ニューラルネットワークの学習
すべてのビューが正しくラベル付けされ、学習画像とテスト画像に分割された後、ニューラルネットワークの学習は、次の一般的な方法で実行されます。
- ツールのパラメータを設定し、学習を開始します。[ブレイン] アイコンを押して、ツールを学習させます。アーキテクチャが フォーカス の場合、学習に使用されている画像セット内の各画像 ([学習セット] ダイアログで定義) が、指定された特徴のサイズを使用して全体でサンプリングされます。
- 結果のサンプルが、VisionPro Deep Learning ディープニューラルネットワークに入力として提供されます。
- ニューラルネットワークは、サンプルごとに特定の応答 (ツールの種類に応じて) を生成し、この応答が、学習画像内のサンプルの位置に関連付けられた画像のラベル付けと比較されます。
- サンプルが処理され、再処理されるにつれて、ネットワーク内部の重みが繰り返し調整されます。ネットワーク学習システムは、ネットワークの応答とユーザによって提供されたラベル付けの間の誤差 (差異または不一致) を低減することを目標にして、ネットワークの重みを絶えず調整します。
- すべての学習画像サンプルが、エポック数パラメータで指定された回数以上含まれるまで、このプロセス全体が何度も繰り返されます。
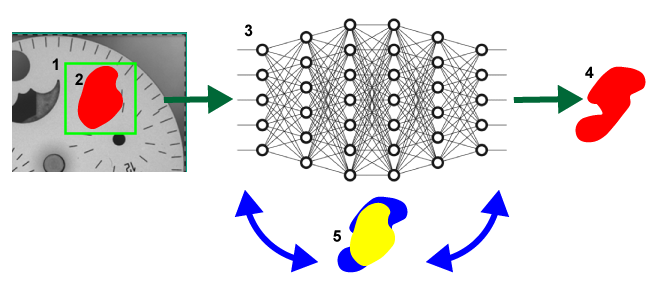
-
サンプリング領域。
-
ユーザが描画したラベル付き欠陥領域。
-
ニューラルネットワーク。
-
ネットワークによる応答。
-
ラベル付き欠陥 (黄) とネットワークの応答 (青) の間の不一致 (つまり、誤差) を低減するために重みを繰り返し調整するプロセス。
ニューラルネットワークの学習の特性は、学習させているツールの種類に応じて多少異なります。スーパーバイズドモードの解析 (赤) ツールのネットワークの学習目標は、欠陥のラベル付けと検出された欠陥の間の空間的不一致を低減することです。解析 (赤) High Detail の場合、ネットワークには、解析 (赤) フォーカススーパーバイズド のように画像内の欠陥領域を見つけて識別することを学習させます。High Detail で解析 (赤) ツール用に行うラベル付けでは、ラベル付き画像内のすべての欠陥ピクセルにラベルを付けます。
-
サンプリング領域とサンプリングパラメータ
解析 (赤) フォーカススーパーバイズド は、ユーザが定義したサンプリング領域を持つピクセルをサンプリングしますが、解析 (赤) High Detail は画像全体からサンプリングするため、サンプリング領域がなく、学習時にサンプリングパラメータを必要としません。
-
検証を使用した学習
解析 (赤) High Detail は検証データセットを使用して、学習した各ニューラルネットワークを検証し、これらの検証の結果に基づいて、指定された学習セットで最もパフォーマンスが高く安定したニューラルネットワークを選択します。
ツールのパラメータの設定
ツールが追加された後は、ツールのパラメータにアクセスして学習前のツールのパフォーマンスと、ツールがランタイム操作中に画像をどのように処理するかを微調整できます。VisionPro Deep Learning ツールのパラメータは、ニューラルネットワークモデルの学習方法とツールの統計結果の処理方法を調整します。
解析 (赤) ツールの [アーキテクチャ] パラメータが [High Detail] に設定されている場合、画像全体を公平に考慮するようにツールが構成されます。このオプションを使用すると、ピクセルレベルで精度の高い結果や詳細な結果を取得できますが、学習および処理時間が長くなります。High Detail モードの解析 (赤) ツールのツールパラメータには 4 つのカテゴリがあります。各パラメータの詳細情報については、以下を参照してください。
アーキテクチャパラメータ
アーキテクチャパラメータ は、使用されるニューラルネットワークモデルのタイプを選択します。このオプションは、精度の高い結果の取得に有用ですが、学習およびプロセス時間が長くなります。High Detail モード設定および High Detail Quick アーキテクチャ設定では、画像全体が公平に考慮されるようツールが構成されます。一方、フォーカスアーキテクチャ設定は選択的で、有用な情報を含む画像の部分に照準が合わされます。そのため、特に画像のあらゆる場所に重要な情報が存在する場合、重要な情報を十分にネットワークで伝送できない可能性があります。
モードのパラメータ
日常業務の最前線で新たに取り込んだ画像は、既存のツールを構築した学習画像とばらつきがある場合があります。モードのパラメータを使用すると、以前に学習させたツールを生産ラインから取り込んだばらつきのある新しい画像に適応させることができます。詳細については、「アダプテーションモード:ラインバリエーションへのアダプテーション」を参照してください。
ネットワークモデルパラメータ
ネットワークモデルパラメータを使用すると、学習ツールネットワークのサイズを選択し、学習と処理に必要な時間を変更することができます。High Detail モードには「小規模」、「標準」、「大規模」、「超大規模」の 4 つのネットワークモデルがあります。
-
「標準」ネットワークモデル (デフォルト) は通常、一般プロジェクトに使用されます。
-
複雑な画像については大きなネットワークモデルが有用ですが、これは、必ずしもパフォーマンスが優れていることを意味しません。大きなネットワークモデルには、オーバーフィッティングのリスクがあります。ネットワークモデルが大きくなると、学習と処理時間が長くなります。
通常のネットワークモデルでパフォーマンス (再現率、適合率、F1 得点) が低い場合は、パフォーマンスを向上させるために、通常は小規模ネットワークモデルに切り替えることをお勧めします。
学習パラメータ
