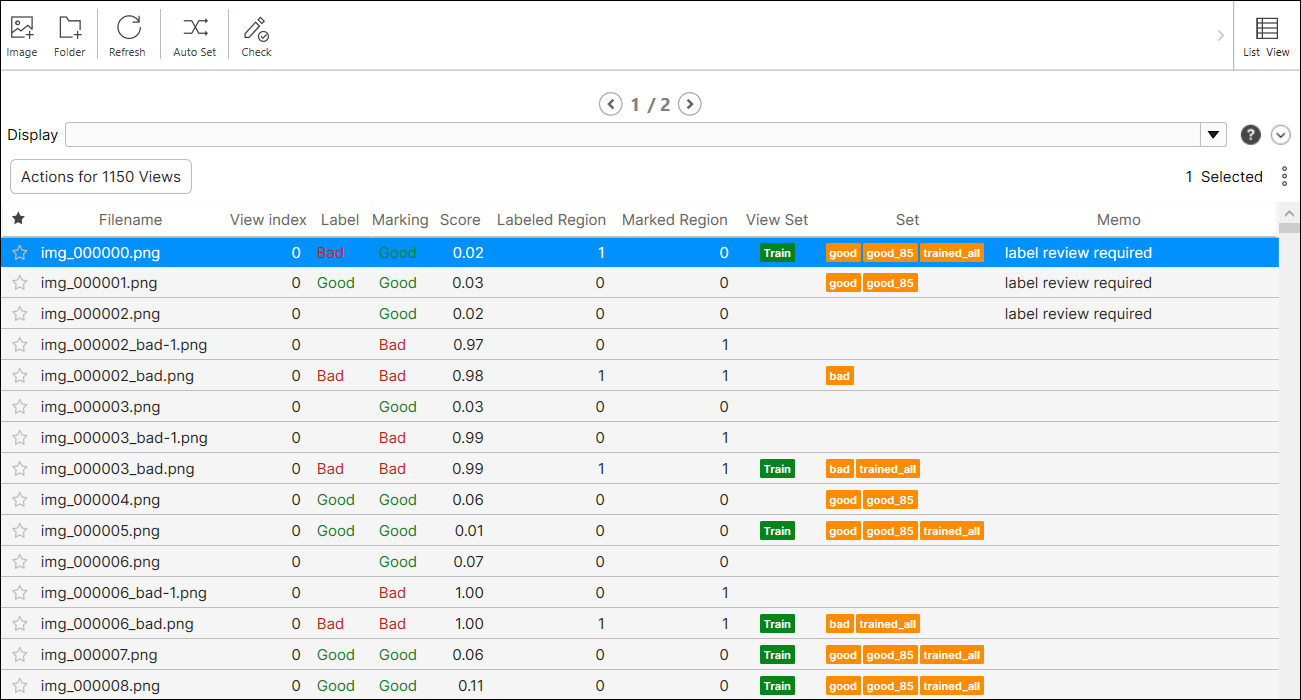
| 列 | 説明 |
| ファイル名 | 現在のストリームに読み込まれたビューの画像ファイル名。1 つの画像ファイルから多数の異なるビューが生成される場合、それらのビューのファイル名は同じになります。 |
| ビューのインデックス | ビューのインデックス。1 つの画像ファイルから多数の異なるビューが生成される場合、ビューのインデックスは各ビューの一意の識別子として使用されます。たとえば、3 つのビューが同じ画像ファイルから生成された場合、それらのファイル名は同じになり、ビューのインデックスは 0、1、および 2 になります。ビューのインデックスは、ビューブラウザのリストモードではデフォルトで非表示になっていることに注意してください。ビューのインデックスを表示するには、 を選択し、[列の編集] を開き、[ビューのインデックス] チェックボックスを有効にして、[適用] を選択します。 |
| フレームインデックス |
フレームのインデックス。複数の画像を 1 つのフレームにまとめることができ、フレームインデックスは各フレームに一意の識別子です。 |
| ラベル | ビューのラベル。詳細については、「ラベルの作成 (ラベル付け)」を参照してください。 |
| マーキング | ビューのマーキング。詳細については、「マーキングの確認」を参照してください。 |
| 得点 | ビューの得点。詳細については、「結果の解釈」を参照してください。 |
| ラベル付き領域 | このビューのラベル付き領域の数。 |
| マークされた領域 | このビューのマークされた領域の数。 |
| ビューセット | 学習セットまたは検証 (High Detail) セットに含まれるマーク。ビューがテストセットに含まれている場合、マークはありません。 |
| セット | ユーザーが作成したカスタムセットに含まれるマーク。詳細については、「セットを作成および編集する」を参照してください。 |
| メモ | ユーザーが記述または編集したカスタムメモ。 |
| ラベル品質 | ラベル品質チェックの完了後に計算されたビューのラベルの品質の値。詳細については、「ラベルチェックによるラベル付けの最適化」を参照してください。 |
ビューブラウザのリストモードでビューを制御する
リストモードでは、現在の VisionPro Deep Learning ワークスペースへの新規画像の追加、学習セットへの画像の追加、表示されているビューへのフィルタの適用、表示されているビューのソートなど、各ビューに対する操作も可能です。
情報テーブルを操作する
各列見出しをクリックして、情報テーブルの内容を並べ替えます。
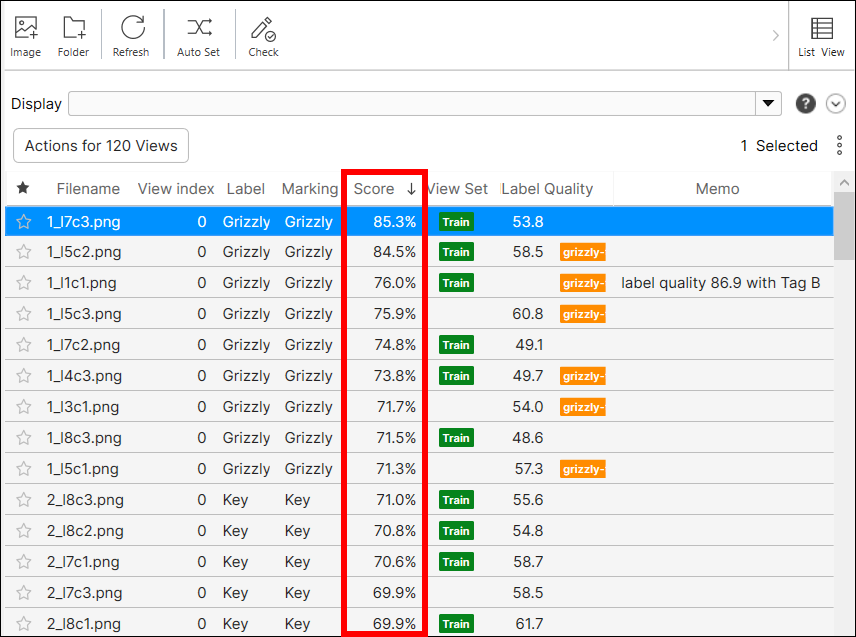
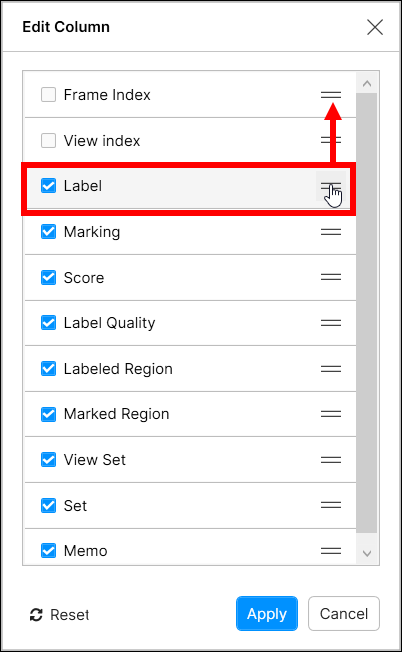
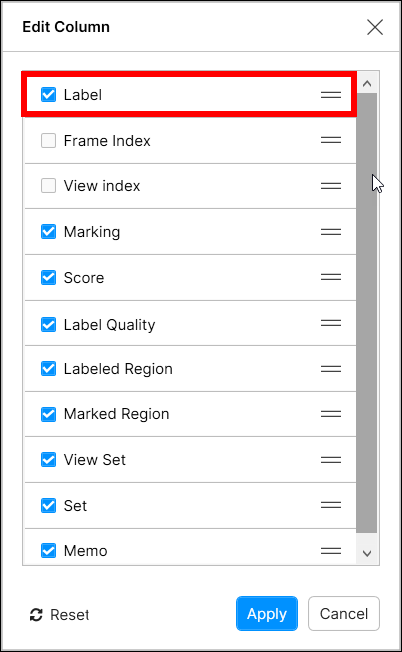
列見出しをドラッグして好きな場所にドロップするだけで、表示される列の順序を変更することができます。
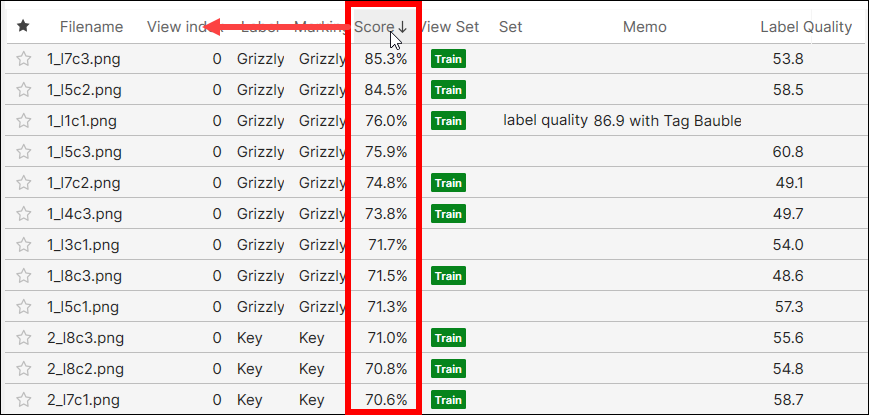
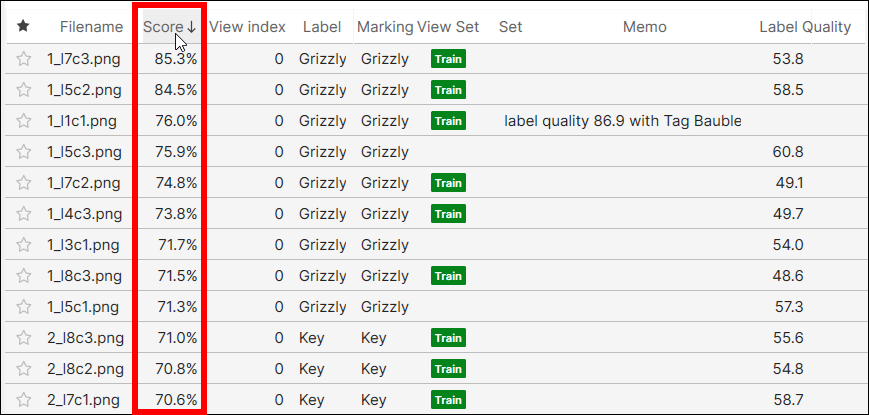
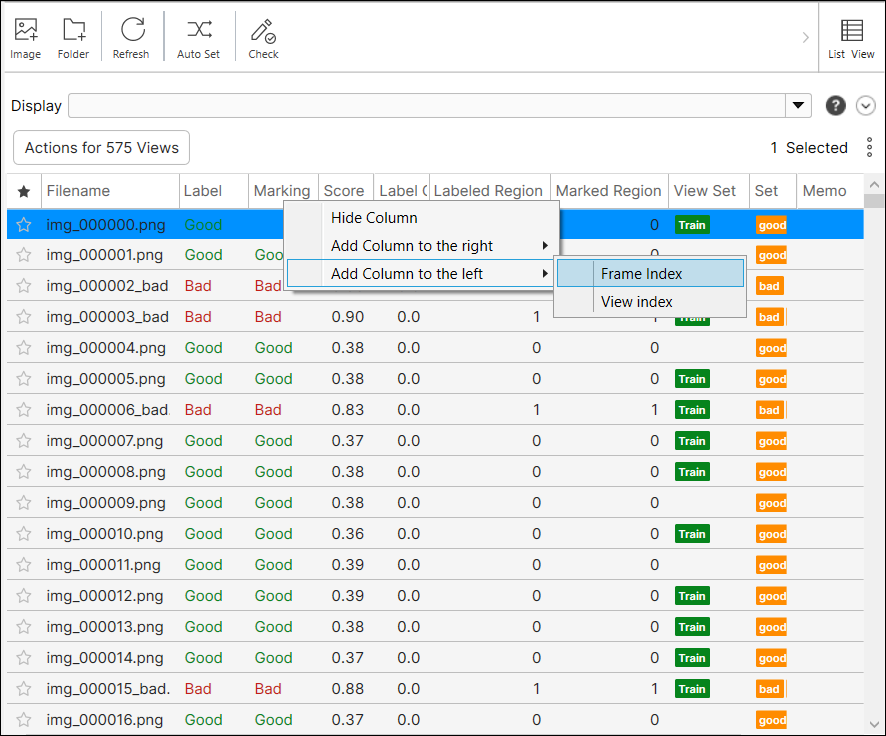
ボタンをクリックして、表示されている列のリストを編集します。
