Train Neural Network
After all views are correctly labeled and split into the training images and the test images, neural network training is performed in the following general way:
- Configure tool parameters and start the training. Train the tool by pressing the Brain icon. Each image in the image set that is being used for training (defined in the Training Set dialog) is sampled across its full extent, using the specified Feature Size when the architecture is Focused.
- The resulting samples are provided as input to the VisionPro Deep Learning deep neural network.
- For each sample, the neural network produces a specific response (depending on the tool type), and this response is compared with the image labeling associated with the sample's location in the training image.
- The internal weights within the network are repeatedly adjusted as the samples are processed and reprocessed. The network training system continually adjusts the network weights with a goal of reducing the error (difference or discrepancy) between the network's response and the labeling provided by the user.
- This overall process is repeated many times, until every sample from every training image has been included at least the number of times specified by he Epoch Count parameter.
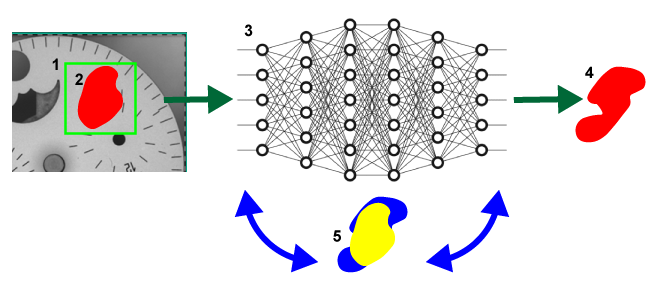
-
The sampling region.
-
The user-drawn, labeled defect region.
-
The neural network.
-
The response by the network.
-
The iterative process of adjusting the weights to reduce the discrepancy (in other words, error) between the labeled defect (in yellow) and the network response (in blue).
The specific characteristics of the neural network training vary somewhat depending on the type of tool being trained. The goal for Blue Read tool network training is to reduce the discrepancy between the actual character feature pose and identity, as defined by your labeling of the image, and the detected character pose and identity. The Blue Read tool uses the a similar approach to the Blue Locate tool, although less attention is paid to pose Mismatches.
One important difference that distinguishes Blue Read from other tools is that its neural network is an already trained (pre-trained) one for character recognition. So, it's not necessary to label multiple instances of each character, but the more labeled instances there are, the better the results will be during the training phase. Training will increase the accuracy of the tool. The more you train, the more you tune your neural network towards your particular training set. The tool starts with a very generalized model, and every time you train, the tool is going to key in more and more to what you have in your training set. So, if your training set isn't a very good representation of what you'll encounter at run time, you would be better off to minimize the amount of training you'll do.
If you have labeled everything, and the labeled features represent the expected appearances (and preferably involve the instances of each character), training will improve the performance of the tool. However, if you have an unrepresentative set of images (for example, characters on a different background or a slant that isn't expected at runtime), training may narrow the performance to the unrepresentative set of characters, so training isn't advised. To have a successful implementation of the tool, you need to have a set of images that contain the full range of expected variations of the characters at runtime.
-
Sampling Region and Sampling Parameter
Blue Read samples pixels with the sampler that is tied to a sampling region defined by the users with Sampling Parameters and thus it requires configuring the sampling parameters to determine a sampling region before start its training. If a sampling region does not include any feature pixel, then the network should produce no response.
-
Training with Validation
Blue Read does not support the training with the validation scheme and so it doesn't have the validation data set nor require configuring the validation set in Tool Parameters. The purpose of adopting the validation data is to validate each trained neural network and with the results from this validation data for selecting the most performing and stable neural network with the given training set.
Configure Tool Parameters
After a tool has been added, the tool's parameters can be accessed to fine-tune the tool's performance prior to training, and how the tool will process images during runtime operation. The VisionPro Deep Learning tool parameters adjust the how the neural network model is trained, and also how the tool processes statistical results.For the majority of applications, the most common Tool Parameters to be adjusted are the following:
- Feature Size
- Training Set
- Perturbation
- Sampling Density
Architecture Parameter
The Architecture parameters selects the type of neural network model that will be used. This option is useful when you want to get more accurate results, at the expense of increased training and processing times. The High Detail and High Detail Quick architecture setting configures the tool to consider the entire image equally, while the Focused architecture setting is selective, focusing on the parts of the image with useful information. Due to this focus, the network can miss information, especially when the image has important details everywhere.
Network Model Parameter
The Network Model parameter allows you to reduce the size of the trained tool network, which will reduce the amount of time required for processing. The default value (Large) retains the standard tool behavior and performance. The two other values, Small and Medium, provide progressively faster run time execution.
Selecting a value other than Large might result in different tool results. These differences are typically minor, however, when using this option, you will need to validate tool performance using your own labeled data.
Training Parameters
The Training tool parameters control the training process. If any changes are made to the Training tool parameters after the tool has been trained, it will invalidate the training and necessitate that the tool be retrained.
| Parameter | Description |
|---|---|
|
Training Set |
Launches the Training Set dialog, which is used to specify the sample sets and percentage of labeled images to randomly select as training samples for the neural network each time a new training is initiated. |
|
Epoch Count |
Specifies the number of optimization iterations done during training. This setting can be reduced when your application has limited complexity, or if a lower quality model may be useful when testing different parameter settings. An epoch is the term for passing your entire Training Set into the neural network. The tools typically need to see the training image set data somewhere on the order of 50 times (and is in the Fine Tuning area), which is the default setting, and is typically sufficient for most standard applications. Choosing to use fewer epochs could result in the neural network being stuck in learning, or unable to accurately solve the problem, while too many epochs could result in overfitting (aka over-training) the results (in other words, it will learn only the trained images, and anything outside of the trained images will be considered invalid). It is important to train the network to the point where it is generalized off of your training image set. If you increase the epochs too much, you run the risk of over-training and overfitting the training image set data. Tip:
|
Training Parameter Details: Epoch Count
Epoch Count parameter lets you control how much network refinement is performed. As described in the Neural Network Training topic, the training process repeatedly processes input samples through the network, compares the network result with the user-supplied labeling, then adjusts the network weights with a goal of reducing this error. Because of the large number of network nodes (and thus weights), this process can be repeated almost indefinitely, with each iteration resulting in a progressively smaller improvement in the error. Increasing the Epoch Count parameter setting increases the number of iterations of training that are performed. This will reduce the network error on the training images at the cost of requiring more time for training.
It is important to keep in mind, however, that the goal for training the network is to perform accurately on all images, not just those used for training. As the epoch count is increased, the network will tend to experience overfitting (Terminology), where the error on untrained images increases at the same time that the error on trained images decreases. For this reason, you should carefully monitor the network performance on all images as you adjust the epoch count. You have to choose an optimal Epoch for your dataset because its optimal value is different by dataset, particularly the statistical diversity of your dataset.
Perturbation Parameters
The VisionPro Deep Learning neural network can only be trained to learn the features in images that it actually sees. In an ideal world, your training image set would include a representative set of images that expressed all of the normal image and part variations. In most cases, however, training needs to be performed with an unrepresentative image set. In particular, image sets are often collected over a short period of time, so normal part and lighting variations over time, as well as changes or adjustments to the optical or extrinsic characteristics of the camera are not reflected.
The VisionPro Deep Learning training system allows you to augment the image set by specifying the types of appearance variation that you expect during operation, through the use of the Perturbation parameters, such as the following:
- Luminance
- Contrast
- Rotation
- Scale
The Perturbation parameters allow the VisionPro Deep Learning tools to artificially generate images to be trained on, improving results for applications with high amounts of variance. These parameters are common across all of the tools. The Perturbation parameters can also be combined. This allows for the generation of more complex images by using the parameters separately, as well as in conjunction.
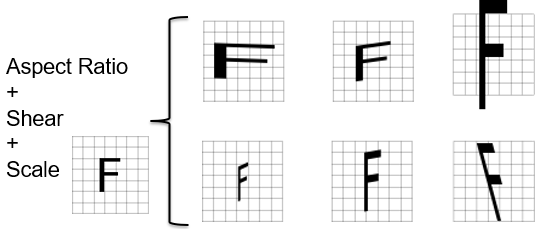
For each perturbation type, you can specify the range for the perturbation.
| Parameter | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
|
Rotation
|
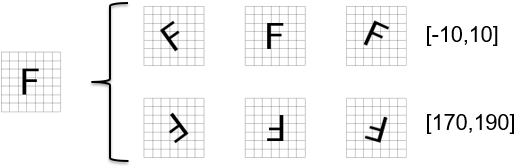
Specifies the possible orientations, defining a piece-wise uniform distribution from which a perturbing rotation angle is drawn (if set to [0°, 0°], no rotational perturbation will be used). For example, with the following settings, [-10°, 10°] or [170°, 190°], the part can be detected between -10 and 10 degrees, or between 170 and 190 degrees. These types of settings are particularly useful if your part can be orientated with a regular orientation, or upside down with a small variation in its angle, but never in between.
|
||||||||
|
Scale
|
Specifies the normal distribution around 1 from which a perturbing scaling factor is drawn (if set to 0%, it will not be applied). For example, a Scale setting of 100%, provides images half the original size to double the original (0.5x to 2.0x the original).
|
||||||||
|
Aspect-Ratio
|
Specifies the normal distribution around 1 from which a perturbing aspect-ratio factor is drawn (if set to 0%, it will not be applied). |
||||||||
|
Shear
|
Specifies the normal distribution around 1 from which a perturbing shearing factor is drawn (if set to 0%, it will not be applied). |
||||||||
|
Flip
|
Specifies whether to randomly flip the image during sampling in the horizontal, vertical or both directions. This is useful if the object or surface exhibits the corresponding symmetries. This setting can help to highly increase the quantity of training data.
|
||||||||
|
Luminance
|
Specifies the normal distribution around 1 from which a perturbing luminance factor is drawn (if set to 0%, it will not be applied). |
||||||||
|
Contrast
|
Specifies the normal distribution around 1 from which a perturbing contrast factor is drawn (if set to 0%, it will not be applied). |
||||||||
|
Invert Contrast
|
Specifies whether or not to randomly invert the contrast in order to simulate contrast reversal in the training samples. Note: The Invert Contrast parameter is only available when Expert Mode is enabled.
|





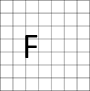


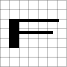


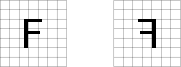
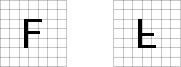




Recover Last Parameters: Restore Parameters
Restore Parameter button is designed for the easy turning back of tool parameter values to the values that you chose in the last training task. It remembers all values in Tool Parameters used in the last training session. So, if you changed any of its values and now want to revert this change, you can click it to roll back to the tool parameter values which are used in the last training. Note that it is disabled when the tool has never been trained or there were no changes from the initial set of tool parameter values.
The following steps explain how Restore Parameter works:
-
Restore Parameter button is always disabled when the current tool was not trained.
-
Once the current tool is trained, the checkpoint of parameter rollback is set to the values in Tool Parameters of the last training session. At this point, if you change any value in Tool Parameters, the button is enabled.
-
Click Restore Parameter button and it reverts the changed value to the value of the checkpoint.
-
If you train the current tool again, with some changes in Tool Parameters, then the checkpoint of parameter rollback is updated to the changed parameter values. Again, the button is disabled unless you make another change for the values in Tool Parameters.
-
If you make another change and click Restore Parameter button again, it reverts the changed value into the value of the updated checkpoint.
Note that if you re-process a trained tool after changing the values in Processing Parameters, the checkpoint of parameter rollback is not updated, and thus Restore Parameter remains enabled. The checkpoint is updated only after the training of a tool is completed.
|
Disabled |
Enabled |
Irreversible parameters that changing these parameters will reset the tool
Network Model, Exclusive, Feature Size, Masking Mode, Color, Centered, Scaled, Scaled Mode (Uniform/Non-uniform), Legacy Mode, Oriented, Detail
Irreversible parameters that these parameters are not invertible in nature
Low Precision, Simple Regions
Other irreversible parameters
Training Set, Heatmap in Green Classify High Detail and Green Classify High Detail Quick(This parameter does not affect the prediction performance)
Overlay parameter in Masking Mode in Blue Read
Control Neural Network Training
The training of Blue Read can be controlled by configuring the tool parameters and the training set.
Training Set
The largest single determinant affecting the network training phase is the composition of the Training Set. The best method for controlling the network training phase is to construct a proper training set for your tool. In this way, you can separate images/views into categories that allow you to determine if your tool is generalizing your images/views properly.