学習処理を制御する学習機能ツールのパラメータ。ツールの学習が終了した後に学習機能ツールのパラメータを変更すると、学習が無効になり、ツールの再学習が必要になります。
| パラメータ | 説明 |
|---|---|
|
エポック数 |
すべての学習画像の学習回数。数値が大きいほど反復回数が多くなります。1 ~ 100000 の値を指定してください。 Tip: High Detail モードで使用されるエポック数の概念はフォーカスモードとは異なります。High Detail モードでは、データベースが同じ場合はフォーカスモードよりもエポック数を大きくすることをお勧めします。
|
|
学習セット |
ディープラーニングモデルの作成に使用するデータセット。つまり、ディープラーニング時に学習セットに含まれている画像の特徴のみが抽出されてディープラーニングモデルが作成されます。 |
|
検証セット比 |
学習セットのうち、検証セットとして使用されるビュー数の割合。検証セット比として入力できる数値は 1% ~ 50% です。 |
|
最小エポック |
High Detail モードで検証セットを使用することで、少ないエポック数から作成されたモデルを最終モデルとして選択してオーバーフィッティングを防止できます。最小エポックを設定した場合、High Detail モードで、このエポック以降に作成されたモデルが最終モデルとして選択されます。 |
|
ペイシェンスエポック |
反復が一定回数行われるたびに、High Detail モードではモデルの損失値が測定されます。N (ペイシェンスエポックの値) エポックで損失値の低下が確認されなかった場合、High Detail モードの学習が停止し、エポック数までの損失値が最小であるモデルが選択されます。損失値が一定時間にわたって低下しない限り、学習プロセスを継続する必要性がない場合にペイシェンスエポック値を利用して早期にプロセスを停止できます。 Tip:
|
|
パッチサイズ |
各ビューをいくつかのまとまりに分ける正方形のサイズ。各ビューの学習 (特徴の検出) と処理は、まとまりごとに実行されます。一般的に、学習の収束速度に関しては、パッチサイズを小さくすると、微小なブロブを検出するのに適し、パッチサイズを大きくすると、顕著で大きいブロブを検出するのに適しています。 |
学習パラメータの詳細:エポック数
[エポック数] パラメータを使用すると、実施するネットワーク調整の度合いを制御することができます。「ニューラルネットワークの学習」のトピックで説明したように、学習プロセスでは、ネットワークを通して入力サンプルを繰り返し処理して、ネットワークの結果をユーザが提供するラベル付けと比較し、エラーを減らす目的でネットワークの重みを調整します。ネットワークノード (重み) が多数存在するため、このプロセスはほとんど無限に繰り返すことができ、繰り返す内に、わずかながら徐々にエラーを改善することができます。[エポック数] パラメータ設定を上げると、実施される学習の繰り返し回数が増えます。これによって、学習に要する時間は長くなりますが、学習画像のネットワークエラーを減らすことができます。