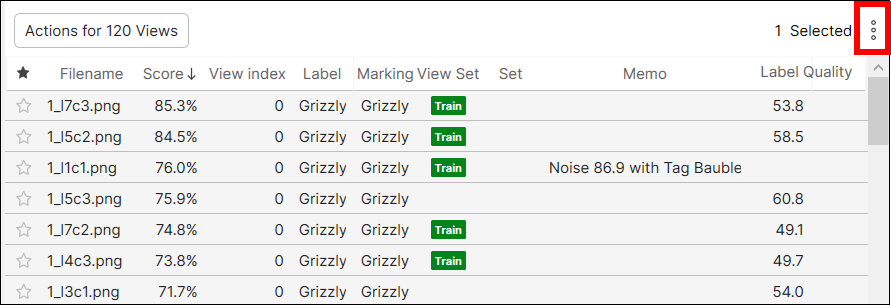
[列の編集] ダイアログで、チェックを有効/無効にして、列を表示または非表示にします。[リセット] を選択して、公開する列のリストと列の順序をデフォルトに設定します。
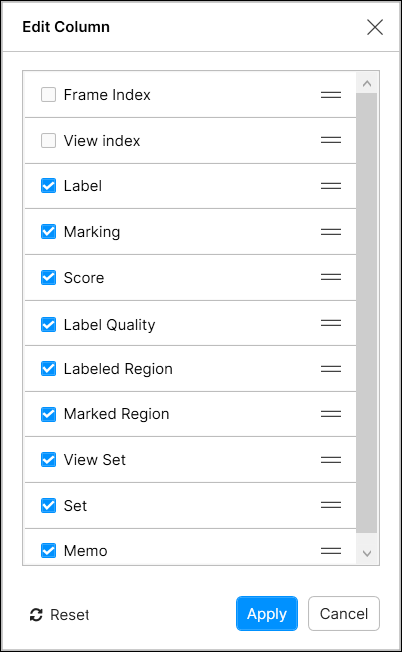
また、各列の  アイコンをドラッグアンドドロップすることで、カラムの表示順を変更することができます。
アイコンをドラッグアンドドロップすることで、カラムの表示順を変更することができます。
また、列のヘッダーを右クリックすると、列を直接非表示にしたり追加したりすることができます。
ビューに星印を付ける
重要なビューや頻繁にアクセスする必要のあるビューには、星印を付けてブックマークを作成することができます。
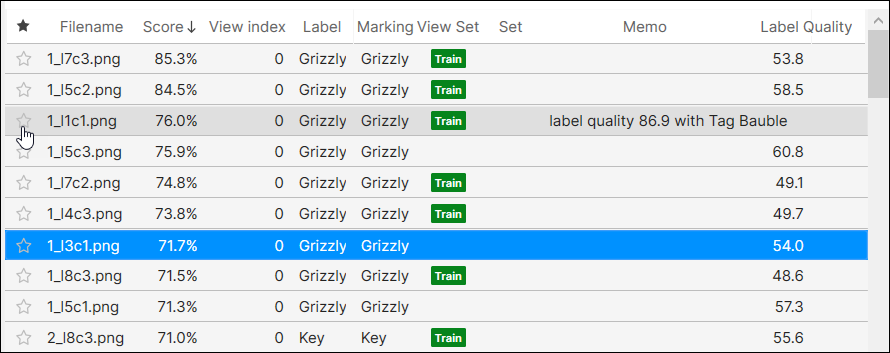
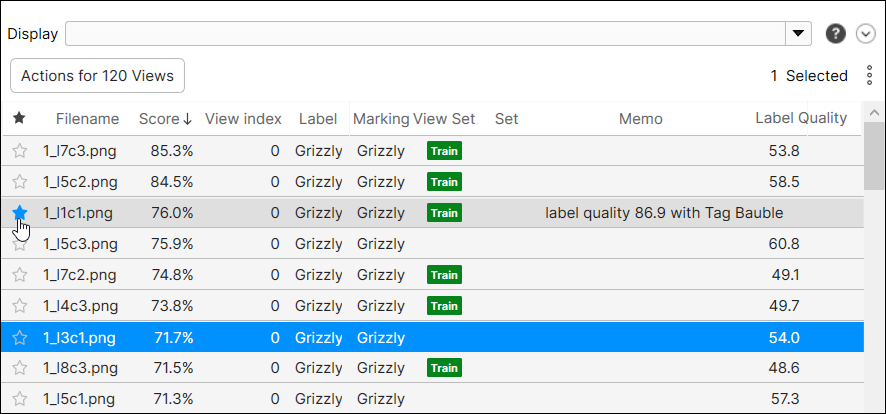
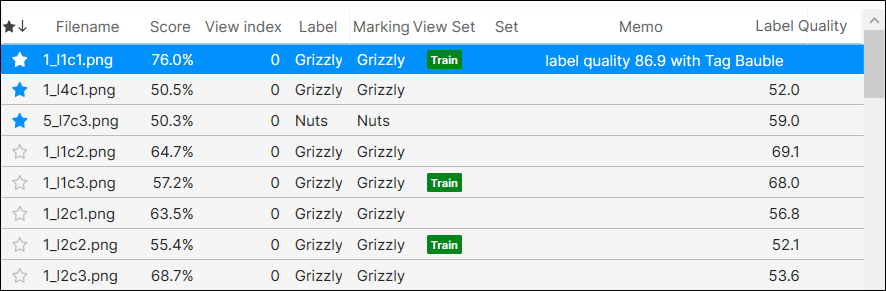
星印は、現在のツールのビューにのみ適用され、他のツールの同じビューには適用されません。ツールチェーンを使用する場合、親ツール (上流のツール) の星印が付いたビューは子ツール (下流のツール) では星印が付いたままではなく、その逆も同様です。ただし、ビューに星印を付けて現在のツールをクローン作成すると、クローン作成したツールの同じビューに星印が付いたままになります。
メモの投稿
ビューごとにメモを貼ったり編集したりすることができます。[メモ] をダブルクリックすると、各ビューのメモを作成または編集できます。
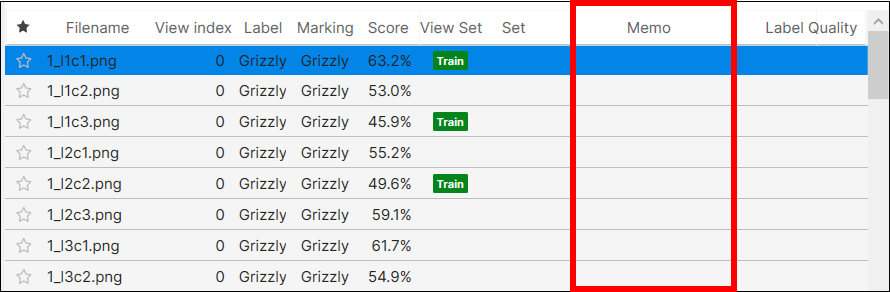

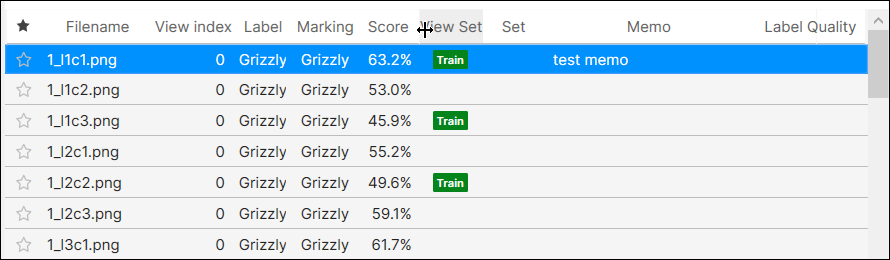
メモの投稿は、現在のツールのビューにのみ適用され、他のツールの同じビューには適用されません。ツールチェーンを使用する場合、親ツール (上流のツール) のビューのメモは、子ツール (下流のツール) の同じビューには保持されず、その逆も同様です。ただし、ビューにメモを付けて、現在のツールをクローン作成すると、クローン作成したツールの同じビューにメモが保存されます。