Interpret Results
Once it was trained and processed, the results of a tool are calculated against all views. But, the results should only be reviewed on the test set for correct evaluation of a tool.
Test Set: The Images for Result Evaluation
Statistical measurements within VisionPro Deep Learning are used to evaluate the trained neural network's performance. Within the deep learning paradigm, evaluation refers to the process of evaluating a trained neural network model against a test data (the data labeled by the user but not used in training). So, if you want to determine availability and performance of a neural network model through statistical metrics, these metrics must be calculated only on the test data.
It is important to understand that after training of your neural network model, which means your tool (Blue Locate/Read, Green Classify, or Red Analyze), if you want to check out how the model is well trained, you are not allowed to test the model against the data used for training this model. The training data cannot be employed in the evaluation of a trained model because the model was already fitted to this data during training, to make the best performance given the training data set. So, this data cannot tell how the model generalizes well enough and also desirably performs when it meets unseen, fresh data.
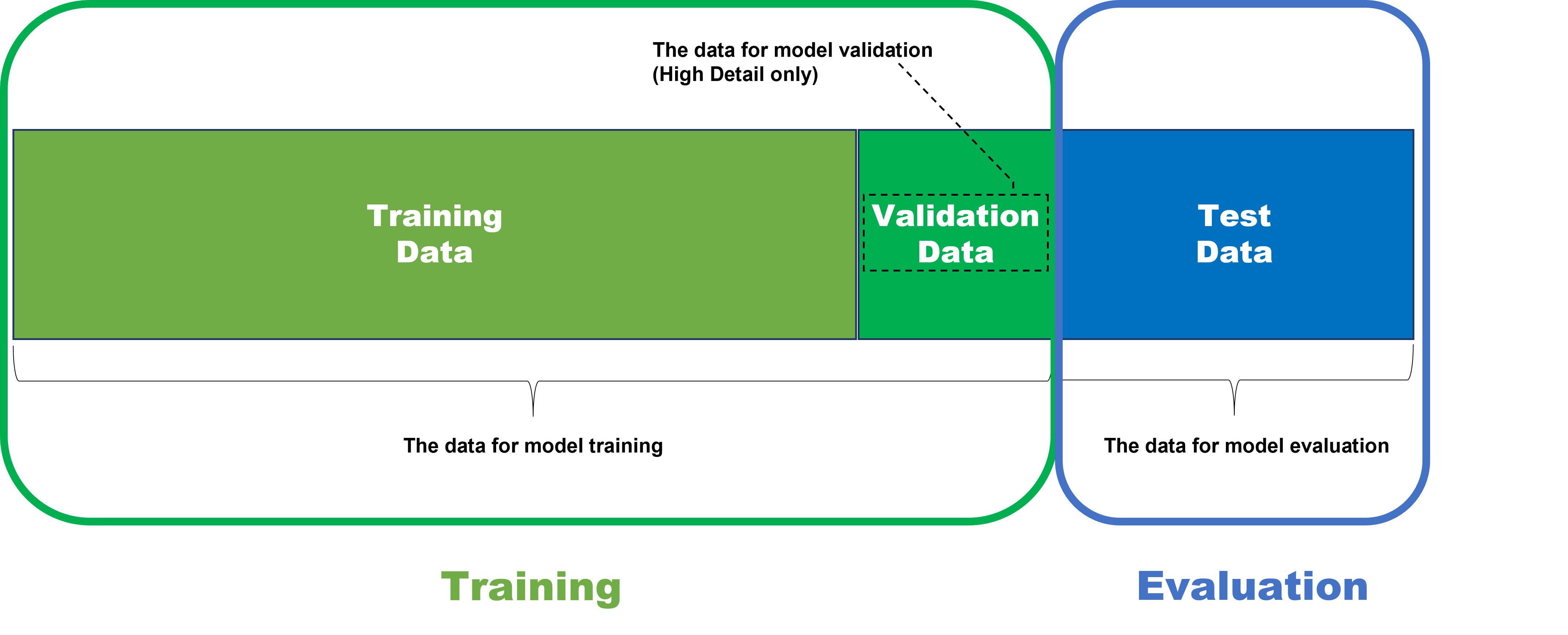
Therefore, to test the model's availability and performance fairly and correctly, the model should be applied to the data that it has never seen before including its training phase. That is why the data for model evaluation is called test data set.
Database Overview
The Database Overview pane provides information about the images and views used for training, and access to the Statistics output by the Cognex Deep Learning Tools. This pane changes its display, depending on the tool selected.
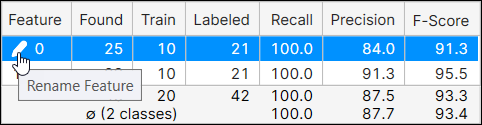
You can rename features by clicking the name, and then pressing the pencil icon to launch the Rename Feature dialog.
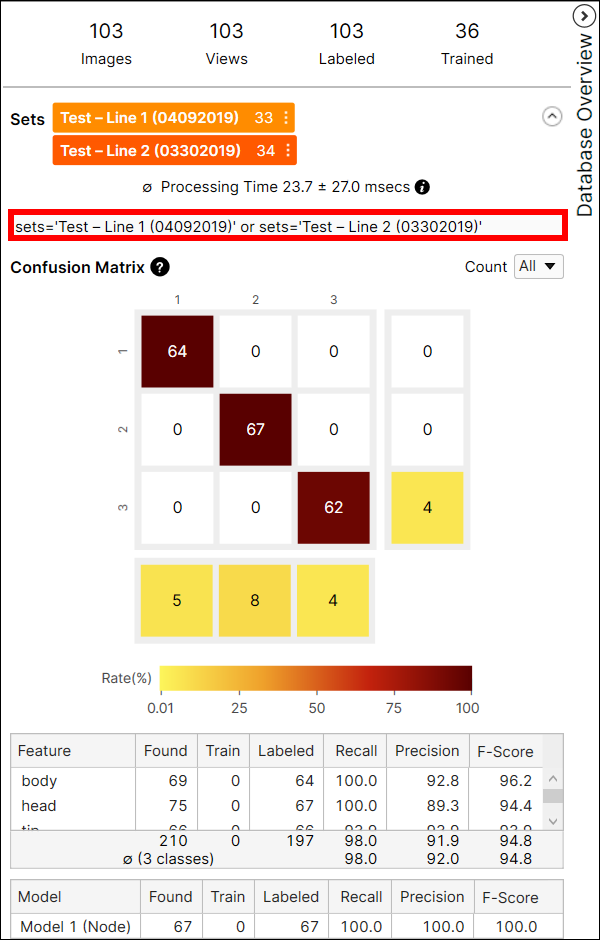
While in Expert Mode, you can utilize the Filter field to separate images/views, and perform statistical analysis on just those images/views. See Display Filters and Filters for information on the syntax to filter images/views, and the Testing Image Sample Set topic for more information on possible usages of the filter.
Processing Time
Individual tool processing time is displayed in the Database Overview, as shown below:
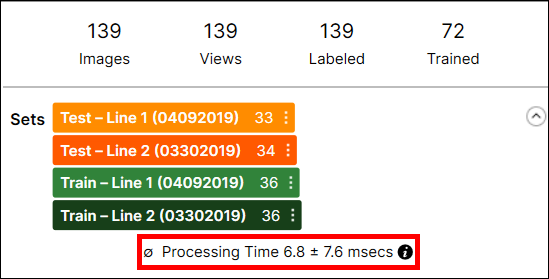
Processing Time is the average processing time per image in the last processing task, and it is the sum of the processing time and the post-processing time. The processing time for a stream containing multiple tools is not available through the VisionPro Deep Learning GUI, and you cannot estimate it by summing the tool execution time of the tools in the stream because the processing time includes the time required to prepare and transmit view information between tools.
Confusion Matrix
Like other tools, the Blue Read displays statistics for all labeled images.
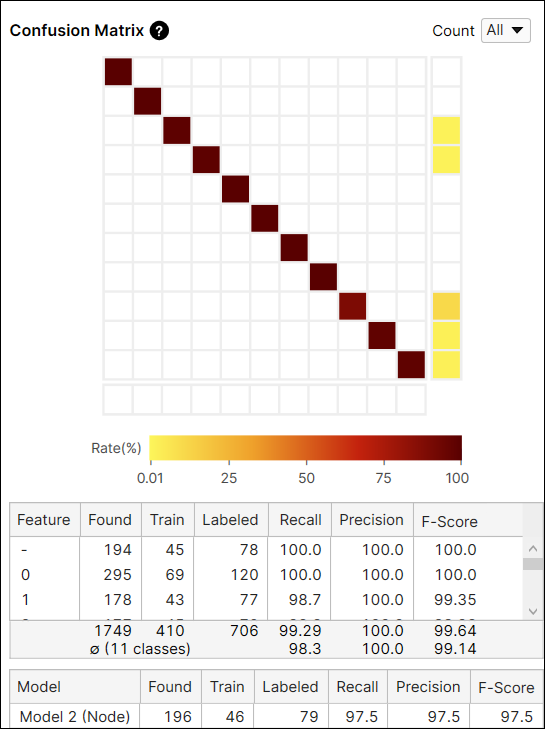
The Confusion Matrix is a visual representation of the ground truth versus the tool's predictions. The Confusion Matrix displayed with the Blue Read tool is a graphical representation of the Recall and Precision scores. Each row of the confusion matrix stands for the number of character features that are labeled by user, which are the ground truths, and each column of the confusion matrix stands for the number of character features that are predicted by the tool, which are the markings. If you click each cell at the Confusion Matrix on Database Overview, the corresponding item (views) in each cell of the table will be displayed on the View Browser.
The color of a confusion matrix cell stands for the ratio of the number of predicted features (the value of a cell) to the total number of labeled features (the row sum). The darker color means the higher ratio and the lighter means the opposite.
For example, the color of the cell at the index (2,2) is brown because among the features whose label is 'shaft' the number of features predicted as 'shaft' is 127 and it accounts for 90.7% (127/140) of the features whose label is 'shaft.'
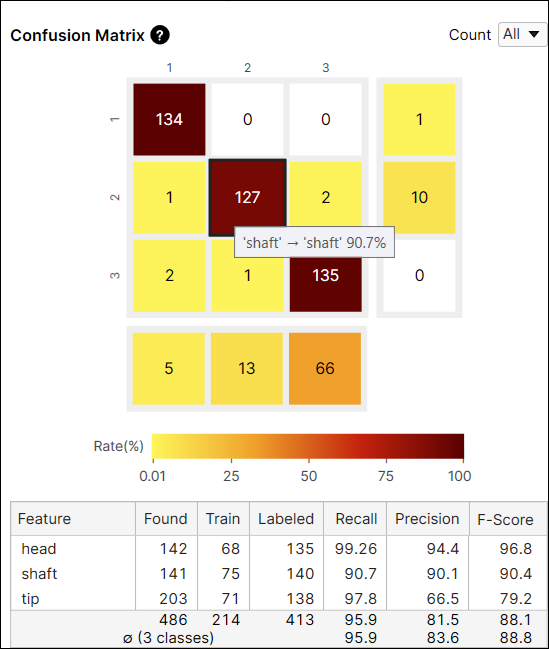
For another example, the color of the cell at the index (2,3) is yellow because among the features whose label is 'shaft' the number of features predicted as 'tip' is 2. The number of features predicted as 'tip' accounts for 1.4% (2/140) of the features whose label is 'shaft.'
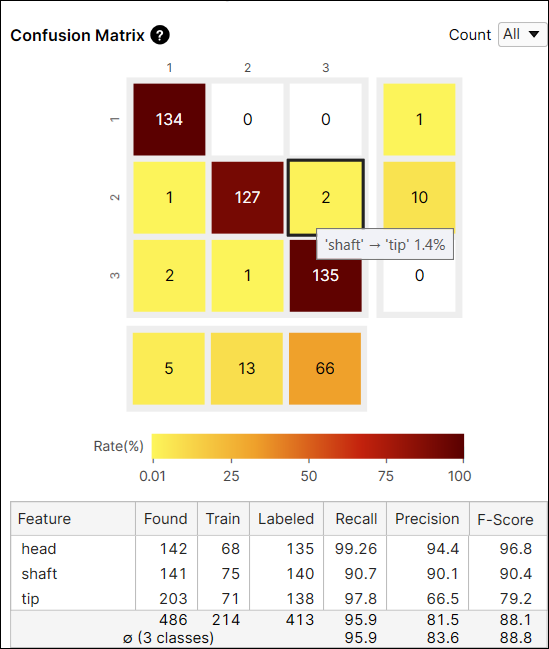
It is generally recommended that the darker cells are placed at the diagonal indices of a confusion matrix because it represents the desirable results.
|
|
|
|
Good Performance |
Poor Performance |
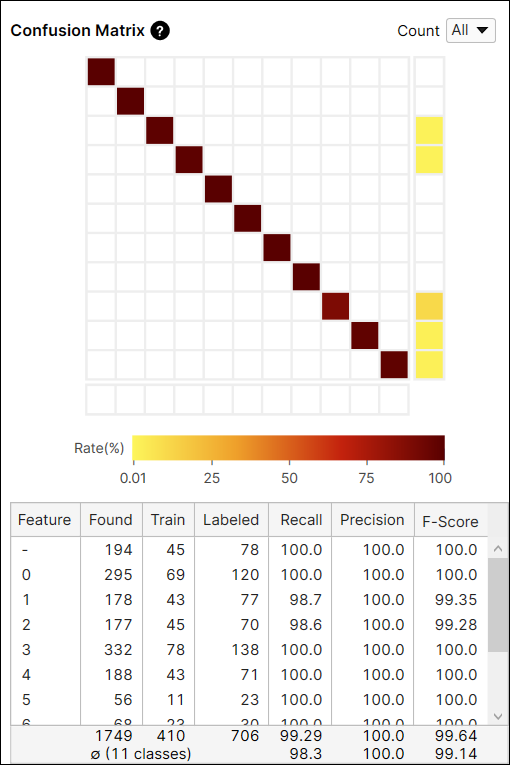
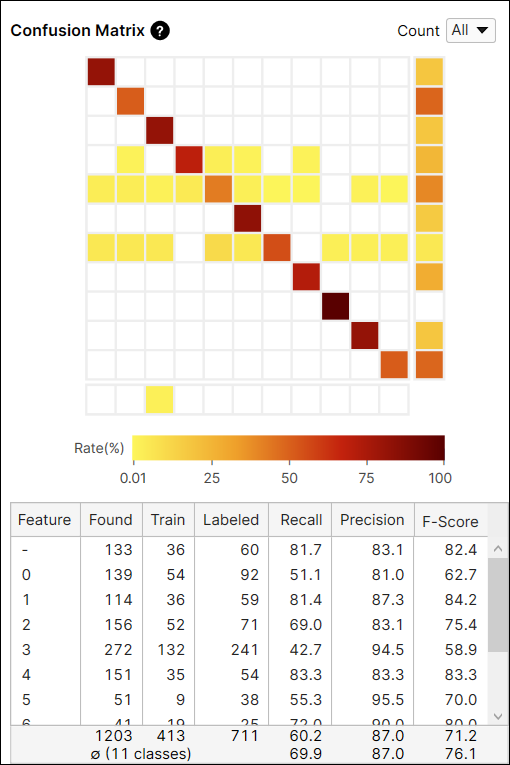
Confusion Matrix Calculation: All Views vs Untrained Views
The Count option in the Confusion Matrix provides the result of the current tool calculated from all views (All), or only from the views that are not included in the training set (Untrained Views). You can switch the results between the one generated from every view including training and test images, and only from the untrained views which are the test images.
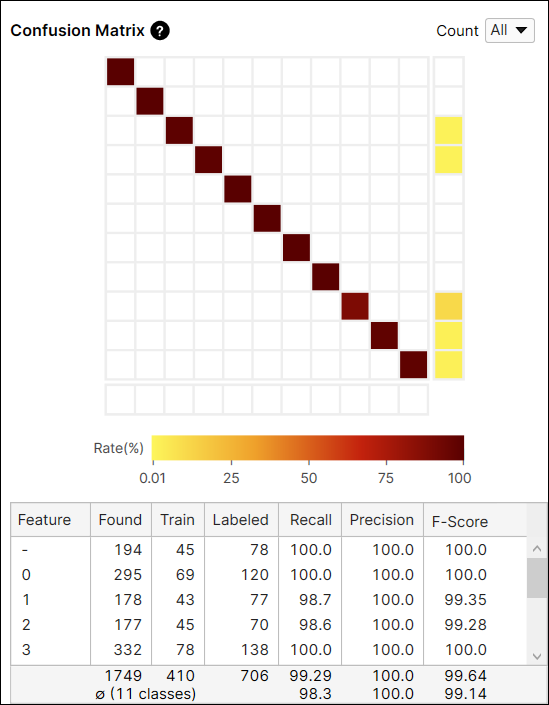
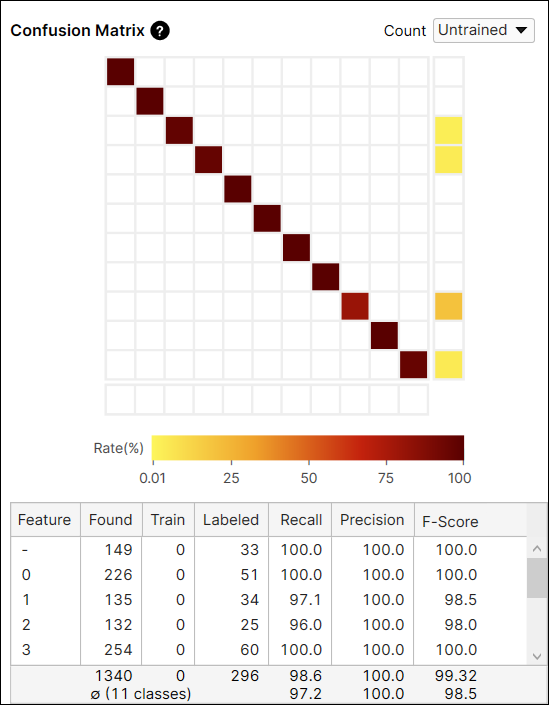
Result Metrics
In the Database Overview of Blue Read, there are 2 tables and each shows different results. The one above displays the result metrics for each feature in the images, and the other one below displays the result metrics for each model in the images. Here, the model stands for one of the Node, String, and Regex Model, not a neural network model of the Blue Read.
A "labeled model" is a model that is created (labeled) by users on views. In the processing step, Blue Read uses it to tell whether this model is found on a view or not. So, a "found model" is a model that is found on views by a trained Blue Read.
A found model is said to be a correct match (correctly marked model) if there is a labeled model in approximately the same position and if this found model has features that are close to the corresponding labeled features. The precision, recall, and F-score of model are calculated on this ground, and if there are multiple models in a view all model metrics are calculated by each model separately.
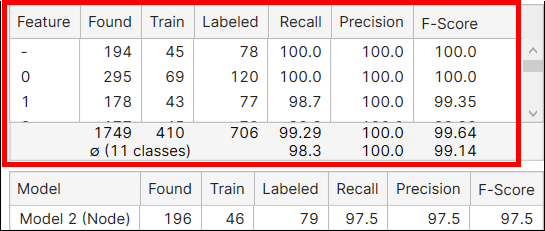
The Metrics for Features
| Table | Metrics | Description |
|---|---|---|
|
Feature |
The name of the feature. |
|
Found |
Tells how many feature objects of this feature class were found as the result of processing in all views. | |
|
Train |
Tells how many feature objects of this feature class were included (labeled) in the training set. | |
| Labeled | Tells how many feature objects of this feature class were included (labeled) in all views. | |
|
Recall |
How likely the tool is to find the labeled feature objects. Recall is the ability of a neural network to be able to find the desired feature where it actually exists. It is denoted as the number of correctly marked features divided by the number of labeled features. A high Recall score hopefully means that all labeled features are found. However, since recall does not take into account those that are incorrectly found, even with a high recall rate there still can be Type I errors. See Basic Concepts: False Positives, False Negatives for the details. | |
|
Precision |
How precisely the tool is to find a feature that has been labeled. Precision is the neural network’s ability to correctly place a feature. It is denoted as the number of correctly marked features over the total number of found features. Hopefully high precision means that all features found exist in the image. But high precision does not take into account all of the features that exist that were not found, so there still can be Type II errors, where we have many more features that have gone undetected. See Basic Concepts: False Positives, False Negatives for the details. | |
|
F-Score |
The harmonic mean of Precision and Recall. |
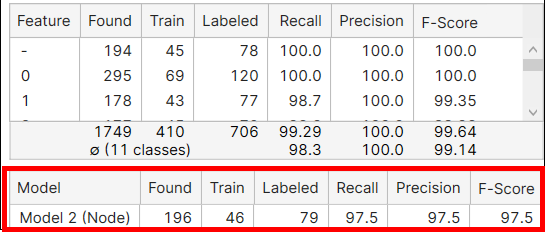
The Metrics for Models
| Table | Metrics | Description |
|---|---|---|
|
Model |
The name of the model. |
|
Found |
Tells how many models were found as the result of processing in all views. | |
|
Train |
Tells how many labeled models were included in the training set. | |
| Labeled | Tells how many labeled models were there in all views. | |
|
Recall |
How likely the tool is to find the labeled models. Recall is the ability of a neural network to be able to find the desired model where it actually exists. It is denoted as the number of correctly marked models divided by the number of labeled models. A high Recall score hopefully means that all labeled models are found. However, since recall does not take into account those that are incorrectly found, even with a high recall rate there still can be Type I errors. See Basic Concepts: False Positives, False Negatives for the details. | |
|
Precision |
How precisely the tool is to find a model that has been labeled. Precision is the neural network’s ability to correctly place a model. It is denoted as the number of correctly marked models over the total number of found models. Hopefully high precision means that all models found exist in the image. But high precision does not take into account many models that exist and but were not found, so there still can be Type II errors, where we have many more models that have gone undetected. See Basic Concepts: False Positives, False Negatives for the details. | |
|
F-Score |
The harmonic mean of Precision and Recall. |
Displaying Characters
The Blue Read tool allows you to display individual characters or strings in the Images display area, which allows you to efficiently search and find mislabeled features or misread characters in a large set of images. This can be done by double-clicking on the rows in the Features/Models tables in the Database Overview, which will automatically set the Display filter.
| Features | Models |
|---|---|
|
|
|

Basic Concepts: False Positives, False Negatives
In addition to the Statistical Results components, it is also important to understand how they affect False Positive and False Negative results.
Assume that there is an image inspection system that is built for capturing defects in images. If it captures one or more defects in an image, let's say the inspection result for that image is Positive, and if it captures no defect at all, the inspection result for that image is Negative. Then, the statistical results of the inspection task can be summarized into the followings:
-
False Positive (also known as a Type I Error)
-
An inspection system identifies a class of a character feature, but this character feature does not actually belong to that class.
-
-
False Negative (also known as a Type II Error)
-
An inspection system could not identify a class of a character feature, but this character feature should have been identified as belonging to that class.
-
Basic Concepts: Precision, Recall, F-Score
The False Positives and False Negatives are then summarized and represented again using the following metrics, which are the Precision and Recall, the statistical results used in all VisionPro Deep Learning tools.
- Precision
- A neural network with a low Precision typically fails to correctly grab the character features that should have been detected from given image data (test data), and so it returns many False Positive judgments (Type 1 Errors).
- A neural network with a high Precision typically succeeds to correctly grab the character features from given image data (test data), but if combined with low Recall, there is a possibility yet that there could be many False Negative judgments (Type 2 Errors)
- Recall
- A neural network with a low Recall typically fails to sufficiently grab the character features that should have been detected from given image data (test data), and so it returns many False Negative judgments (Type 2 Errors).
- A neural network with a high Recall typically succeeds to sufficiently grab the character features from given image data (test data), but if combined with low Precision, there is a possibility yet that there could be many False Positive judgments (Type 1 Errors)
To sum up,
- Precision - The percentage of detected character features that match the labeled character features.
- Recall - The percentage of detected character features that are correctly identified by the tool.
- F-Score - The harmonic mean of Recall and Precision.
The ideal statistical results for almost all inspection cases (there could be exceptional cases) includes high Precision and high Recall at the same time.
Precision, Recall, and F-Score for Blue Read
The Blue Read tool interprets Recall, Precision and F-Score as follows.
Precision
Precision is the percentage of detected features that are not in the training set and that correctly match the labeled features. For example, a Precision score of 90% for character “A” means that the neural network correctly identifies "A" against all other character features with a 90% chance given the test data.

|
|
|
|
Labeled Image |
Precision Results |


Recall
Recall is the percentage of labeled features that are not in the training set and that are correctly identified by the tool. For example, a Recall score of 90% for character “A” means that the neural network catches 90% of all appearances of " an “A" among the test data.


|
|
|
Labeled Image |
Recall Results |


F-Score
F-Score is the harmonic average between the Precision and Recall scores.
If possible, the use of a model may help filter out spurious matches. When using a model, a low Precision score can be less problematic.
|
|
|
|
No model |
Model in use |


Node Model Score
For Blue Read tool, a model score (model match score) is a combination of two things:
-
The average score of the features in this model
-
The "geometry score" based on the geometrical arrangement of the features in this model
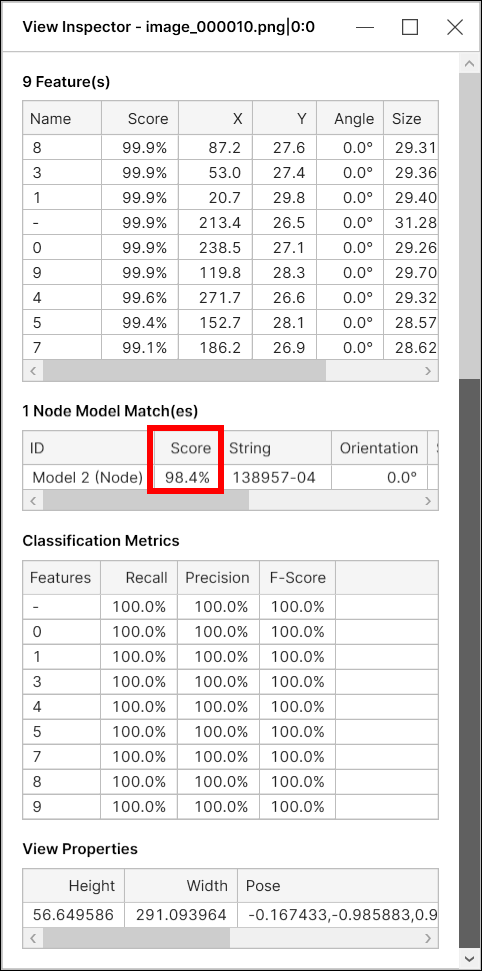
As the geometrical arrangement is included in the calculation of the overall model match score, the model score could be less than 100% even when all the features have a perfect score of 100%, given that the geometry score is less than 100%.
For a node model, the "geometry score" is simply a measure of how much the relative positions of the features differ from the relative positions of the nodes in the model. For example, with a node model with 3 nodes, given each feature of score 100%, the overall model match score will be slightly less than 100% because its geometry score will be less than 100% unless the spatial layout of the features exactly matches that of the model.
String Model Score
For Blue Read tool, a model score (model match score) is a combination of two things:
-
The average score of the features in this model
-
The "geometry score" based on the geometrical arrangement of the features in this model
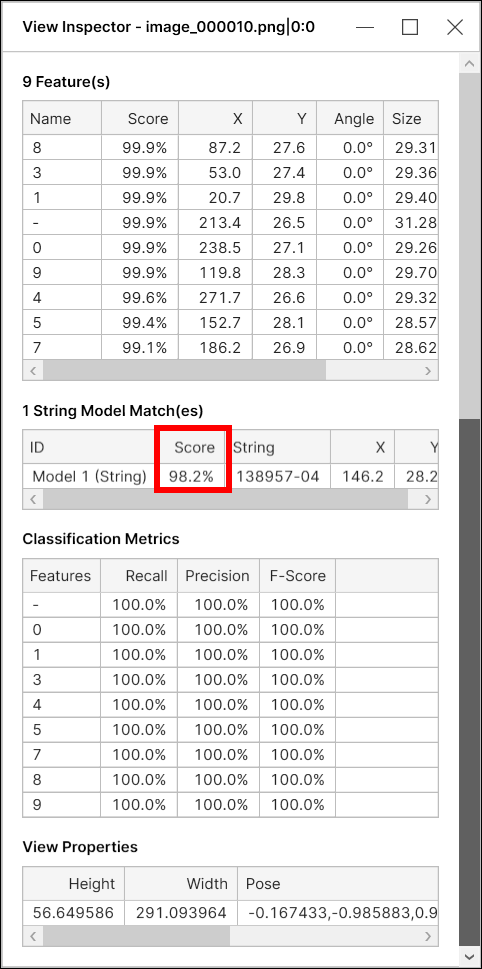
As the geometrical arrangement is included in the calculation of the overall model match score, the model score could be less than 100% even when all the features have a perfect score of 100%, given that the geometry score is less than 100%.
For the string model, the "geometry score" is based on a combination of:
-
how close the feature positions are to lying on a single line
-
how equally the characters are spaced
For example, with a string model, given 3 features of score 100%, the overall match score will be slightly less than 100% as the geometry score of this model is less than 100%. The geometry score will always be less than 100% unless all the features are exactly collinear and exactly equally spaced.
Regex Model Score
For Blue Read tool, a model score (model match score) is a combination of two things:
-
The average score of the features in this model
-
The "geometry score" based on the geometrical arrangement of the features in this model
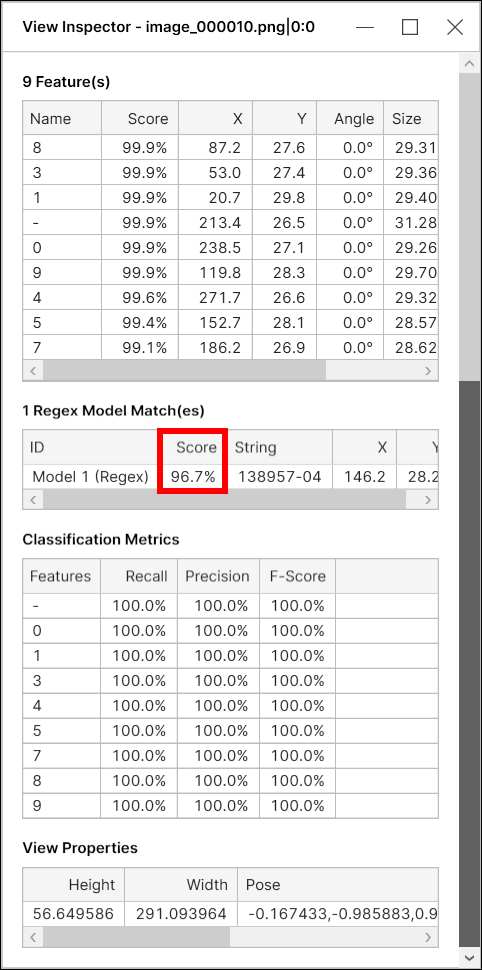
As the geometrical arrangement is included in the calculation of the overall model match score, the model score could be less than 100% even when all the features have a perfect score of 100%, given that the geometry score is less than 100%.
For the regex model, the "geometry score" is based on a combination of:
-
how close the feature positions are to lying on a single line
-
how equally the characters are spaced
For example, with a regex model, given 3 features of score 100%, the overall match score will be slightly less than 100% as the geometry score of this model is less than 100%. The geometry score will always be less than 100% unless all the features are exactly collinear and exactly equally spaced.