ただし、ネットワークを学習させる目的は、学習に使用される画像だけでなく、すべての画像で正確に動作することなので注意してください。エポック数を上げると、ネットワークはオーバーフィット (用語) する傾向があり、未学習画像におけるエラーが増え、学習された画像におけるエラーは減ります。このために、エポック数を調整しながら、すべての画像におけるネットワークパフォーマンスを注意深くモニタする必要があります。最適値はデータセット、特にデータセットの統計的多様性によって異なるため、データセットに最適なエポック数を選択する必要があります。
学習パラメータの詳細:最小エポック
検証セットを設定すると、High Detail モードで少ないエポック数から作成されたモデルを最終モデルとして選択してオーバーフィッティングを防止できます。最小エポックを設定した場合、High Detail モードで、このエポック以降に作成されたモデルが最終モデルとして選択されます。
学習セットで良好な処理結果が得られるが、テストセットで良好な処理結果が得られない場合は、オーバーフィッティングが考えられます。ただし、学習セットとテストセットの両方で良好な処理結果が得られない場合は、アンダーフィッティングが考えられます。この場合は、最小エポックを高くするようにお勧めします。
学習パラメータの詳細:ペイシェンスエポック
エポックが一定回数 (1/8 エポック) 行われるたびに、High Detail モードではモデルの損失値が測定されます。N (ペイシェンスエポックの値) エポックで損失値の低下が確認されなかった場合、High Detail モードの学習が停止し、エポック数までの損失値が最小であるモデルが選択されます。損失値が一定時間にわたって低下しない限り、学習プロセスを継続する必要性がない場合にペイシェンスエポック値を利用して早期にプロセスを停止できます。
学習パラメータの詳細:ペイシェンスエポックと最小エポック
VisionPro Deep Learning 2.1.1 以前のバージョンでは、学習時にペイシェンスエポックの前に最小エポックが適用されました。これは、最小エポックが経過した後にペイシェンスエポックのカウントが開始されることを意味します。これに対し、VisionPro Deep Learning 3.0 以降では、学習時の最小エポックとは別にペイシェンスエポックが適用されます。その結果、VisionPro Deep Learning 3.0 以降のバージョンの最小エポックとペイシェンスエポックは、VisionPro Deep Learning の下位バージョンと比較して異なる動作をするようになりました。VisionPro Deep Learning 3.0 の学習でペイシェンスエポックと最小エポックがどのように適用されるかについては、以下の例を参照してください。
以下の例はすべて、次のパラメータ設定を使用しています。
-
ペイシェンスエポック:5
-
最小エポック:10
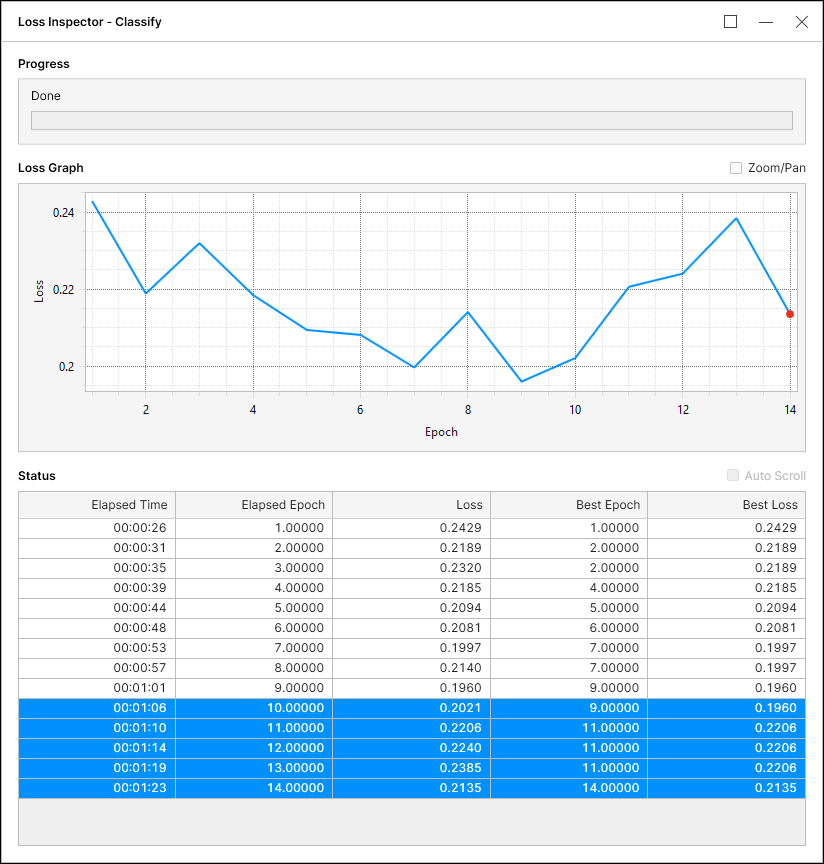
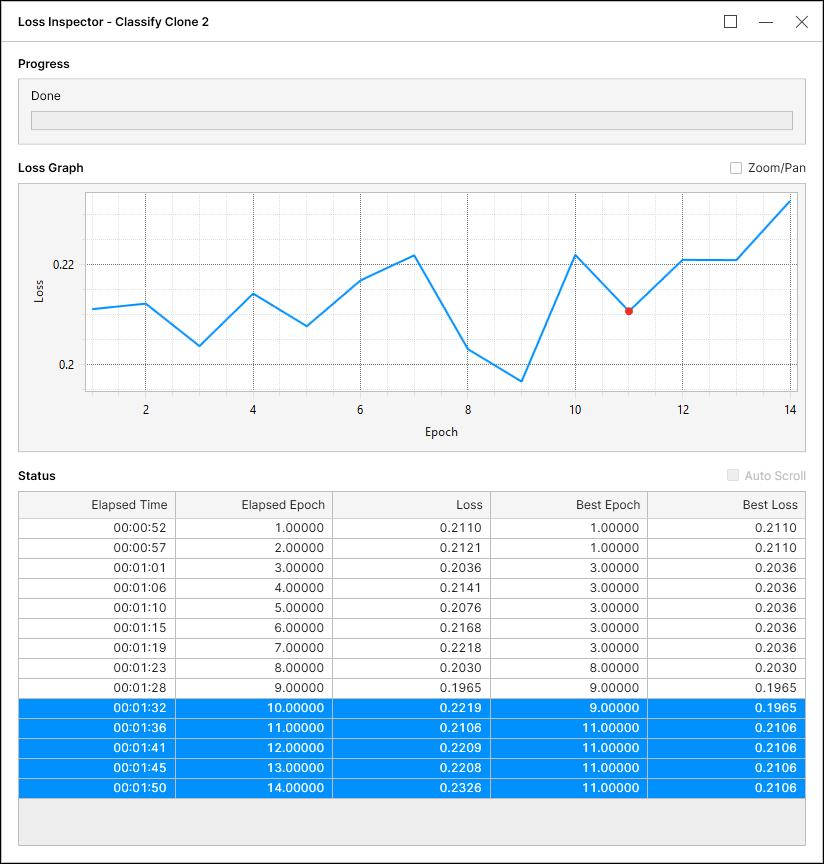
例 1ツールは、最小エポックに関係なく、これまでで最適な損失 (0.1960) が再び更新されることを期待して 5 エポック待機しました。待機後に最適な損失 (0.1960) が更新されなかったため、ツールは学習を停止し、最小エポック後のエポックの中から最適な損失を選択します。対応する最適な損失は、エポック 14 で 0.2135 となります。
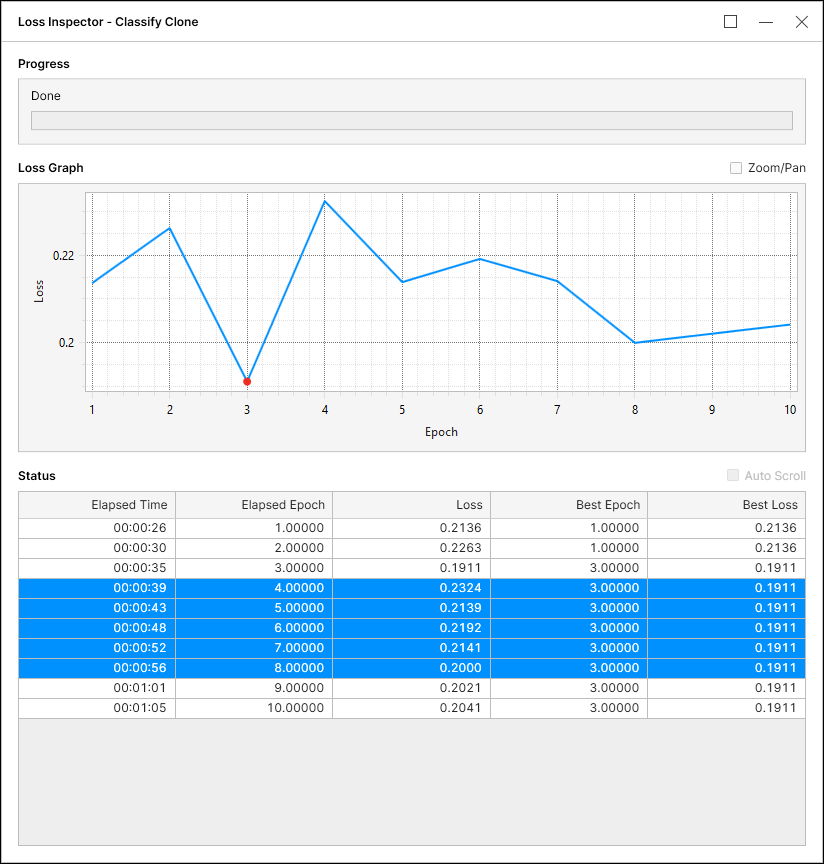
例 2ツールは、最小エポックに関係なく、これまでで最適な損失 (0.1911) が再び更新されることを期待して 5 エポック待機しました。待機後、最高損失 (0.1911) は更新されませんでしたが、ツールはエポック 10 に向けて学習を継続し、最小エポック条件も満たしました。ツールはエポック 10 に達したときに最適な損失を選択し、対応する最適な損失はエポック 3 で 0.1911 となります。
例 3ツールは、最小エポックに関係なく、これまでで最適な損失 (0.1965) が再び更新されることを期待して 5 エポック待機しました。待機後に最適な損失 (0.1965) が更新されなかったため、ツールは学習を停止し、最小エポック後のエポックの中から最適な損失を選択します。対応する最適な損失は、エポック 11 で 0.2106 となります。
学習パラメータの詳細:検証セット比
学習セットのうち、検証セットとして使用されるビュー数の割合です。学習セットの数を維持したまま検証セット比を高くすると、学習に使用されるデータ量は少なくなります。そのため、検証セット比を高く設定した場合、少ない学習セットを使用するのでパフォーマンスに悪影響を与える可能性があります。
一方、低すぎる検証セット比は、見えないデータセットに適したモデルを選択するのに役立ちません。
学習パラメータの詳細:パッチサイズ
パッチサイズは、各ビューをいくつかのまとまりに分ける正方形のサイズです。各ビューの学習 (特徴の検出) と処理は、これらのまとまりごとに実行されます。一般的に、学習の収束速度に関しては、パッチサイズを小さくすると、微小なブロブを検出するのに適し、パッチサイズを大きくすると、顕著で大きいブロブを検出するのに適しています。
摂動パラメータ
VisionPro Deep Learning ニューラルネットワークには、実際に見た画像内の特徴だけを学習させることができます。学習画像セットには、すべての標準的な画像およびパーツのばらつきを表す典型的な画像のセットが含まれていることが理想です。ただし、多くの場合は、典型的ではない画像セットを使用して学習を実行する必要があります。特に、画像セットは短期間で収集される場合が多いため、時間の経過による標準的なパーツや照明のばらつき、およびカメラの光学的特性や外的特性の変化や調整が反映されません。
VisionPro Deep Learning 学習システムでは、次のような摂動パラメータを使用して、操作中に予想される外観のばらつきの種類を指定することによって画像セットを補うことができます。
- 輝度
- コントラスト
- 回転
The Perturbation parameters allow the VisionPro Deep Learning tools to artificially generate images to be trained on, improving results for applications with high amounts of variance.これらのパラメータは、すべてのツール間で共通しています。摂動パラメータは、組み合わせることもできます。パラメータを個別に使用したり、組み合わせて使用することで、さらに複雑な画像を生成できるようになります。
High Detail モードには 13 の摂動オプションがあります。生産ラインで実際にありえる摂動オプションのみ使用してください。
| 摂動 | 説明 |
|---|---|
|
水平方向の反転  
|
水平方向に反転を行います。
|
|
垂直方向の反転 
|
垂直方向に反転を行います。 |
|
90° 回転 
|
+90° の回転のみ行います。
|
|
回転 
|
0° ~ 45° の回転を実行します。 |
|
コントラスト 
|
すべてのチャネルのランダム値を乗算することでコントラストを調整します。ランダム値は、0 ~ 2 の範囲内で一様分布に従います。 |
|
輝度 
|
すべてのチャネルのランダム値を加算することで輝度を調整します。ランダム値は、-255 ~ 255 の範囲内で一様分布に従います。
|
|
Colorwise 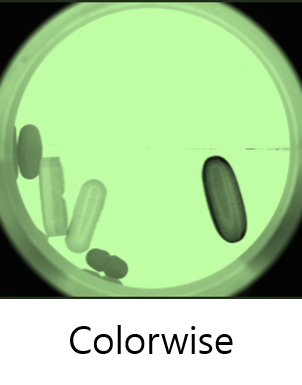
|
チャネルごとに異なるランダム値を乗算または加算することによって色を調整します。
|
|
グラデーション 
|
グラデーションをランダムに調整します。 |
|
拡大 
|
中心からビューをランダムに拡大します。最大拡大率は元のビューサイズの 6 分の 5 倍です。ランダム変数は一様分布に従います。
|
|
シャープ 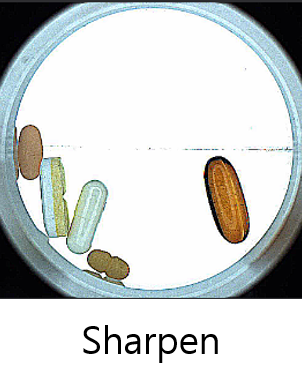
|
0 〜 2 の範囲で画像フィルタリングを行うことにより、ランダムにビューを鮮明にします。
|
|
ぼかし 
|
ガウスぼかしをビューにランダムに適用します。ランダム変数は、0 ~ 2 の範囲内でガウス分布に従います。
|
|
歪み 
|
ビュー内のポイントを選んでそれらを移動することにより、ビューに歪みを適用します。ポイントの数は 6 個以下です。
|
|
ノイズ 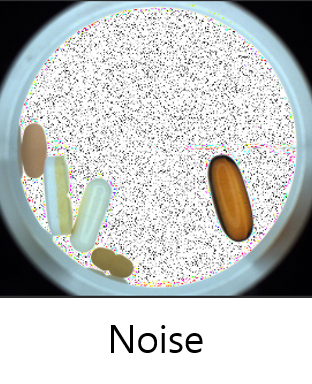
|
すべてのチャネルのピクセルあたりのランダム値を乗算することでノイズを調整します。ランダム値は、0 ~ 2 の範囲内で一様分布に従います。
|
大数の法則により、すべての摂動オプションは、エポック数を増やすことによって公平に適用し、学習することができます。
最後のパラメータの回復:パラメータの復元
[パラメータの復元] ボタンは、ツールのパラメータ値を最後の学習タスクで選択した値に簡単に戻すための機能です。最後の学習セッションで使用されたツールパラメータのすべての値が記憶されています。したがって、その値のいずれかを変更し、その変更を元に戻したい場合は、このボタンをクリックして、最後の学習で使用されたツールパラメータ値にロールバックすることができます。ツールを学習させていない場合、またはツールパラメータ値の初期セットから変更していない場合は、このボタンは無効になっています。
次の手順では、パラメータの復元がどのように機能するかを説明します。
-
現在のツールを学習させていない場合、[パラメータの復元] ボタンは常に無効です。
-
現在のツールを学習させると、パラメータロールバックのチェックポイントが最後の学習セッションのツールパラメータの値に設定されます。この時点で、ツールパラメータの値を変更した場合、ボタンが有効になります。
-
[パラメータの復元] ボタンをクリックすると、変更した値がチェックポイントの値に戻ります。
-
ツールパラメータをいくつか変更して現在のツールに再び学習させた場合、パラメータロールバックのチェックポイントは変更後のパラメータ値に更新されます。この場合も、ツールパラメータの値をさらに変更しない限り、ボタンは無効です。
-
さらに変更して [パラメータの復元] ボタンをもう一度クリックすると、変更した値が更新後のチェックポイントの値に戻ります。
処理パラメータの値を変更した後に学習済みツールを再処理する場合、パラメータロールバックのチェックポイントは更新されないため、[パラメータの復元] は有効なままになります。チェックポイントは、ツールの学習が完了した後にのみ更新されます。
|
無効 |
有効 |
これらのパラメータを変更するとツールがリセットされる不可逆的なパラメータ
[ネットワークモデル]、[排他的]、[特徴のサイズ]、[マスキングモード]、[カラー]、[中心]、[スケール調整済み]、スケール調整済みのモード ([均一]/[不均一])、[レガシーモード]、[回転済み]、[詳細]
本質的に可逆的ではない不可逆的なパラメータ
[低適合率]、[単純領域]
その他の不可逆的なパラメータ
分類 (緑) High Detail および 分類 (緑) High Detail Quick の [学習セット]、[ヒートマップ] (このパラメータは予測パフォーマンスに影響しません)
読み取り (青) のマスキングモードの [オーバーレイ] パラメータ
ニュートラルネットワークの学習の制御
解析 (赤) High Detail の学習は、ツールのパラメータと学習セットを設定することで制御できます。
学習セット
ネットワークの学習フェーズに影響を与える最大で唯一の決定要素は、学習セットの構成です。ネットワークの学習フェーズを制御するための最善の方法は、ツールに適切な学習セットを構築することです。この方法で、ツールが画像/ビューを正しく汎化しているかどうかをユーザが判断できるカテゴリに分類します。
検証セットと検証損失
学習セットの使用はすべてのツールに共通していますが、High Detail ツールには「検証セット」または「検証データ」と呼ばれる別のデータセットがあり、これは学習セットの一部で、そのデータの量はユーザが選択します。High Detail モードでは、学習フェーズで各モデルの検証損失 (=検証データから計算された損失) を計算し、パフォーマンスと可用性の観点から最適検証損失をもたらすモデルを最終的に学習の結果として選択します。
検証データの目的は、学習の最終的な結果として、学習データから生成された多数のニューラルネットワークモデルの中から最適なモデルを選択することです。この目標を達成するために検証データを採用した学習方法を、ここでは「検証を使用した学習」と呼びます。フォーカスモードツールとは異なり、High Detail モード (分類 (緑) High Detail モードと解析 (赤) High Detail モード) は検証を使用した学習を行うため、検証損失をモニタしてネットワーク学習を制御できます。学習中に 1/8 エポックが終了するたび、ニューラルネットワークでは以前に設定された検証セットから損失値を計算します。
検証損失は、分類 (分類 (緑) High Detail モード) またはセグメンテーション (解析 (赤) High Detail モード) の精度における、学習済みネットワークのパフォーマンスを表します。一般的に損失が小さいほどネットワークが優れていることを意味します。したがって、この値は 0 に近いほど優れていることになります。解析 (赤) High Detail モードの検証損失は、「良好」または「欠陥」のバイナリ分類であるセグメンテーションを各ピクセルで実行するときに、ピクセルごとに計算されます。ただし、ネットワークのパフォーマンスが実際にどの程度優れているかを完全に把握するには、学習済みネットワークがいくつかのデータ (テストデータ) でオーバーフィットをどの程度防ぐかをテストする必要があります。
検証損失 (0 ~ 1)
-
1 - IOU
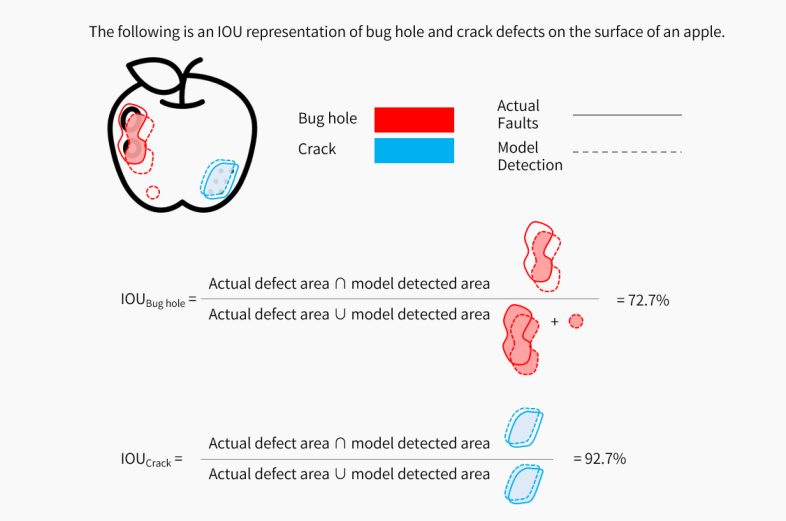
IOU (単位: %)
-
IOU とは、予測される領域がその教師データとどの程度等しいかを測定する Intersection over Union を指します。IOU の計算式:
(教師データ領域 ∩ 予測される領域) / (教師データ領域 ∪ 予測される領域)