ワークスペース、ストリーム、ツール
ワークスペース、ストリーム、ツールは、VisionPro Deep Learning の基本です。
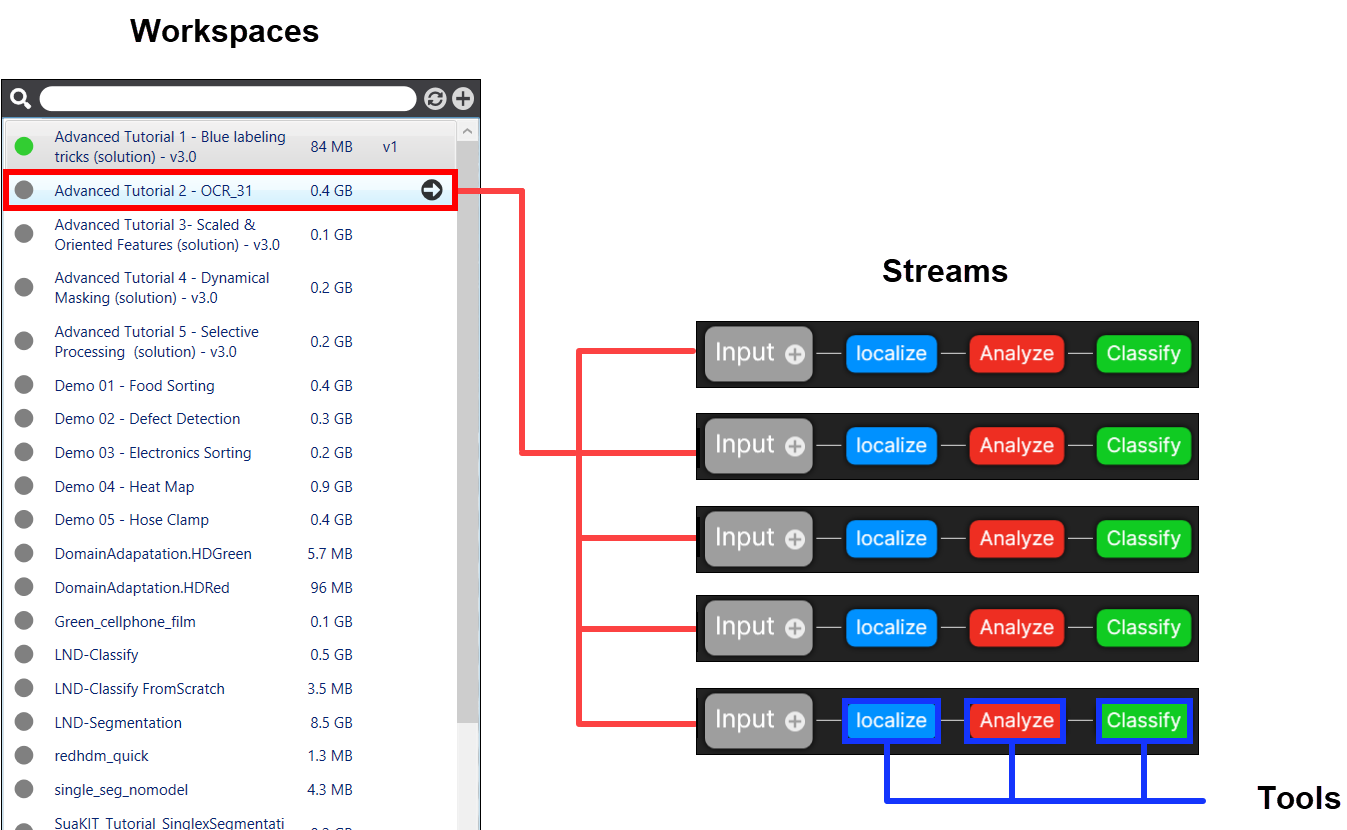
VisionPro Deep Learning ワークスペース
ワークスペースには、アプリケーションの解決に必要な一連のツールおよび画像データベースがすべて含まれています。
- ワークスペースは、ストリームのコレクションに分けられます。
- 各ストリームには、独自の学習画像のデータベース (さまざまな学習セット) およびツールのコレクションがあり、個別に動作します。
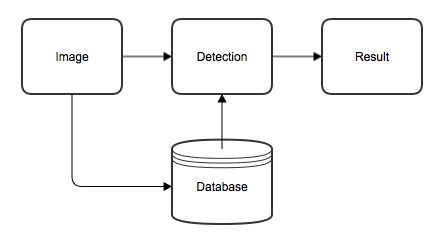
ワークスペースは、特定の検査アプリケーションに関連するすべての情報を保持する基本的なコンテナです。具体的には、次の図に示されるすべてのコンポーネントが含まれています。
-
画像
検査アプリケーションは、画像セットに基づいて定義されます。パラメータ化してツールを学習させ、後で処理します。
-
検出
画像は、1 つまたは複数の Deep Learning ツールによって処理されます。一連のツールの場合は、後続のツールでさらに処理するために、前のツールの結果を使用して画像で特定の矩形のビューを選択してトリミングします。
-
データベース
Deep Learning ツールはすべて学習に基づいているため、ラベル付き画像の学習データベースが必要です。ツールはすべて同じ画像セットで学習しますが、対象領域 (ビュー) およびラベル付けはツールによって異なります。
-
結果
さまざまなツールによって実行された解析の結果がマーキングであり、処理された画像/ビューにオーバレイとして表示できます。
ランタイムワークスペース
ランタイムワークスペースは、画像またはデータベースを含まない設定ファイルであり、ストリームとツールのみを含んでいるため、完全なワークスペースの小型バージョンとなっています。この設定ファイルは、解析を実行する目的でライブラリに読み込むことができます。ランタイム環境の詳細については、「環境」を参照してください。
VisionPro Deep Learning ストリーム
VisionPro Deep Learning 内のストリームは、学習画像のデータベース、およびその画像データベースで動作する Deep Learning ツールのコレクションとして定義されています。これによって、アプリケーションに対して単一のワークスペースを用意し、ワークスペースに流れるデータのストリームを変更するだけで済むようになります。
各ワークスペースは、少なくとも 1 つの処理ストリーム (「デフォルト」のストリーム) を保持できます。このストリームは一連のツールを保持できます。特定の検査アプリケーションが同じオブジェクトの複数の異なるビューによって個々の処理を行う必要がある場合は、ストリームの概念を利用することで、同じワークスペースのもとにこれらの異なる処理チェーンをまとめることができます。
VisionPro Deep Learning ツール
「Cognex VisionPro Deep Learning™ とは とは」で説明したように、各 VisionPro Deep Learning ツールは、ディープニューラルネットワークです。各ツールは、ディープラーニングを通じてプログラミングが困難なさまざまな課題を解決するマシンビジョンツールです。各ツールの 1 つ以上のインスタンスを作成できるため、多数のニューラルネットワークを作成し、1 つのプロジェクトでそれらを学習させることができます。たとえば、一連の画像から欠陥を検出するために、複数の 解析 (赤) ツールを作成し、それぞれに異なるニューラルネットワークパラメータ設定を割り当てることができます。
ツールは共通のエンジンを使用しますが、画像内で探索する対象が異なります。具体的には、各ツールに異なるフォーカスがあり、1 つのポイント、個々の領域、または画像全体のいずれかを解析します。
位置決め (青)
位置決め (青)
 は、画像内で 1 つまたは複数の特徴を検出して位置決めするために使用します。注釈付きの画像から学習することで、ノイズの多い背景上の小さな特徴から複雑なオブジェクトまでまとめて、複雑な特徴やオブジェクトを位置決めして識別できます。位置決め (青) ツールを学習させるには、対象となる特徴がマーキングされた画像を準備するだけです。
は、画像内で 1 つまたは複数の特徴を検出して位置決めするために使用します。注釈付きの画像から学習することで、ノイズの多い背景上の小さな特徴から複雑なオブジェクトまでまとめて、複雑な特徴やオブジェクトを位置決めして識別できます。位置決め (青) ツールを学習させるには、対象となる特徴がマーキングされた画像を準備するだけです。
読み取り (青)
読み取り (青)
 は、画像内で光学文字認識 (OCR) を実行するために使用されます。注釈付きの画像から学習することで、きれいに印刷された文字から非常にノイズの多い背景上にある形が大きく崩れた文字まで、文字を識別して読み取ることができます。読み取り (青) ツールを学習させるには、対象となる文字がマーキングされた画像を準備するだけです。
は、画像内で光学文字認識 (OCR) を実行するために使用されます。注釈付きの画像から学習することで、きれいに印刷された文字から非常にノイズの多い背景上にある形が大きく崩れた文字まで、文字を識別して読み取ることができます。読み取り (青) ツールを学習させるには、対象となる文字がマーキングされた画像を準備するだけです。
解析 (赤)
解析 (赤)  を使用すると、2 種類の欠陥検出タスクを実行できます。
を使用すると、2 種類の欠陥検出タスクを実行できます。
-
異常/欠陥検出 (アンスーパーバイズドモード)
-
セグメンテーション (スーパーバイズドモード)
これら 2 つの操作モードは、2 種類の欠陥検出の違いを表しています。異常/欠陥検出では、解析 (赤) フォーカスアンスーパーバイズド は通常の欠陥のないビューのみで学習し、テストデータセット内の新しいビューについて、それらにどの程度欠陥があるかを判断します。通常の欠陥のないすべてのビューが「良好」ラベルが付いた画像であり、最終的にはラベルが不要であることを意味するため、これは、アンスーパーバイズドラーニングまたはアンスーパーバイズド学習となります。セグメンテーションについては、解析 (赤) フォーカススーパーバイズドおよび解析 (赤) High Detailは、通常のビューと欠陥のあるビューの両方で学習し、テストデータセット内の新しいビューについて、欠陥があるかどうか、また、各欠陥ビューの欠陥の位置について判断します。これは、学習済みのビューに「良好」または「不良」というラベルが付けられるため、スーパーバイズドラーニングまたはスーパーバイズド学習となります。
2 つのモードは、パフォーマンスと要件において互いに補完し合うため、両方を組み合わせて使用できます。たとえば、最初にアンスーパーバイズド (解析 (赤) フォーカスアンスーパーバイズド) ツールで目に見える異常をフィルタ処理した後で、スーパーバイズド (解析 (赤) フォーカススーパーバイズド、解析 (赤) High Detail、) ツールを 1 回以上使用して、傷、低コントラストの汚れ、テクスチャの変化などの、見分けにくい特定の欠陥を検出できます。
