Workspace, Stream, Tool
Workspace, Stream, and Tool are the basis of VisionPro Deep Learning.

VisionPro Deep Learning Workspace
A workspace contains all the sets of tools and image databases necessary to solve an application.
- A workspace is divided into a collection of streams.
- Each stream has it own database of training images (different training sets), contains a collection of tools and operates separately
A workspace is the basic container which holds all the relevant information about a specific inspection application. More concretely, this includes all the components shown in the following diagram:
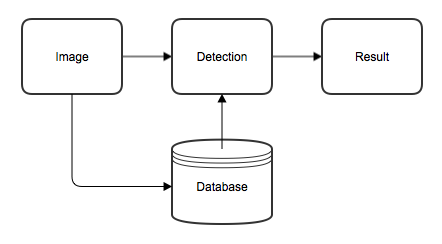
-
Image
An inspection application is defined around a set of images; first to parametrize and train the tools, then later for processing.
-
Detection
The images are processed by one or more Deep Learning tools. For a sequence of tools, the result of the previous tool is used to select and crop a specific rectangular view in the image to be further processed by the subsequent tool.
-
Database
Since all Deep Learning tools are learning-based, they need a labeled training database of images. While all tools train on the same set of images, the regions of interests (Views), as well as the labeling, are tool specific.
-
Result
The result of the analysis performed by the different tools is a marking, which can be shown as an overlay on the processed image/view.
Runtime Workspace
A runtime workspace is a configuration file that does not contain images or databases, containing only streams and tools, which makes it a smaller version of a full Workspace. This configuration file can be loaded in the library in order to perform some analysis. For the details of the runtime environment, see Environments.
VisionPro Deep Learning Stream
A stream within VisionPro Deep Learning is defined as a database of training images and a collection of Deep Learning tools that operate on that database of images. This allows you to have a single workspace for your application, and simply change the stream of data flowing into the workspace.
Every workspace holds at least one processing stream (the "default" stream) which can hold a sequence of tools. If a particular inspection application entails multiple but different views of the same object, requiring individual treatment, the concept of streams allows to group these different processing chains under the same workspace.
VisionPro Deep Learning Tool
As Illustrated in What is Cognex VisionPro Deep Learning™, each VisionPro Deep Learning tool is a deep neural network. Each tool is a machine vision tool which tackle different hard to program challenges through the use of deep learning. You can create 1 or more instances of each tool, so you can create many neural networks and train them in a single project. For example, to catch defects from a set of images, you can create multiple Red Analyze tools, each assigned with different neural network parameter settings.
While the tools share a common engine, they differ in what they are looking for in images. More specifically, each tool has a different focus analyzing either single points, individual regions or complete images:
Blue Locate
The Blue Locate is used to find and localize single or multiple features within an image. From small features on noisy backgrounds to complex objects in bulk; the Blue Locate tool can localize and identify complex features and objects by learning from annotated images. To train the Blue Locate tool, all you need to provide are images where the targeted features are marked.
is used to find and localize single or multiple features within an image. From small features on noisy backgrounds to complex objects in bulk; the Blue Locate tool can localize and identify complex features and objects by learning from annotated images. To train the Blue Locate tool, all you need to provide are images where the targeted features are marked.
Blue Read
The Blue Read is used to perform Optical Character Recognition (OCR) within an image. From cleanly printed characters to strongly deformed characters on very noisy backgrounds, the Blue Read tool can identify and read characters by learning from annotated images. To train the Blue Read tool, all you need to provide are images where the targeted characters are marked.
is used to perform Optical Character Recognition (OCR) within an image. From cleanly printed characters to strongly deformed characters on very noisy backgrounds, the Blue Read tool can identify and read characters by learning from annotated images. To train the Blue Read tool, all you need to provide are images where the targeted characters are marked.
Red Analyze
The Red Analyze is used to perform two types of defect detection tasks.
is used to perform two types of defect detection tasks.
-
Anomaly/Defect Detection (Unsupervised Mode)
-
Segmentation (Supervised Mode)
These two different modes of operation stand for the differences that can exist between the two types of defect detection. For Anomaly/Defect Detection, Red Analyze Focused Unsupervised is trained only with normal, defect-free views, and then makes decisions for new views in the test data set about how much they are defective. This is unsupervised learning or unsupervised training because every normal, defect-free view is an image with the "Good" label, which eventually means that they do not need any label. For Segmentation, Red Analyze Focused Supervised and Red Analyze High Detail are trained with both normal and defective views, and then makes decisions for new views in the test data set whether they have defects or not, and for the location of the defects for each defective view. This is supervised learning or supervised training because the views trained are labeled as "Good" or "Bad."
The two modes are complementary, in terms of their performance and requirements, and can be used in combination. For example, an Unsupervised (Red Analyze Focused Unsupervised) tool could be used to first filter the visual anomalies, and one or more subsequent Supervised tools (Red Analyze Focused Supervised, Red Analyze High Detail) would be used to find specific and visually difficult to discern defects like scratches, low contrast stains or texture changes.
| Challenge | Unsupervised Mode | Supervised Mode |
|---|---|---|
| Finds unforeseen defects | Likely | Hardly |
| Requires defect samples | No | Yes |
| Sensitivity to part configurations and variations | Strong | Weak |
| Detects line-type defects like scratches, cracks or fissures | Difficult | Easy |
| Detects specific defect-types | No | Possible |
| Measurable defect parameters (next to position and intensity) | None | Size, shape |
There are 2 types of neural network architecture used for Red Analyze.
-
Focused
-
High Detail
Each mode uses different architectures, so there are some differences in tool parameter options. High Detail mode and Focused mode use different architecture from each other, so there are differences in tool parameter options. And because of the different architecture, the results and time spent for training/processing are different.
Green Classify
The Green Classify has been well-known for its fast and accurate image classification and widely adopted by many clients from countless fields that suffer from highly demanding classification environments. The Green Classify tool is used to identify and classify an object, or the entire scene, in an image. It can also be used to sort objects or gate further analysis. Once a Green Classify tool has been trained, it will assign a tag to the image, which the tool uses to assign a class to an image. The tag is represented by a label, and is given a percentage declaring the certainty the tool has for the classification it has assigned.
has been well-known for its fast and accurate image classification and widely adopted by many clients from countless fields that suffer from highly demanding classification environments. The Green Classify tool is used to identify and classify an object, or the entire scene, in an image. It can also be used to sort objects or gate further analysis. Once a Green Classify tool has been trained, it will assign a tag to the image, which the tool uses to assign a class to an image. The tag is represented by a label, and is given a percentage declaring the certainty the tool has for the classification it has assigned.
There are a few ways the tool's classification capabilities can be used:
- It can be used to simply classify an object in an image, such as Part A, Part B, Part C, etc. In addition, it can be used as a gating tool, where it is used prior to other tools performing inspections downstream. For example, the Green Classify tool determines that it is Part B, which has a Red Analyze tool that performs further inspection, whereas if it was Part C, a Blue Locate tool would count features.
- It can be used downstream of a Red Analyze tool to classify the types of defects that were encountered, or after a Blue Locate tool to classify the type of Model that produced a particular View.
To use the tool, you provide a Training Image Set and then tag the images with an appropriate label. Once the images are labeled, train the tool. Then validate the tool by using images that were not used during training.
There are 3 types of neural network architecture used for Green Classify.
-
Focused
-
High Detail
-
High Detail Quick
Each mode uses different architectures, so there are some differences in tool parameter options. High Detail mode and Focused mode use different architecture from each other, so there are differences in tool parameter options. And because of the different architecture, the results and time spent for training/processing are different. High Detail Quick mode basically shares a similar architecture with High Detail mode but it doesn't have the validation step in training phase and produces results much more quickly than High Detail mode.
Basic Steps of VisionPro Deep Learning Tool Utilization
Here are the common basic steps for utilizing a tool in VisionPro Deep Learning
-
Collect images, load them into VisionPro Deep Learning.
-
Choose a tool corresponding to your specific machine vision problem to solve.
-
Go through each image and carefully label the defects/features/classes you are looking for.
-
Split images into training set, which are used for training, and test set, which are not used for training the tool.
-
Edit tool parameters.
-
Train the tool and check the result.
-
Review the results of the tool by presenting test set images.
-
Export the tool and deploy it on a runtime environment.
Architecture Details: Focused
Focused VisionPro Deep Learning tools use a feature sampler which samples important image pixel information by specific region, whose size and the density of sampling is user-defined. Then they use this information to learn about the labels you put on and the features critical to making correct decision in your vision problem. Generally, Focused tools are faster than High Detail tools but less accurate.
VisionPro Deep Learning tools of Focused architecture:
Architecture Details: High Detail
High Detail VisionPro Deep Learning tools sample image pixels from the entire view of an image, so it does not use a specific region-based sampler to acquire image pixel information. Like Focused tools, they use this information to learn about the labels you put on and the features critical to making correct decision in your vision problem. Generally, High Detail tools are slower than Focused tools but much more accurate.
VisionPro Deep Learning tools of High Detail architecture:
Architecture Details: High Detail Quick
Like High Detail, High Detail Quick VisionPro Deep Learning tools sample image pixels from the entire view of an image, so it does not use a specific region-based sampler to acquire image pixel information. But, High Detail Quick tools are different from High Detail tools as they adopt speed-oriented training algorithms and thus generally are much faster than High Detail tools with some loss in accuracy.
VisionPro Deep Learning tool of High Detail Quick architecture: