[OCV/OCRフォントの登録] ダイアログ
[OCV/OCR フォントの登録] ダイアログを使用すると、フォントの文字モデルを追加、修正、または削除して、ユーザ登録フォントを作成することができます。このユーザ登録フォントは、TrainFont 関数に格納されます。このフォントは、ReadText 関数によるテキストの文字認識、または VerifyText 関数によるテキストの文字照合の際にそれぞれ使用されます。
- TrainFont、ReadText、VerifyText の各関数は、In-Sight ファームウェア 4.x.x を搭載した In-Sight ビジョンシステムのみで使用可能です。In-Sight ファームウェア 5.1.0 以上を実行している In-Sight ビジョンシステムでは使用できません。モデル一覧およびサポートされているファームウェアバージョンについては、「ファームウェアバージョン」を参照してください。
- レガシー関数である ReadText、TrainFont および VerifyText 関数の代わりに、OCRMax 関数を使用することを推奨します。OCRMax 関数には拡張性能機能が搭載されています。
- フォントの各文字には最大 8 つのインスタンスを登録することができます。より多くの文字インスタンスを追加することによって、フォント内の対応する文字モデルの変形許容値が向上します。
- フォントには最大 255 種類の文字モデルとともに特定の文字の 8 インスタンスを含むことができます。各モデルに文字ラベルが 1 つずつ割り当てられます。これらの制限のいずれかを超過した場合、In-Sight センサでは超過した文字モデルはすべて無視され、追加されません。
- 文字形状の変動が小さい文字照合/認識アプリケーションでは、必要なインスタンスが 1 つで済む場合があります。文字形状の変動に対して大きな許容値が必要な場合には、必要な文字インスタンスの数も増加します。
- ユーザインタフェースの言語が中国語または韓国語以外の値に設定されている場合、ラベルに中国語や韓国語の文字が含まれている文字インスタンスでは、[削除] や [ラベル変更] を含む OCV/OCR 操作は機能しません。ラベルに含まれている文字列に対応した言語にユーザインタフェースを変更してから、もう一度操作をやり直すか、またはラベルに英語の文字を使用してください。
- 漢字などのマルチバイト文字のモデル名はサポートされていません。マルチバイト文字は登録できますが、文字モデルに指定する名前はシングルバイトの名前にする必要があります。
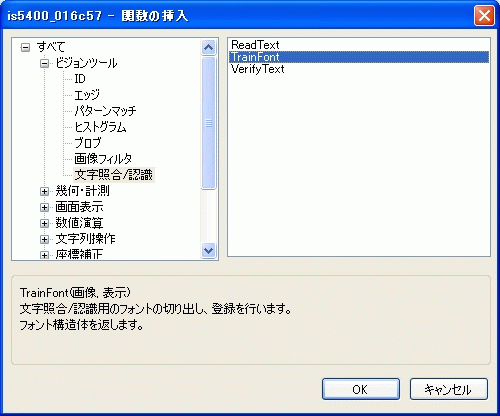
[フォントの登録] ダイアログを開く
- 空白のセルを右クリックして [関数の挿入] を選択し、[関数の挿入] ダイアログを開きます。
- [関数の挿入] ダイアログの左側で、ツールカテゴリの [ビジョンツール] リストを展開します。
- [文字照合/認識] ツールカテゴリを選択します。
-
関数リストから TrainFont 関数を選択して、[OK] ボタンを押すか、関数名をダブルクリックします。
-
[フォントの登録] ダイアログが表示されます。
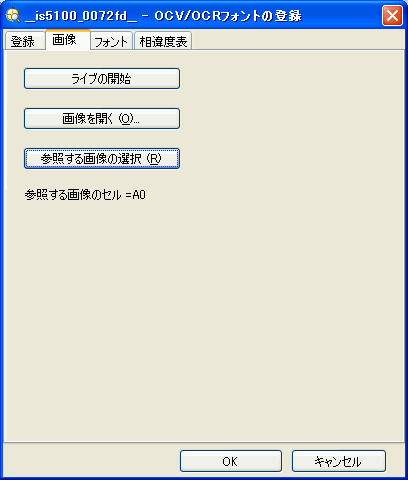
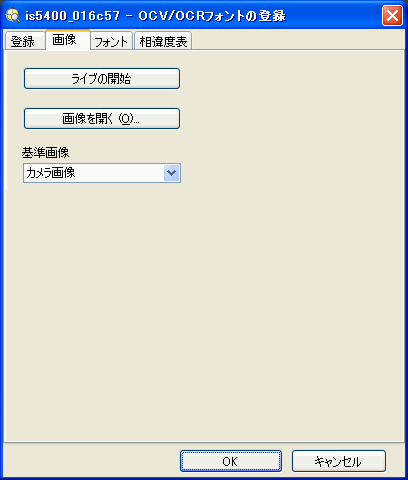
[画像] タブ
[画像] タブでは、フォントの登録に使用する画像を取得することができます。目的の画像がアクティブな画像として既にロードされている場合は、次のセクションに進んでください。それ以外の場合は、次のいずれかの方法で、有効な画像を得ることができます。
- [ライブの開始]: センサをライブ表示モードにして、リアルタイム画像を表示します。必要な画像を取り込んだら、[ライブの停止] をクリックします。
- [画像を開く]: [開く] ダイアログを表示します。このダイアログを使用して、In-Sight センサ、ローカル PC、またはネットワーク接続された PC から画像をロードできます。
- [参照する画像の選択]: セル選択モードに切り替わり、アクティブジョブの
 構造体を参照できるようになります(スプレッドシートビューのみ)。
構造体を参照できるようになります(スプレッドシートビューのみ)。 -
[基準画像]: ツールが検査を行うために使用する画像を定義します。画像フィルタリングツール、Color Blob または Color Blobs (1 ~ 10) Location Tool、Color Blob Area または Color Blobs Areas (1 ~ 10) Measurement Tool、Color Blobs Counting Tool の出力画像、またはフィルタされていない取り込み画像 (デフォルト設定) のいずれかから選択します。(EasyBuilder ビューのみ)
スプレッドシートビュー:
EasyBuilder ビュー:
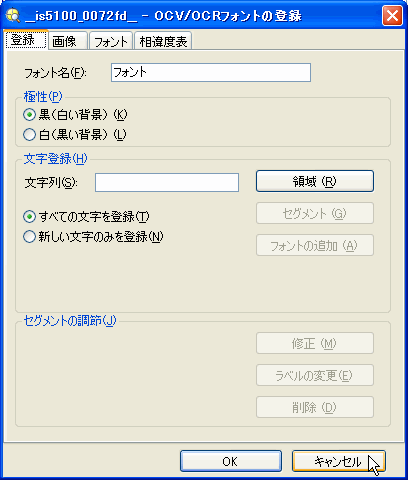
[登録] タブ
[登録] タブでは、画像から文字を抽出して、各文字のモデルを作成することができます。
-
わかりやすいフォント名を選択します。
 データ構造体が含まれている場合に便利です。
データ構造体が含まれている場合に便利です。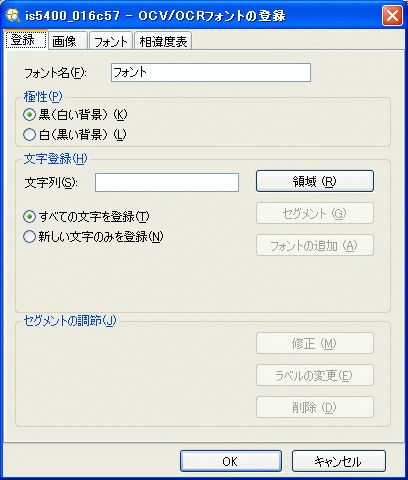
-
登録する文字が周囲の背景よりも明るい場合は、[極性] として [白 (黒い背景)] を選択します。登録する文字が周囲の背景よりも暗い場合は、[黒 (白い背景)] を選択します。
注 : [フォントの追加] ボタンをクリックする前に、登録する文字の極性が正しく設定されていることを確認してください。文字モデルをフォントに追加した後に極性を変更することはできません。 - デフォルトでは、1 つ以上の文字インスタンスがフォントに既に存在していたとしても、すべての文字がフォントに追加されます。新しい文字のみをフォントに追加する場合は、[新しい文字のみを登録] をクリックします。
-
登録する文字を含む最初のテキスト行と一致する [文字列] を入力します。
- [領域] ボタンをクリックします。
-
登録する文字が囲まれるように、対話型グラフィックスの配置とサイズを指定してください。

- 領域内でダブルクリックすると、変更が確定します。
- [セグメント] ボタンをクリックします。指定された [文字列] に基づいて、[領域] 内の文字が個々の文字インスタンスに分割されます。
- 正しくセグメント化されていない文字が残っている場合は、[変更] ボタンをクリックして、個々の文字インスタンスの対話型グラフィックス領域を微調整します。不正確なセグメントを調整するには、セグメントの領域をクリックして、文字が適切に囲まれるように、この領域を配置し、サイズを変更します。すべてのセグメントが文字の周りに正しく配置されるまで、この手順を繰り返します。
- 文字のいずれかが正しくラベル付けされていない場合は、まず、指定された [文字列] が画像内の文字と一致することを確認します。文字列が正しい場合は、[ラベルの変更] ボタンをクリックします。誤ったラベルのついた文字をダブルクリックして [ラベルの変更] ダイアログを開きます。正しいラベルを入力して、[OK] をクリックします。
- 必要に応じて、[削除] ボタンをクリックし、セグメントを個別に削除します。
-
すべての文字が正しくセグメント化、およびラベル付けされたら、[フォントの追加] ボタンをクリックします。選択したテキスト行内の各文字のインスタンスが、現在のフォントに追加されます。登録する文字が含まれているテキスト行それぞれについて、この手順を繰り返します。
注 :- 文字をフォントに追加した後で、セグメントの修正、ラベル変更、削除を行うことはできません。
- フォント登録にあたっては 1 文字ずつ追加せず、一度に複数の文字を登録するようにしてください。1 文字だけを追加した場合、文字列内の文字を読み取るときに重要な間隔情報がないことになります。1 文字だけを登録する必要がある場合は、次のような手順で登録してください。
- 文字をセグメントした後、[修正] ボタンを押します。
文字の両側にスペースができるように、文字ボックスの幅を調整します。図に示されているように、文字ボックスの左右の境界線が登録文字と隣の文字との中間になるようにします。

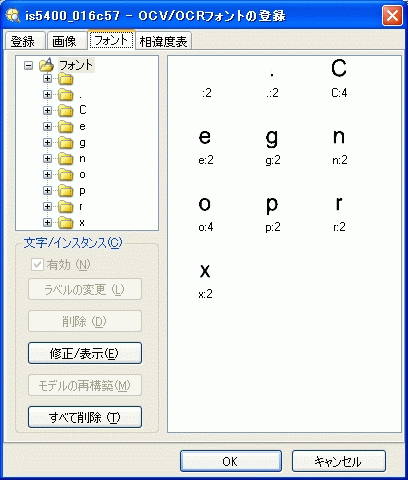
[フォント] タブ
[フォント] タブは、登録したフォントに含まれる文字モデルの表示および編集に使用します。ユーザフォントにはいくつかの文字モデルが含まれています。いくつかのモデル (「C」、「o」など) は、複数の文字インスタンスで構成されています。スペースや句読点を含むすべての文字が切り出され、文字モデルとして登録されます。ここで、すべての文字モデルを参照して、特定の文字モデルまたは文字インスタンスの削除、編集、名前変更、または有効化/無効化を行うことが可能です。[フォント] ツリーのルートレベル ![]() を選択すると、各文字のモデルが表示されます。[フォント] ツリーの文字フォルダを選択すると、コンポジット文字モデル (* で示されます) と、モデルの作成に使用された登録文字のインスタンス (0 から始まるインデックス番号で示されます) が表示されます。登録文字の各インスタンスは、個別のサブフォルダに保存されます。
を選択すると、各文字のモデルが表示されます。[フォント] ツリーの文字フォルダを選択すると、コンポジット文字モデル (* で示されます) と、モデルの作成に使用された登録文字のインスタンス (0 から始まるインデックス番号で示されます) が表示されます。登録文字の各インスタンスは、個別のサブフォルダに保存されます。
-
[有効] チェックボックスは、このフォントで文字モデルが使用されるかどうか、また各文字のどのインスタンスがモデルの構築に使用されるかを指定します。デフォルトでは、このチェックボックスはすべての文字モデルについて有効化されています。文字モデル、または文字インスタンスを無効化するには、対象のモデルまたはインスタンスをハイライトし、チェックボックスを OFF にします。
注 :- ある文字モデルの [有効] チェックボックスがオフになると、その文字のすべてのインスタンスが無効になります。
- 無効にされた文字インスタンスは、文字照合/認識の実行時には文字モデルとして利用されません。
- 文字モデル、または文字インスタンスが正しくない場合は、誤ったラベルのついたモデルまたはインスタンスをハイライトし、[ラベルの変更] ボタンをクリックして、ラベルを訂正します。文字モデルを選択している場合、そのすべての文字インスタンスの名前を変更します。1 つの文字インスタンスが選択されている場合、このインスタンスのラベルのみが変更され、対応する文字モデルフォルダに移動されます。
-
文字モデル、または文字モデルから文字インスタンスを個別に削除するには、削除対象をハイライトし、[削除] ボタンをクリックします。
注 : 文字モデルを削除すると、その文字のすべての登録インスタンスが消去され、復元することはできません。 -
選択した文字モデルや文字インスタンスのクローズアップを表示するには、[修正/表示] ボタンをクリックしてフォントエディタを開始します。文字モデルは編集できます。文字インスタンスは表示のみが可能です。編集された文字モデルには、[フォント] ツリーのフォルダの横に「*」が表示されます。
注 : フォントエディタはむやみに使用しないでください。低品質なサンプルフォントを加工して登録するよりも、高品質なサンプルフォントで取り込んだ方が良い結果が得られます。 - 文字モデルに対して手動で行われた編集に満足できない場合は、[モデルの再構築] ボタンをクリックして、選択したフォント文字を再構築し、フォントエディタを使用して手動で行った編集をすべて削除することができます。
- フォントからすべての文字モデルとインスタンスを削除して最初からもう一度やり直すには、[すべて削除] ボタンをクリックします。
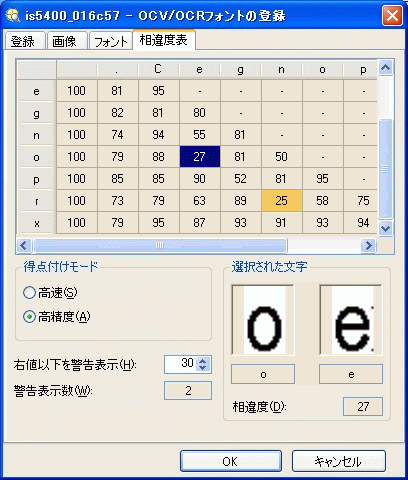
[相違度表] タブ
[相違度表] タブには、各文字モデルとほかのすべてのモデルを比較した一覧が表示され、その中で選択した 2 つの文字の違いが点数で表示されます。行見出しと列見出しは、文字が登録されたときに定義された文字ラベルを示します。2 つの文字の相違度が大きければ大きいほど、検査中にこれらの文字が誤認識される可能性が低くなります。このデータは、パフォーマンスに悪影響を与える可能性のある、登録フォントの弱点を示すため便利です。下の例では、「e」と「C」の文字モデルの相違度は 95 ときわめて高くなっています。これは、現在のフォントで、これら 2 つの文字が誤認識される可能性が非常に低いことを示しています。一方、「o」と「e」の文字モデルの相違度は 27 にすぎません。したがって、これら 2 つの文字は誤認識されやすいことを意味します。
-
表示する [得点付けモード] 相違度表として、[高速] または [高精度] を指定します。前述のように、相違度が高いほど、選択した 2 つの文字が検査中に誤認識される可能性が低くなります。
ヒント : 相違度表に表示される得点は、ReadText 関数や VerifyText 関数の [読み取りモード] パラメータで [高速] と [高精度] のどちらを選択すべきかを判断する際の目安となります。 - [右値以下を警告表示] フィールドに値を入力します。文字モデルの比較得点がこの相違値以下の場合は、すべて黄色でハイライトされます。これは、誤認識されやすい文字モデルのペアを示します。ハイライトする得点のしきい値を増減するには、↑/↓ボタンをクリックするか、値を入力します。[警告表示数] が更新され、得点が指定値以下である文字モデル比較の個数が表示されます。この個数は、[右値以下を警告表示] で指定したしきい値によって変化します。
-
文字モデルを隣り合わせに表示するには、黄色でハイライトされたペアをそれぞれクリックします。[選択された文字] フィールドには、比較中の各文字のモデルが表示されます。[相違度] には、選択した文字の「類似していない度合い」が表示されます。この比較によって、文字モデルが正しく登録されていなかったこと、文字モデルが登録されたときの画像状態がよくなかったこと、使用された文字の品質が低かったことなどが明らかになることがあります。
注 : [フォント] タブで無効にされている文字は、相違度表には表示されません。