| 課題 | アンスーパーバイズドモード | スーパーバイズドモード |
|---|---|---|
| 予期しない欠陥を検出する | 可能性あり | 可能性少 |
| 欠陥サンプルが必要 | いいえ | はい |
| パーツの設定とバリエーションに対する感度 | 強い | 弱い |
| 傷、亀裂、割れ目などの線状の欠陥を検出する | 困難 | 簡単 |
| 特定の欠陥タイプを検出する | 不可能 | 可能 |
| 測定可能な欠陥パラメータ (位置と明度の隣) | なし | サイズ、形状 |
解析 (赤)に使用されるニューラルネットワークのアーキテクチャには 2 種類あります。
-
フォーカス
-
High Detail
各モードで使用されるアーキテクチャが異なるため、ツールパラメータオプションにいくつかの違いがあります。High Detail モードとフォーカスモードは使用するアーキテクチャが互いに異なるため、ツールパラメータオプションに違いがあります。また、アーキテクチャの違いにより、学習/処理の結果とそれらに要する時間は異なります。
分類 (緑)
分類 (緑)
 は、その高速かつ正確な画像分類で知られており、非常に要求の厳しい分類環境に悩むさまざまな分野の多くのお客様に広く採用されています。分類 (緑) ツールは、画像におけるオブジェクトまたはシーン全体を識別して分類するために使用されます。オブジェクトをソートしたり、さらに解析をしたりするために使用することもできます。分類 (緑) ツールを学習させたら、画像にタグを割り当てます。ツールはそのタグを使用して、画像にクラスを割り当てます。タグはラベルで表示され、ツールが割り当てた分類に対する確実性が割合で表示されます。
は、その高速かつ正確な画像分類で知られており、非常に要求の厳しい分類環境に悩むさまざまな分野の多くのお客様に広く採用されています。分類 (緑) ツールは、画像におけるオブジェクトまたはシーン全体を識別して分類するために使用されます。オブジェクトをソートしたり、さらに解析をしたりするために使用することもできます。分類 (緑) ツールを学習させたら、画像にタグを割り当てます。ツールはそのタグを使用して、画像にクラスを割り当てます。タグはラベルで表示され、ツールが割り当てた分類に対する確実性が割合で表示されます。
次の方法でツールの分類機能を使用することができます。
- パート A、パート B、パート C など、画像のオブジェクトを分類するために使用できます。また、ゲートツールとして使用することができ、検査を実施する他の後に続くツールの前に使用します。たとえば、分類 (緑) ツールで部品 B であると決定したら、解析 (赤) ツールでさらなる検査を実行し、部品 C であった場合は、位置決め (青) ツールで特徴の数をカウントします。
- 解析 (赤) ツールのダウンストリームを使用して、検出された欠陥のタイプを分類したり、位置決め (青) ツールの後で、特定のビューを生成したモデルのタイプを分類したりすることができます。
ツールを使用するには、「学習画像セット」を提供し、適切なラベルを使用して画像にタグ付けします。画像にタグ付けしたら、ツールを学習させます。次に、学習中に使用されなかった画像を使用してツールを検証します。
分類 (緑)に使用されるニューラルネットワークのアーキテクチャには 3 種類あります。
-
フォーカス
-
High Detail
-
High Detail Quick
各モードで使用されるアーキテクチャが異なるため、ツールパラメータオプションにいくつかの違いがあります。High Detail モードとフォーカスモードは使用するアーキテクチャが互いに異なるため、ツールパラメータオプションに違いがあります。また、アーキテクチャの違いにより、学習/処理の結果とそれらに要する時間は異なります。High Detail Quick モードは基本的に High Detail モードと同様のアーキテクチャを共有していますが、学習フェーズに検証ステップがなく、High Detail モードよりもはるかに短時間で結果を生成します。
VisionPro Deep Learning ツール使用の基本ステップ
VisionPro Deep Learning のツールを使用するための共通の基本ステップを説明します。
-
画像を収集し、VisionPro Deep Learning に読み込みます。
-
解決する特定のマシンビジョンの問題に対応するツールを選択します。
-
各画像を確認し、目的の欠陥/特徴/クラスに慎重にラベルを付けます。
-
画像を学習に使用する学習セットと、ツールの学習に使用しないテストセットに分割します。
-
ツールパラメータを編集します。
-
ツールを学習させ、結果を確認します。
-
テストセット画像を提示することで、ツールの結果を確認します。
-
ツールをエクスポートし、ランタイム環境に展開します。
アーキテクチャの詳細: フォーカス
フォーカス VisionPro Deep Learning ツールは、特定の領域ごとに重要な画像ピクセル情報をサンプリングする特徴のサンプラーを使用します。そのサイズとサンプリング密度はユーザ定義です。次に、ツールはこの情報を使用して、指定したラベルと、ビジョンの問題で正しい決定を下すために重要な特徴について学習します。一般に、フォーカス ツールは High Detail ツールより高速ですが、精度は低くなります。
フォーカス アーキテクチャの VisionPro Deep Learning ツール
アーキテクチャの詳細: High Detail
High Detail VisionPro Deep Learning ツールは、画像のビュー全体から画像ピクセルをサンプリングするため、画像ピクセル情報を取得する際に特定の領域ベースのサンプラーを使用することはありません。フォーカス ツールと同様に、ツールはこの情報を使用して、指定したラベルと、ビジョンの問題で正しい決定を下すために重要な特徴について学習します。一般に、High Detail ツールは フォーカス ツールより低速ですが、精度は高くなります。
High Detail アーキテクチャの VisionPro Deep Learning ツール
アーキテクチャの詳細: High Detail Quick
High Detail ツールと同様に、High Detail Quick VisionPro Deep Learning ツールは、画像のビュー全体から画像ピクセルをサンプリングするため、画像ピクセル情報を取得する際に特定の領域ベースのサンプラーを使用することはありません。しかし、High Detail Quick ツールは High Detail ツールとは異なり、速度重視の学習アルゴリズムを採用しているため、一般的に High Detail ツールよりはるかに高速ですが、精度は若干低くなります。
High Detail Quick アーキテクチャの VisionPro Deep Learning ツール: